Home » Student Resources » Online Chemistry Textbooks » CH105: Consumer Chemistry » CH105: Chapter 5 – Introduction to Organic Chemistry
MenuCH105: Consumer Chemistry
Chapter 5 – Introduction to Organic Chemistry
This content can also be downloaded as Interactive PDF. For the interactive PDF, adobe reader is required for full functionality.
This text is published under creative commons licensing, for referencing and adaptation, please click here.
Sections:
5.1 Pain, pleasure, and organic chemistry
5.2 Drawing organic molecules
Finding the Best Lewis Structure
5.3 Different Representations of Organic Molecules
Molecular formulae
Structural formulae and 3-dimensional models
Skeletal or line formulae
Drawing abbreviated organic structure
5.4 Stereoisomers, Enantiomers, and Chirality
Chirality
Thalidomide – A Story of Unintended Consequences
5.5 The Importance of Chirality in Protein Interactions
5.6 Recognizing Common Organic Functional Groups
Alkanes
Alkenes and Alkynes
Aromatics
Alkyl Halides
Alcohols, Phenols, and Thiols
Ethers and Sulfides
Amines
Organic Phosphates
Aldehydes and Ketones
Carboxylic Acids and Their Derivatives
Nitriles
Practice Recognizing Functional Groups in Molecules
5.7 A Brief Overview of Organic Nomenclature
5.8 References
5.1 Pain, pleasure, and organic chemistry

Habanero peppers (credit: https://www.flickr.com/photos/jeffreyww/)
It’s a hot August evening at a park in the middle of North Hudson, Wisconsin, a village of just under 4000 people on the St. Croix river in the western edge of the state. A line of people are seated at tables set up inside a canvas tent. In front of a cheering crowd of friends, family, and neighbors, these brave souls are about to do battle . . .with a fruit plate.
Unfortunately for the contestants, the fruit in question is the habanero, one of the hotter varieties of chili pepper commonly found in markets in North America. In this particular event, teams of five people will race to be the first to eat a full pound of peppers. As the eating begins, all seems well at first. Within thirty seconds, though, what begins to happen is completely predictable and understandable to anyone who has ever mistakenly poured a little too much hot sauce on the dinner plate.
Faces turn red, sweat and tears begin to flow, and a copious amount of cold water is gulped down.
Although technically the contestants are competing against each other, the real opponent in this contest – the cause of all the pain and suffering – is the chemical compound ‘capsaicin’, the source of the heat in hot chili peppers.
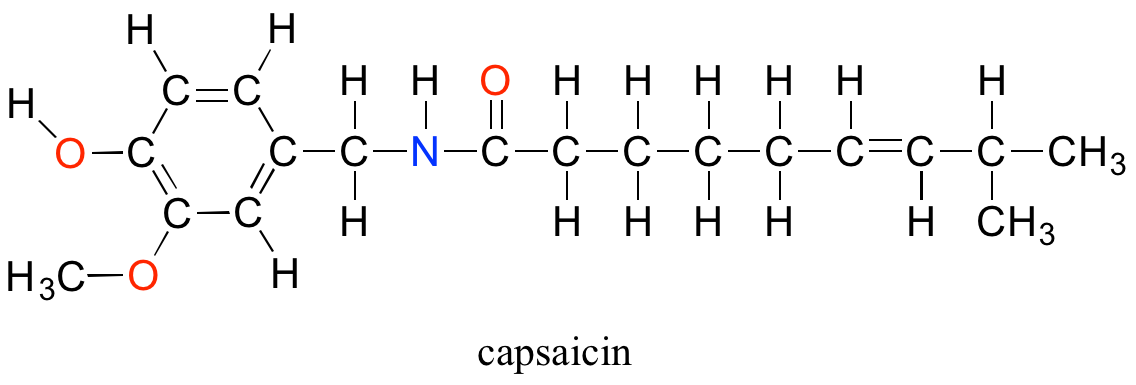
Composed of the four elements carbon, hydrogen, oxygen and nitrogen, capsaicin is produced by the pepper plant for the purpose of warding off hungry mammals. The molecule binds to and activates a mammalian receptor protein called TrpV1, which in normal circumstances has the job of detecting high temperatures and sending a signal to the brain – ‘it’s hot, stay away!’ This strategy works quite well on all mammalian species except one: we humans (some of us, at least) appear to be alone in our tendency to actually seek out the burn of the hot pepper in our food.
Interestingly, birds also have a heat receptor protein which is very similar to the TrpV1 receptor in mammals, but birds are not at all sensitive to capsaicin. There is an evolutionary logic to this: it is to the pepper’s advantage to be eaten by a bird rather than a mammal, because a bird can spread the pepper seeds over a much wider area. The region of the receptor which is responsible for capsaicin sensitivity appears to be quite specific. In 2002, scientists were able to insert a small segment of the (capsaicin-sensitive) rat TrpV1 receptor gene into the non-sensitive chicken version of the gene, and the resulting chimeric (mixed species) receptor was sensitive to capsaicin (Cell 2002, 108, 421).
Back at the North Hudson Pepperfest, those with a little more common sense are foregoing the painful effects of capsaicin overload and are instead indulging in more pleasant chemical phenomena. A little girl enjoying an ice cream cone is responding in part to the chemical action of another organic compound called vanillin.
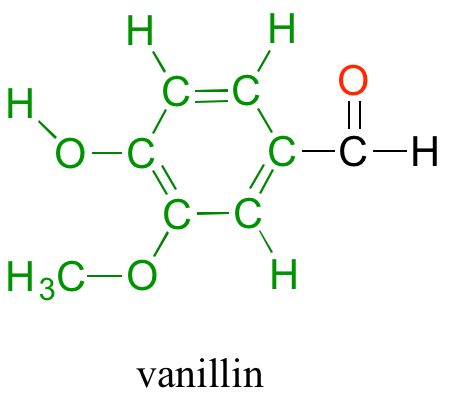
What is it about capsaicin and vanillin that causes these two compounds to have such dramatically different effects on our sensory perceptions? Both are produced by plants, and both are composed of the elements carbon, hydrogen, oxygen, and (in the case of capsaicin) nitrogen. Since the birth of chemistry as a science, chemists have been fascinated – and for much of that history, mystified – by the myriad properties of compounds that come from living things. The term ‘organic’, from the Greek organikos, was applied to these compounds, and it was thought that they contained some kind of ‘vital force’ which set them apart from ‘inorganic’ compounds such as minerals, salts, and metals, and which allowed them to operate by a completely different set of chemical principles. How else but through the action of a ‘vital force’ could such a small subgroup of the elements combine to form compounds with so many different properties?
Today, as you are probably already aware, the term ‘organic,’ – when applied to chemistry – refers not just to molecules from living things, but to all compounds containing the element carbon, regardless of origin. Beginning early in the 19th century, as chemists learned through careful experimentation about the composition and properties of ‘organic’ compounds such as fatty acids, acetic acid and urea, and even figured out how to synthesize some of them starting with exclusively ‘inorganic’ components, they began to realize that the ‘vital force’ concept was not valid, and that the properties of both organic and inorganic molecules could in fact be understood using the same fundamental chemical principles.
They also began to more fully appreciate the unique features of the element carbon which makes it so central to the chemistry of living things, to the extent that it warrants its own subfield of chemistry. Carbon forms four stable bonds, either to other carbon atoms or to hydrogen, oxygen, nitrogen, sulfur, phosphorus, or a halogen. The characteristic bonding modes of carbon allow it to serve as a skeleton, or framework, for building large, complex molecules that incorporate chains, branches and ring structures.
Although ‘organic chemistry’ no longer means exclusively the study of compounds from living things, it is nonetheless the desire to understand and influence the chemistry of life that drives much of the work of organic chemists, whether the goal is to learn something fundamentally new about the reactivity of a carbon-oxygen bond, to discover a new laboratory method that could be used to synthesize a life-saving drug, or to better understand the intricate chemical dance that goes on in the active site of an enzyme or receptor protein. Although humans have been eating hot peppers and vanilla-flavored foods for centuries, we are just now, in the past few decades, beginning to understand how and why one causes searing pain and the other pure gustatory pleasure. We understand that the precise geometric arrangement of the four elements in capsaicin allows it to fit inside the binding pocket of the TrpVI heat receptor, but as of today, we do not yet have a detailed three dimensional picture of the TrpVI protein bound to capsaicin. We also know that the different arrangement of carbon, hydrogen and oxygen atoms in vanillin allows it to bind to specific olfactory receptors, but again, there is much yet to be discovered about exactly how this happens.
In this chapter, you will be introduced to some of the most fundamental principles of organic chemistry. With the concepts we learn about, we can begin to understand how carbon and a very small number of other elements in the periodic table can combine in predictable ways to produce a virtually limitless chemical repertoire.
As you read through, you will recognize that the chapter contains a lot of review of topics you have probably learned already in an introductory chemistry course, but there will likely also be a few concepts that are new to you, as well as some topics which are already familiar to you but covered at a greater depth and with more of an emphasis on biologically relevant organic compounds.
We will begin with a reminder of how chemists depict bonding in organic molecules with the ‘Lewis structure’ drawing convention, focusing on the concept of ‘formal charge’. We will review the common bonding patterns of the six elements necessary for all forms of life on earth – carbon, hydrogen, nitrogen, oxygen, sulfur, and phosphorus – plus the halogens (fluorine, chlorine, bromine, and iodine). We’ll then continue on with some of the basic skills involved in drawing and talking about organic molecules: understanding the ‘line structure’ drawing convention and other useful ways to abbreviate and simplify structural drawings, learning about functional groups and isomers, and looking at how to systematically name simple organic molecules. Finally, we’ll bring it all together with a review of the structures of the most important classes of biological molecules – lipids, carbohydrates, proteins, and nucleic acids – which we will be referring to constantly throughout the rest of the book.
5.2 Drawing organic molecules
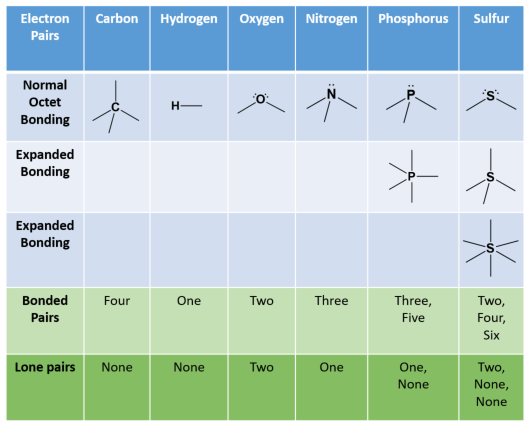
As observed in the molecules capsaicin and vanillin above, the most common atoms found in organic compounds are carbon and hydrogen. Other atoms that routinely form covalent bonds within organic structures also include oxygen, nitrogen, sulfur and phosphorus. More rarely, halogens such as chlorine, bromine and iodine can also be incorporated into organic molecules. Recall from chapter 4, that the octet rule helped us determine that carbon routinely makes four covalent bonds, nitrogen and phosphorus each make three, oxygen and sulfur each make two, and the halogens only make one bond. Hydrogen is an exception to the octet rule as it is the smallest element and its valence shell is filled with two electrons. Thus, hydrogen can form one bond with another atom. Sulfur and phosphorus can also have bonding patterns that are exceptions to the octet rule. They both have expanded orbital bonding with phosphorus also routinely forming five covalent bonds, and sulfur being capable of forming either four or six covalent bonds. Table 5.1 provides a graphic representation of these patterns. When you are drawing organic molecules, it is important to pay attention to the bonding rules so that all atoms reach their preferred bonding states.
Table 5.1: Covalent Bonding Patterns of Atoms Commonly Found in Organic Molecules
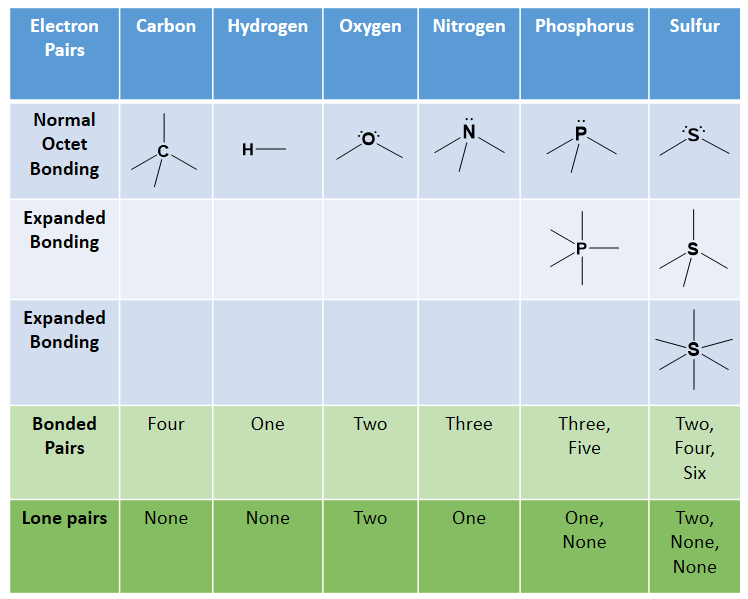
*Note: Hydrogen doesn’t really follow the octet rule as its valence shell is full with 2 e–
Finding the Best Lewis Structure
As we move forward in our study of organic molecules, we find that they become much more complex than the simple ionic and covalent compounds discussed in Chapter 3. Because of this complexity, organic compounds often have more than one specific structural state that they can exist in, and it is not uncommon that a molecule might shift back and forth between these states. When electrons in a molecule can shift from one area of the molecule to another to create these alternative structures. This is defined as resonance, and the resulting states from these shifts as resonance structures. Note that resonance structures give chemists a more concrete way of thinking about molecules. However, the actual molecules don’t exist in one structural state or another. Instead, they exist in a more amorphous transitional state that is somewhere in between all of the possible combinations. Certain resonance forms can be more stable than others and will have more influence on the overall structure of the molecule than other resonance forms. Thus, we need a way to accurately predict what resonance structures are likely to occur within a molecule, and which states will be the most stable. This can be done using the formal charge method of drawing Lewis structures. The formal charge on an atom is calculated as the number of valence electrons of an atom minus the number of electrons an atom ‘owns’. The number of electrons owned by an atom can be calculated by adding the number of unshared electrons + half of the number of shared electrons. Remember that 2e– are shared for every line drawn between two atoms (one line = 2e–). For example, if oxygen is bonded to two other atoms, we would calculate formal charge on the oxygen by subtracting the number of electrons ‘owned’ by the oxygen from its valence shell number of electrons:
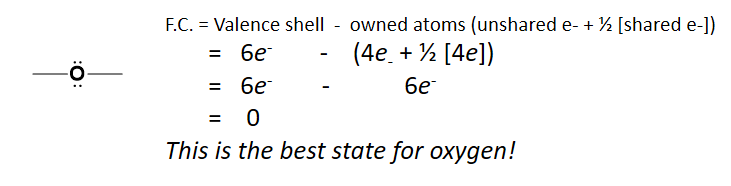
What if oxygen is bonded like this?
![]()
How would you calculate the formal charge?
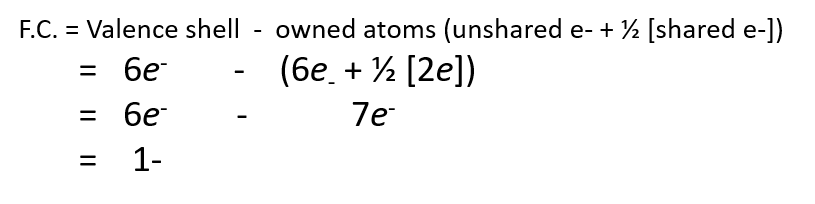
This is not the preferred configuration for oxygen, but because oxygen is so electronegative, it can carry a negative formal charge more easily than atoms with less electronegativity.
Now let’s consider the structure of the phosphate anion (PO43- ). This is the most common form of phosphorus found in all living organisms on the planet, including humans. It is commonly incorporated into organic molecules such as DNA, proteins, and ATP (Adenosine Triphosphate), the energy storehouse of the cell (Figure 5.1).
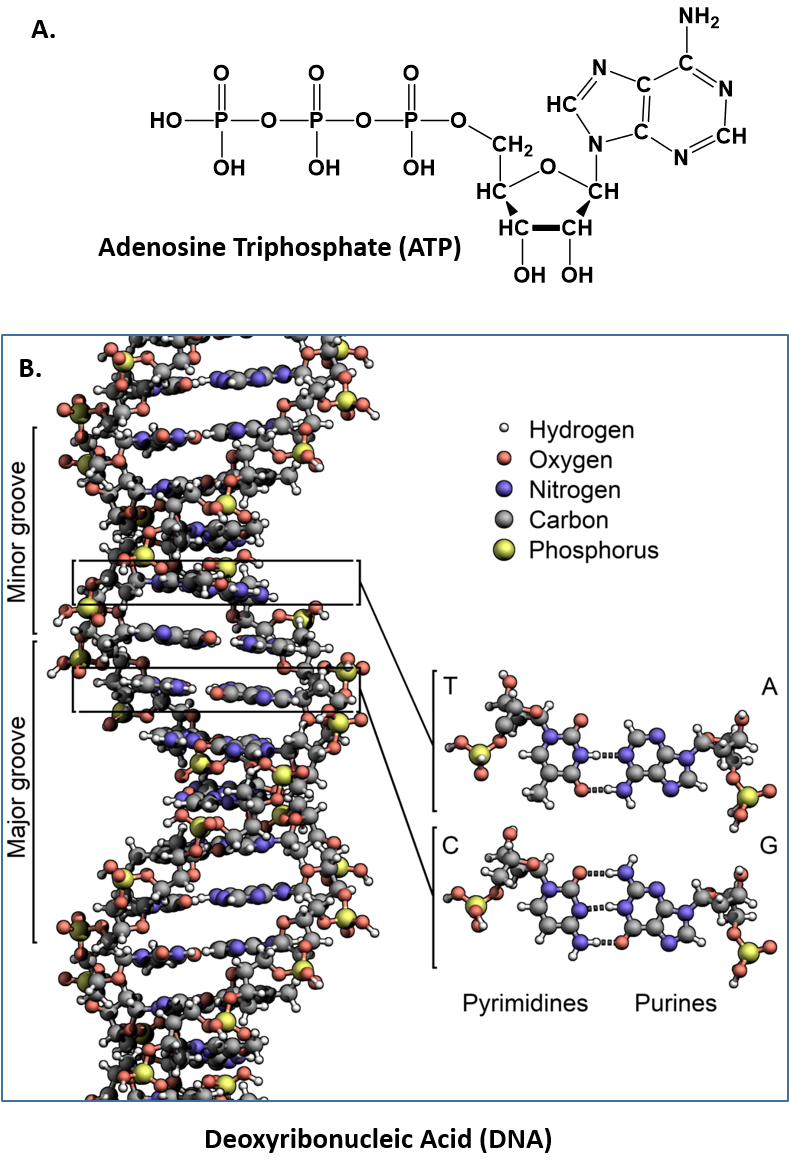
Figure 5.1 Structures of Adenosine Triphosphate (ATP) and Deoxyribonucleic Acid (DNA). The phosphate ion is an important component of both the (A.) ATP structure and the (B.) DNA structure.
Diagram of DNA model provided by: Zephyris – Own work, CC BY-SA 3.0, https://commons.wikimedia.org/w/index.php?curid=15027555
How do we go about drawing the Lewis Structure for the phosphate ion?
(1) Identify the least electronegative element(s) in the molecule. This will be the central atom(s) that the other, more electronegative atoms, are bonded around. (Note that hydrogen can never be a central atom as it can only make one covalent bond).
-
For PO43- list out all the atoms with the phosphorus placed at the center. Also, list any extra electrons due to the negative charge on the overall molecule and your expectations about the bonding capacity of each atom to reach the octet. Note that we have four oxygen atoms that have to bond to the phosphorus. Thus, we would expect P to be in the 5 bond state for this molecule (ie. 3 won’t be enough). Note that the lone pair of electrons in the P is split and each electron is used for the expanded orbital bonding with other atoms.

(2) Count the total number of valence electrons present in the molecule. To do this add up all the valence electrons for each atom present.
- If there is no overall charge on the molecule, this number will represent the total number of valence electrons in the molecule.
- If there is a net negative charge on the molecule, add the additional electrons to the number of valence electrons for all the atoms present to calculate the total number of valence electrons in the molecule. This molecule will exist as an anion.
- If the molecule has a net positive charge, subtract off the total positive charge from the number of valence electrons for all the atoms present and this will represent the total number of valence electrons on the molecule. This molecule will exist as a cation.

(3) Build the shell for the bonded atoms to the central atom(s) and calculate the formal charge(s).
-
Place bonds between the outer atoms and the central atom
-
Add in all remaining electrons to complete the octet/duet rule (or expanded orbitals, if necessary) for the remaining atoms
-
If you run out of electrons before all the atoms have filled valence shells begin making double bonds where necessary
-
Calculate the formal charge on each atom in the molecule and then use the sum to calculate the formal charge on the whole molecule.
Watch the video tutorial above to help you draw out the Lewis structure of phosphate. You will see that you need to start with the center phosphorus. Note that has to use the expanded orbital rule, instead of the octet to be able to bond with all of the oxygen atoms. For phosphorus, we know that it will make 5 bonds in the expanded orbital format (Table 5.1) and require a total of 10 electrons, instead of the normal 8 that we are used to seeing with the octet rule. So start by drawing in those 5 bonds. You’ll notice that you need to make one double bond with one of the oxygens to complete the 5 bonds. After this fill in the lone pair electrons for all of the atoms, until you reach a total of 32 electrons. (be sure that each oxygen reaches the octet state. Next, calculate the formal charges on each atom. As shown above, oxygen that has 2 bonded pairs of electrons and two loan pairs has a formal charge of zero, while oxygens that have one bonded pair of electrons and three lone pairs have a formal charge of 1–. If we calculate the formal charge on the phosphorus, we see that P has 5 valence e- minus the lone pair electrons and half of the bonded pair electrons. The P has no lone pairs and have 10 bonded pair electrons. Thus, half of 10 = 5. 5 – 5 = 0. Thus the P has a formal charge of zero. Since three of the oxygens have a 1– charge and the other two atoms are zero, the overall charge on the molecule is 3–. The completed Lewis structure for phosphate should look like this:
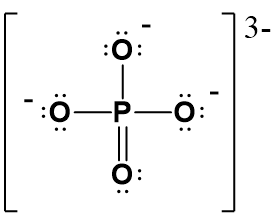
(4) Draw resonance structures as needed.
For our phosphate (PO43-) structure above, if we consider each of the oxygen atoms within the molecule, they are not inherently different from one another. Thus, each oxygen surrounding the phosphorus should have equal opportunity to form the double bonded position. We have shown the double bond forming in the downward position, but it has an equally probable chance of forming with any of the other three oxygens. Thus, we can show the structure with the double bond position in all of the other possible conformations:
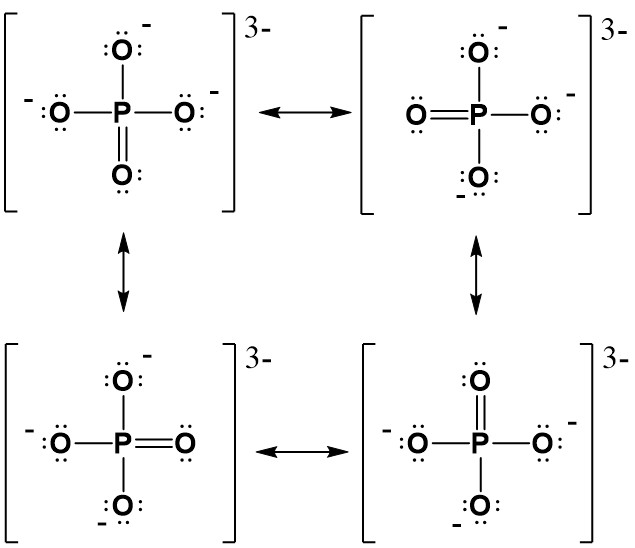
In actuality, none of the resonance structures represent the true structure. The true structure is somewhere in between all of the possible resonance conformations. However, drawing out the resonance structures gives scientists a way to discuss the structure’s true conformation and provides a way to predict the chemical reactivity of the molecule.
5.3 Different Representations of Organic Molecules
Molecular formulae
Organic molecules, compared to the simple salts and covalent compounds shown in Chapters 3 and 4, can be quite large and sprawling structures with many branches. Thus, it is important to understand how to draw organic molecules so that you can understand the 3-dimensional shape of the molecule. A molecular formula is the simplest way to represent a compound by counting up all of the different types of atoms and listing them in order. For example, the sugar glucose, contains 6 carbons, 12 hydrogens, and 6 oxygens. The molecular formula would then be written as C6H12O6. By convention, carbon is listed first, hydrogen second, followed by oxygen, nitrogen, sulfur, phosphorus, and finally any halogens. However, for organic chemistry, molecular formulae don’t provide much information. They simply provide the numbers of each type of atom present in the molecule, but they tell you nothing about the way the atoms are joined together in space. Thus, molecular formulae are very rarely used in organic chemistry, because they do not give useful information about the bonding in the molecule. One of the few places where you might come across them is in equations for the combustion of simple hydrocarbons, for example:
In cases like this, the bonding order in the organic molecule isn’t important. However, for most biologically important reactions, the shape of the molecule is usually critical for the function of the molecule, very similar to a key fitting into a lock. Thus, the bonding order becomes very important. For example, C5H12 shown in the equation above can be bonded together in more than one way:
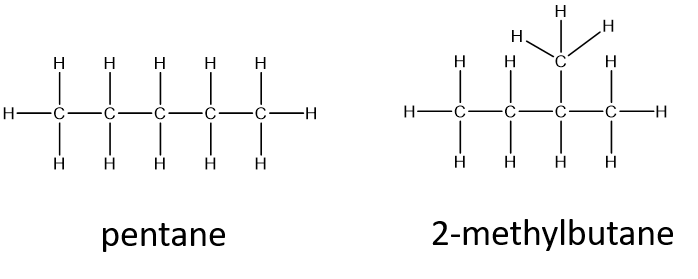
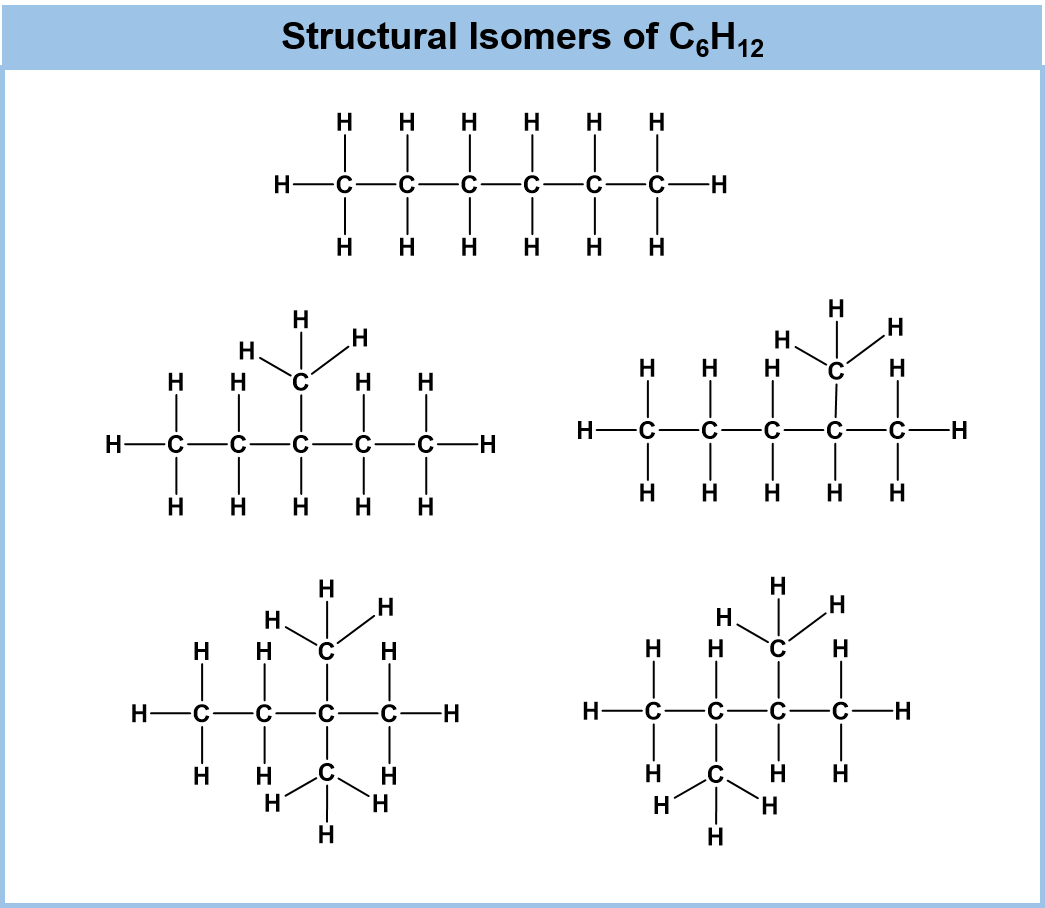
The two structures above all represent valid structures with the molecular formula C5H12. However, each of these structures represents a different molecule with slightly different chemical properties. When compounds share the same molecular formula, but have a different bonding order of the atoms, they are known as structural isomers. (you may also see the term constitutional isomers used as well). Did we list all of the possible structural isomers for the C5H12 formula? No! Use the example below to see if you can create a third structural isomer.

Structural formulae and 3-dimensional models
A structural formula shows how the various atoms are bonded, and can be more useful that only writing the molecular formula for a compound. There are various ways of drawing structural formulae and you will need to be familiar with all of them. They include the displayed formula, condensed formulas, and line structures.
Displayed formulae
A displayed formula shows all the bonds in the molecule as individual lines with each atom written at the end of each line using its elemental abbreviation from the periodic table. The structures of C6H12, above, are all written in displayed formulae. You need to remember that each line represents a pair of shared electrons. For example, figure 5.2 below depicts the displayed formula of methane next to the three-dimensional representations.
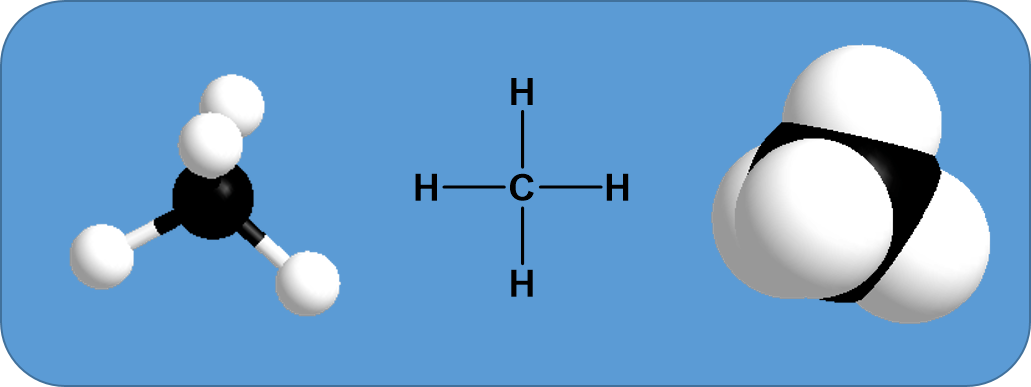
Figure 5.2: Three different representations of CH4 On the left is the ball and stick model, in the center is the displayed formula, and to the right is the space-filling model.
Notice that the displayed formula of methane does not represent the 3-D shape of the molecule shown in the space-filling diagram on the right. Methane isn’t flat with 90° bond angles. This mismatch between what you draw and what the molecule actually looks like can lead to problems if you aren’t careful. Thus, for organic chemistry, it is important to begin thinking about the structures in their 3-D form. The more you practice, the more you will be able to visualize and turn the molecule around in your head. For example, consider the simple molecule with the molecular formula CH2Cl2. You might think that there were two different ways of arranging these atoms if you drew a displayed formula.
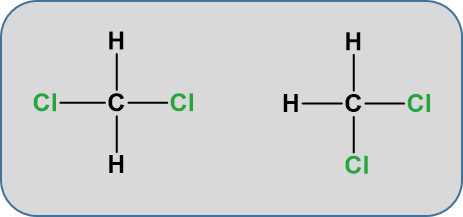
But these two structures are actually exactly the same. Our VSEPR modeling from Chapter 4 showed that carbon takes on a tetrahedral confirmation where each bond angle is 109o. The molecule is not flat, in the plane of the paper. Play the video below to see how they appear as rotating ball and stick models.
One structure is in reality a simple rotation of the other one. Consider a slightly more complicated molecule, C2H5Cl. The displayed formula could be written as either of these:
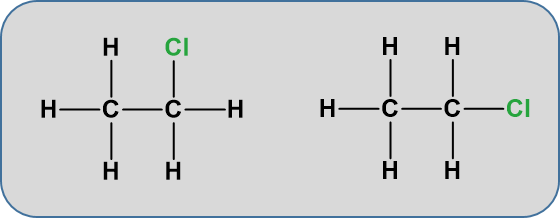
But, again these are exactly the same. Look at the models below.
As you continue to practice drawing out structural formulae, you will become better at recognizing and distinguishing between isomers that are truly different from one another, and versions of the same molecule written drawn from different 3-dimensional perspectives.
Condensed formulae
For anything other than the most simple molecules, drawing a fully displayed formula can be cumbersome and take up too much space – especially all the carbon-hydrogen bonds. You can simplify – or condense – the formula by writing, for example, CH3 or CH2 instead of showing all the C-H bonds. For example, ethanoic (C2H4O2) acid can be shown in a fully displayed form, a partially condensed form and a fully condensed form.
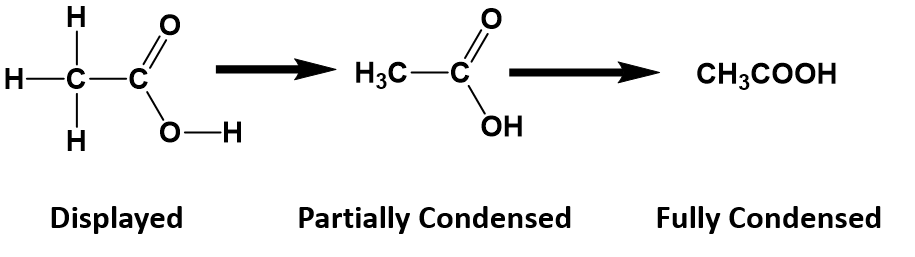
Notice that the partially condensed structure still provides a very clear picture of where each of the atoms is bonded in space. However, with the fully condensed structure, it can be challenging to accurately see the bonding patterns. The fully condensed form does contain more information about bonding order than the molecular formula, such that the atoms that are directly bonded to a neighboring atom are placed adjacent to that atom in the condensed form, rather than a simple tallying of the total atom species as in the molecular formula.
By working backwards, we can use the condensed structure of ethanoic acid as an example to recreate the partially condensed structure. When looking at the first carbon position, it is apparent that there are three hydrogens and one carbon bound to the first carbon:
Note that this satisfies the octet rule for the first carbon (four bonds to other atoms). The three hydrogens are also complete with their single bonds to the first carbon. The second carbon has now been assigned one bond to the first carbon. We need to assign the remaining three bonds.
From the condensed formula, it is clear that the first oxygen is attached to the second carbon, however, after that, we become unsure about the position of the second oxygen.
We can clearly deduce that the last hydrogen atom is bound to the second oxygen, as it is placed in that position. However, because oxygen can form two bonds, we can’t be sure based on the condensed structure alone, that the second oxygen is bound to the second carbon or to the first oxygen.
When you are unsure of which atom is bonded to which, it is best to draw out the potential structures and evaluate them for their potential correctness.
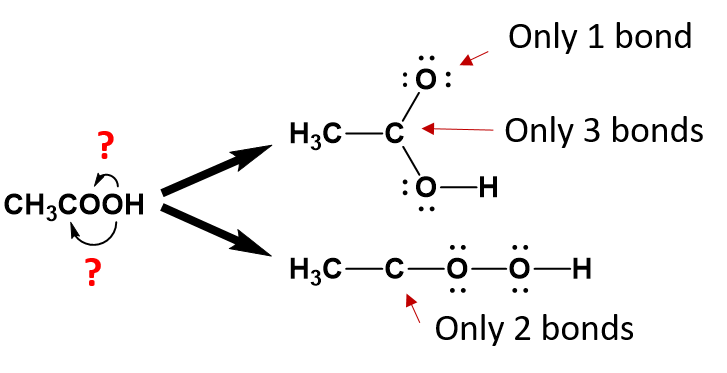
From the analysis of the potential structures above, it is clear that neither structure satisfies the octet rule for one or more atoms within the molecule as currently written. However, the lower structure is less satisfactory than the upper structure, as the second carbon is missing 2 covalent bonds while all of the other atoms have satisfied the octet bonding requirements. In the upper diagram, both the second carbon and the first oxygen atom are lacking one bond. This structure can easily satisfy the octet rule by placing a double bond between carbon 2 and oxygen 1 within the molecule. Whereas, a solution for the missing two carbon bonds for the second carbon in the lower structure is not easily remedied. Thus, the upper structure is a more probable structure than the lower structure with the addition of the double bond between the carbon and the oxygen.
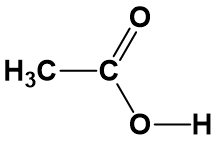
While condensed structures are easier to write than displayed or partially condensed structures they can prove to be a little more challenging to determine the three dimensional bonding pattern of the atoms.
Line or Skeletal Formulae
In a line or skeletal formula, all the hydrogen atoms are not shown and all the carbons are not labeled but rather are indicated at the end or bend in every line, leaving just a carbon skeleton with functional groups attached to it. Any heteroatoms (any other atom than carbon or hydrogen) and hydrogens attached to heteroatoms are shown in condensed form. For example, the displayed structure, partially condensed structure and the line formula for 2-butanol (C4H10O) look like this:
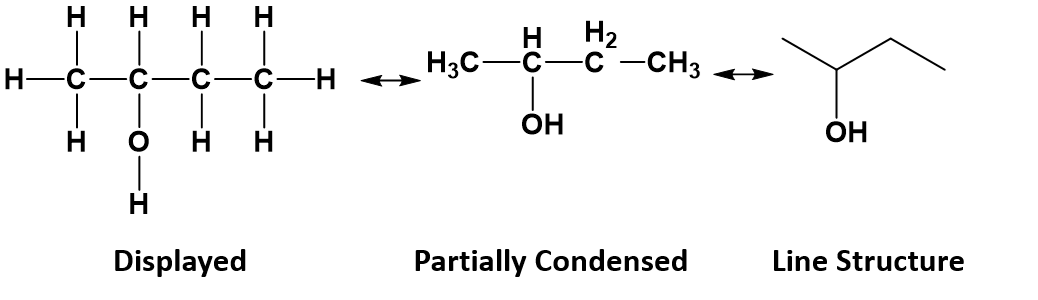
In a line or skeletal diagram, the following assumptions can be made:
-
there is a carbon atom at each line junction and at the end of each line.
-
there are enough hydrogen atoms attached to each carbon to make the total number of bonds on that carbon equal to 4.
-
all heteroatoms (and hydrogens attached to heteroatoms) are shown in condensed format on the skeletal structure.
Within organic chemistry and biochemistry, scientists tend to use a combination of these different formats to represent chemical structures. It is important to become familiar with drawing and interpreting all the different possible representations.
How to draw structural formulae in 3-dimensions
There are occasions when it is important to be able to show the precise 3-D arrangement in parts of some molecules when using a structural representation. To do this, the bonds are shown using conventional symbols:

For example, you might want to show the 3-D arrangement of the groups around the carbon which has the -OH group in 2-butanol.

Drawing abbreviated organic structures
Often when drawing organic structures, chemists find it convenient to use the letter ‘R’ to designate part of a molecule outside of the region of interest. If we just want to refer in general to a functional group without drawing a specific molecule, for example, we can use ‘R groups’ to focus attention on the group of interest:

The R group is a convenient way to abbreviate the structures of large biological molecules, especially when we are interested in something that is occurring specifically at one location on the molecule. For example, in chapter 15 when we look at biochemical oxidation-reduction reactions involving the flavin molecule, we will abbreviate a large part of the flavin structure (ie. R = FAD) which does not change at all in the reactions of interest:
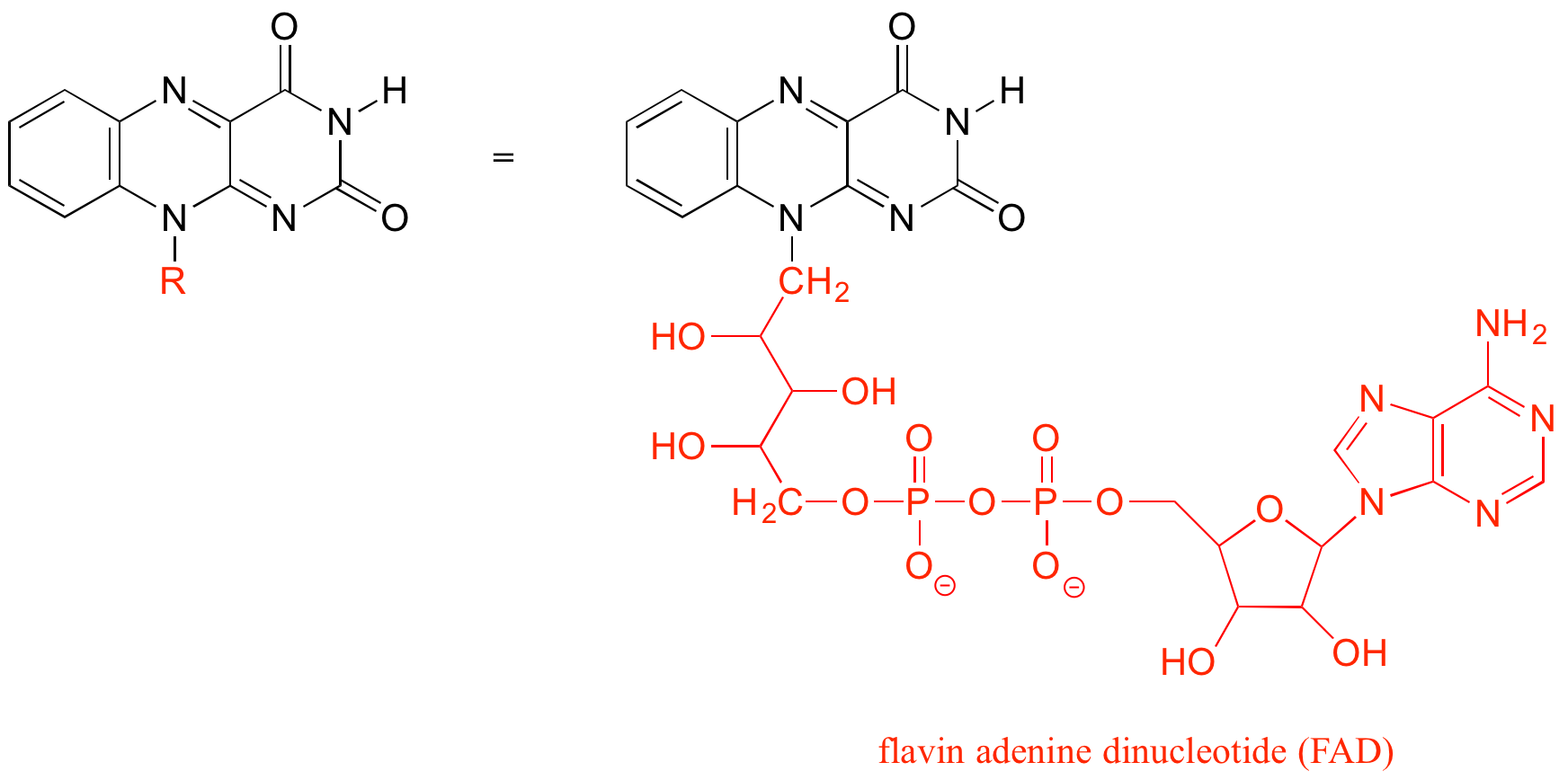
As an alternative, we can use a ‘break’ symbol to indicate that we are looking at a small piece or section of a larger molecule. This is used commonly in the context of drawing groups on large polymers such as proteins or DNA.

Finally, R groups can be used to concisely illustrate a series of related compounds, such as the family of penicillin-based antibiotics.
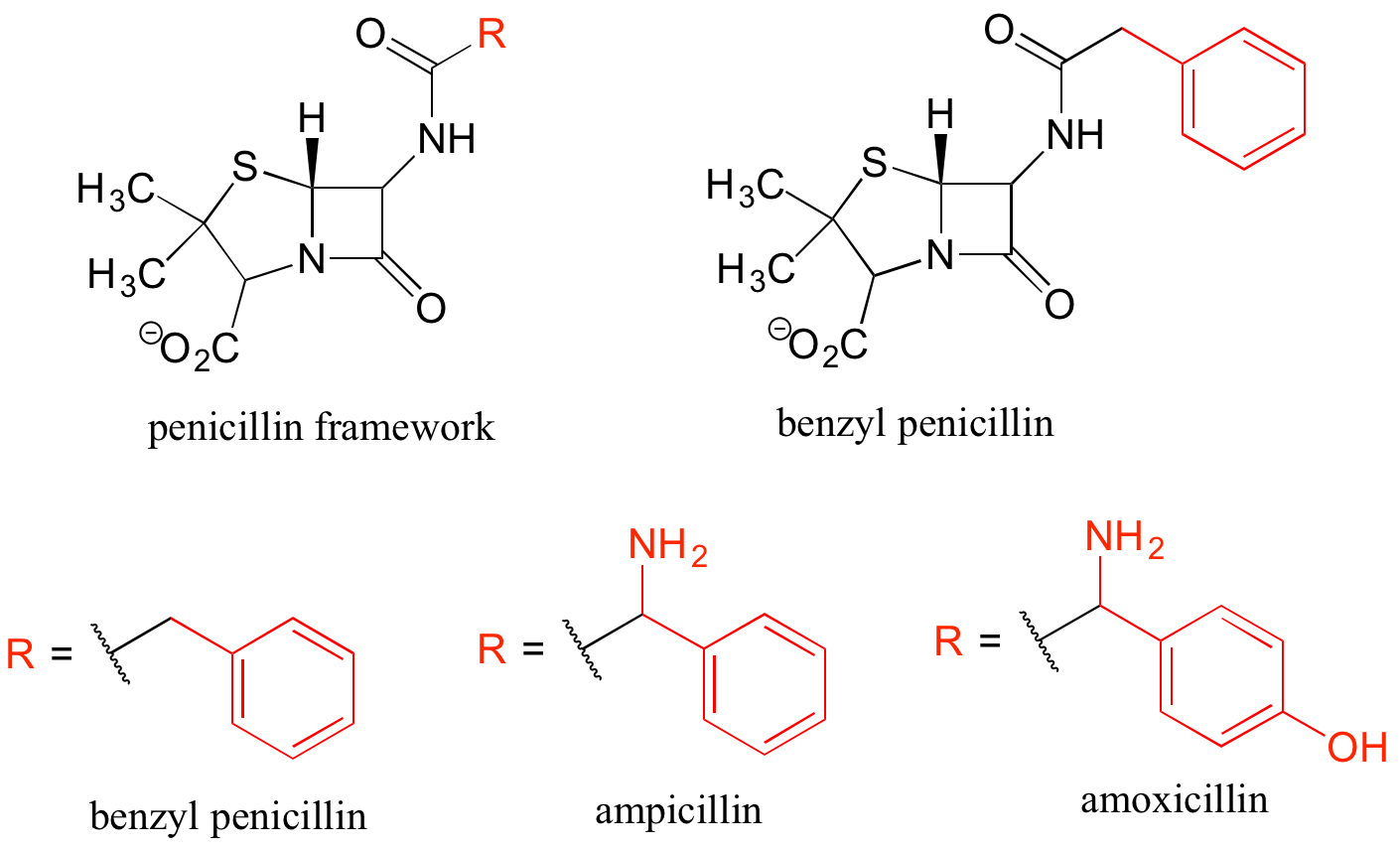
Using abbreviations appropriately is a very important skill to develop when studying organic chemistry in a biological context, because although many biomolecules are very large and complex (and take forever to draw!), usually we are focusing on just one small part of the molecule where a change is taking place.
As a rule, you should never abbreviate any atom involved in a bond-breaking or bond-forming event that is being illustrated: only abbreviate that part of the molecule which is not involved in the reaction of interest.
For example, carbon #2 in the reactant/product below most definitely is involved in bonding changes, and therefore should not be included in the ‘R’ group.
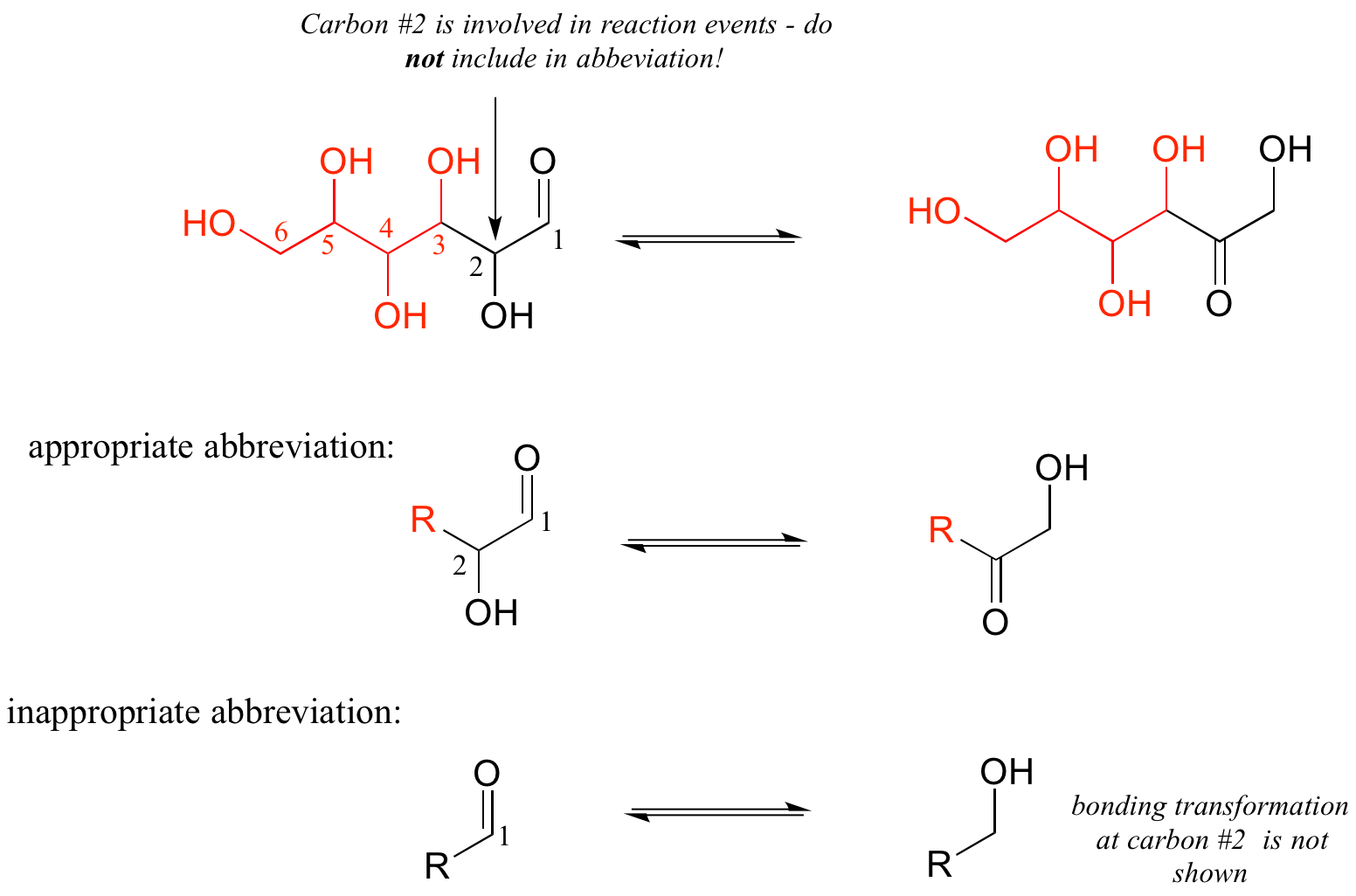
If you are unsure whether to draw out part of a structure or abbreviate it, the safest thing to do is to draw it out.
5.4 Stereoisomers, Enantiomers, and Chirality
As seen in section 5.3, organic chemistry involves infinitely varied structures arising from how the atoms are assembled in 3-dimensional space. Providing only the molecular formula of a compound is often insufficient for defining the compound as many molecular formulas have numerous structural isomers. For example, the molecular formula C2H6O, a molecule of only 9 atoms, can refer to dimethyl ether or ethanol, depending on whether the oxygen is in the middle of or at the end of the carbon chain.
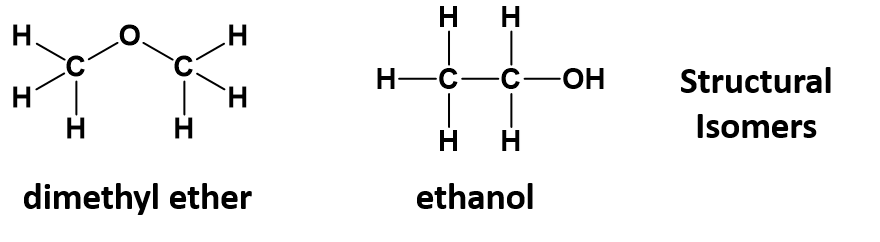
Remember that structural isomers have the same atoms, but the order that the atoms are linked together is different, leading to different physical and chemical properties. For example, ethanol is liquid at room temperature, whereas diethyl ether is a gas.
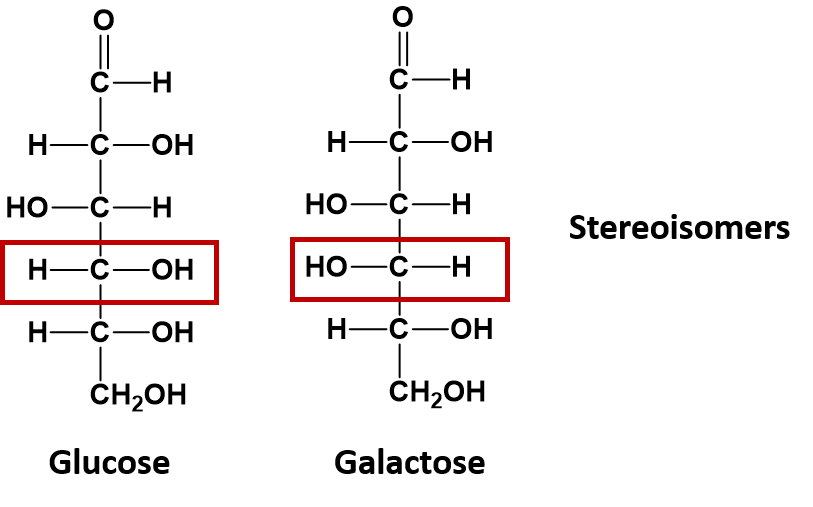
If the atoms of a compound linked together have the same order, but their 3-dimensional arrangement in space differs, they are considered to be a special type of isomer called a stereoisomer. The sugar molecules glucose and galactose are stereoisomers. They differ in the position of a single -OH group as indicated in the diagram below:
There is a special kind of stereoisomers, called enantiomers, that are mirror images of each other, but are not superimposable. This means that no matter how you turn them in space that you can never put them on top of one another and recover the same compound. One example is 2-butanol which can be drawn as a pair of enantiomers (Fig. 5.3).
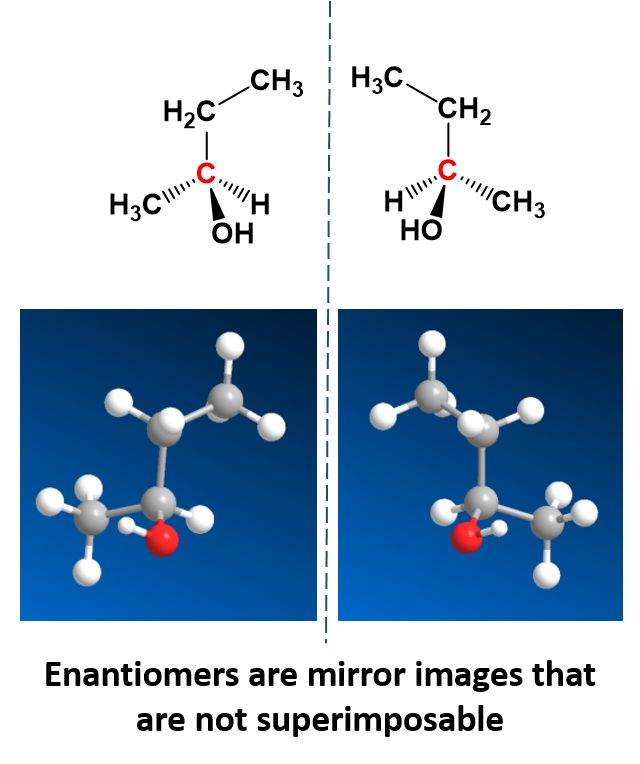
Figure 5.3: The enantiomers of 2-butanol. The enantiomers are shown in the 3-D structural formula displayed in the top diagram and the ball and stick model in the lower diagram.
Chirality
Enantiomers are said to have the property of chirality. Chirality is the term that is given to objects that are mirror images but are not superimposable. The term ‘chiral’ is derived from the Greek word for ‘handedness’ – ie. right-handedness or left-handedness. Your hands are chiral: your right hand is a mirror image of your left hand, but if you place one hand on top of the other, both palms down, you see that they are not superimposable. (Fig 5.4). Thus chiral objects are mirror images of one another, but cannot be superimposed on top of one another. Carbon becomes chiral when it has four different substituents attached to it. You will notice in the example above that the central carbon has four different groups attached to it: an -OH group, an -H, a -CH3, and a -CH2CH3 group.
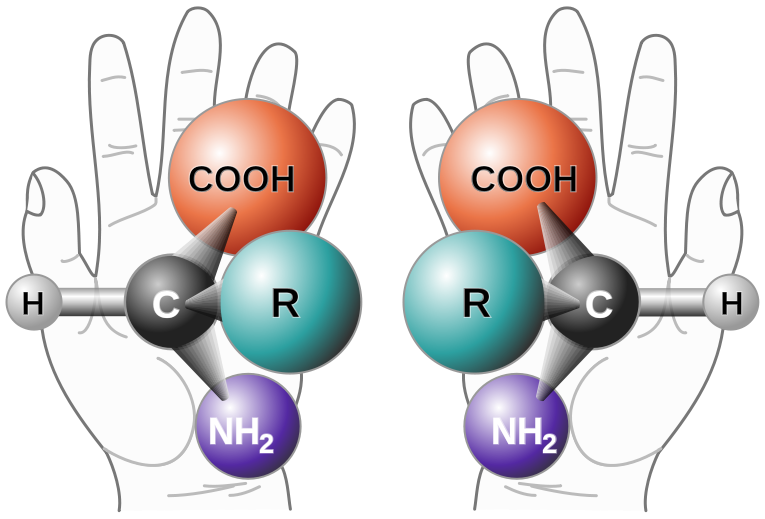
Figure 5.4: The Nature of Chirality. Carbon becomes chiral when it has four different substituents bonded to it. Any way you rotate the molecule on the left, you cannot superimpose it onto the molecule on the right.
Source: Chirality with hands.jpg: Unknown derivative work: — πϵρήλιο ℗ – Chirality with hands.jpg
Stereoisomers that are not enantiomers, such as glucose and galactose shown above, do have chiral centers and are not superimposable, but they are not mirror images of one another. Only stereoisomers that are also mirror images and not superimposable are termed enantiomers. Enantiomers are very hard to separate from one another. They are nearly identical in their physical and chemical properties. They have the same molecular weight, the same polarity, the same melting and boiling points, etc. In fact, enantiomers are so alike that they even share the same name! In Figure 5.3 the two enantiomers of 2-butanol are shown. Both of the molecules are 2-butanol. But they are not exactly the same molecule, in the same way that your left shoe is not exactly the same as your right. They are non-superimposable mirror images of each other. How do we communicate this difference?
One small difference between enantiomers is the direction that polarized light will rotate when it hits the molecule. One enantiomer will rotate light in the clockwise direction, while the other will rotate it in the counterclockwise direction. The clockwise version is termed ‘D’ for dextrorotary (or right-handed) and the counterclockwise version is termed ‘L’ for levorotary (or left-handed). However, light rotation cannot be used in a predictive way to determine the absolute stereo-configuration of a molecule (i.e. you cannot tell which enantiomer is going to rotate the light to the right or to the left until you actually do the experiment).
Thus, another system is needed to describe the absolute configuration. The Cahn-Ingold-Prelog (CIP) priority system was designed to determine the absolute stereo-configuration of enantiomers as either sinister (S) or rectus (R). In this system, the groups that are attached to the chiral carbon are given priority based on their atomic number (Z). Atoms with higher atomic number (more protons) are given higher priority (i.e. S > P > O > N > C > H).
For determining the stereochemistry, place the lowest priority group away from you, so that the other three groups are held are facing you.
Assign priority to the remaining groups.
The rules for this system of stereochemical nomenclature are, on the surface, fairly simple. We’ll use the simple 3-carbon sugar glyceraldehyde as our first example. Try making a model of the stereoisomer of glyceraldehyde shown below. If you don’t have a chemistry modeling kit, an easy alternative is to use toothpicks and gumdrops. Be sure that you are making the correct enantiomer!
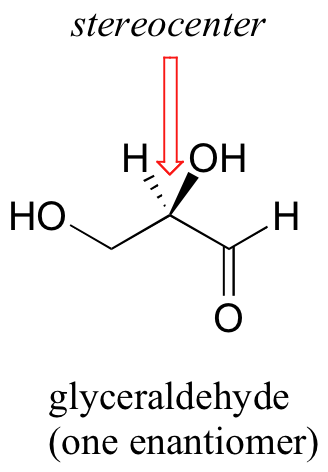
The first thing that we must do is to assign a priority to each of the four substituents bound to the chiral carbon. In this nomenclature system, the priorities are based on atomic number, with higher atomic numbers having a higher priority. We first look at the atoms that are directly bonded to the chiral carbon: these are H, O (in the hydroxyl), C (in the aldehyde), and C (in the CH2OH group).
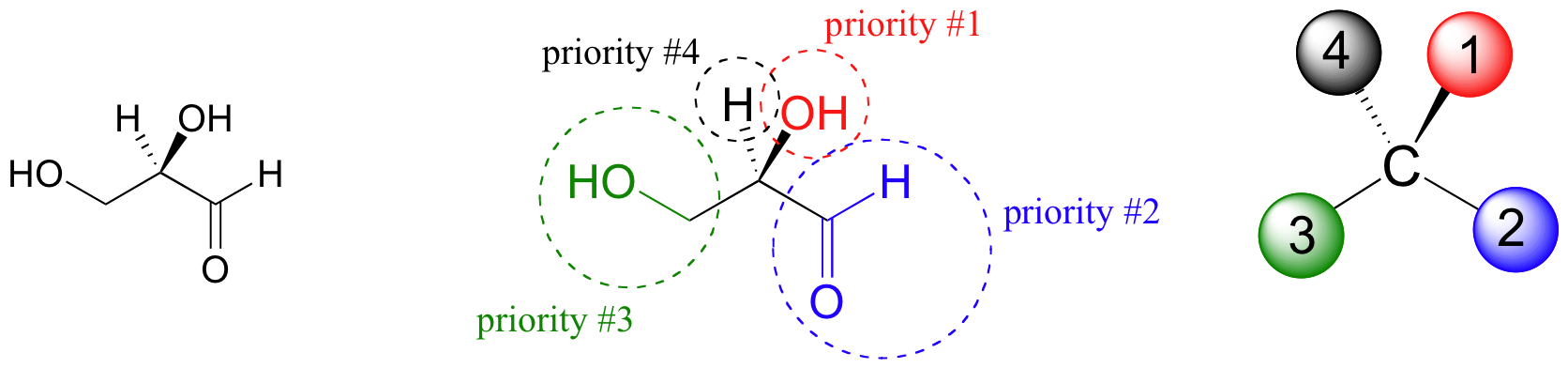
Two priorities are easy: hydrogen, with an atomic number of 1, is the lowest (#4) priority, and the hydroxyl oxygen, with atomic number 8, is priority #1. Carbon has an atomic number of 6. Which of the two ‘C’ groups is priority #2, the aldehyde or the CH2OH? To determine this, we move one more bond away from the stereocenter: for the aldehyde we have a double bond to an oxygen, while on the CH2OH group we have a single bond to an oxygen. If the atom is the same, double bonds have a higher priority than single bonds. Therefore, the aldehyde group is assigned #2 priority and the CH2OH group the #3 priority. With our priorities assigned, we next make sure that the #4 priority group (the hydrogen) is pointed back away from ourselves, into the plane of the page (it is already).

Then, we trace a circle defined by the #1, #2, and #3 priority groups, in increasing order. For our glyceraldehyde example, this circle is clockwise, which tells us that this carbon has the ‘R’ configuration, and that this molecule is (R)-glyceraldehyde. For (S)-glyceraldehyde, the circle described by the #1, #2, and #3 priority groups is counter-clockwise (but first, we must flip the molecule over so that the H is pointing into the plane of the page).
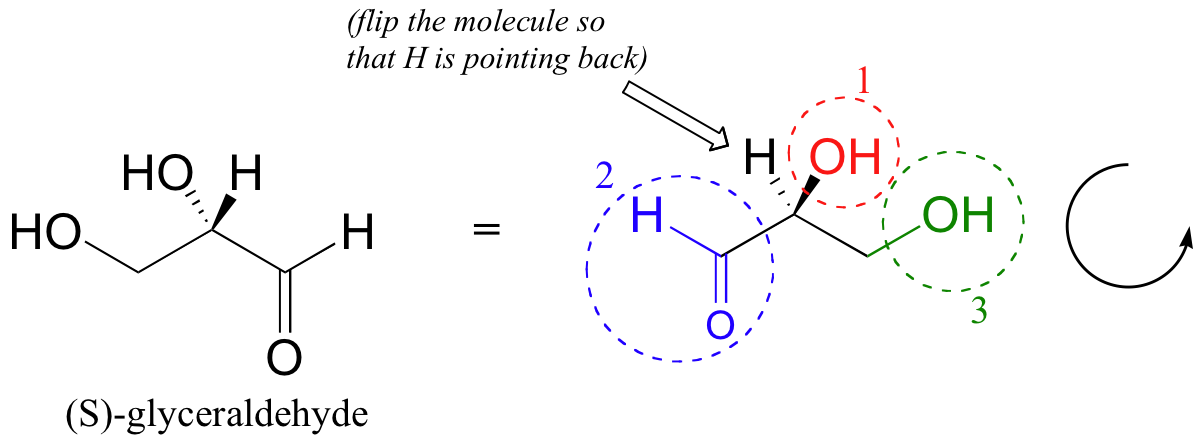
In the case of 2-butanol (Fig 5.5), the first priority and the fourth priority are easy to assign. The -OH is first priority and the -H is fourth priority. How do you assign 2nd and 3rd priority, since both of those atoms are carbon? If the priority is the same for an attached atom, you need to look out to the next level and evaluate priority there. For 2-butanol, one group is -CH3 and one group is -CH2CH3. In the first situation, if we look out to the next level, this carbon is bound to three other hydrogen atoms (all very low priority). In the second situation, the carbon is bound to two hydrogens and one carbon. Since C has a higher priority than H, the -CH2CH3 group will have higher priority over the -CH3 group. Once all of the groups have been assigned priority, you can determine which direction the priority is moving. If it is in the clockwise direction, the molecule is given the ‘R’ designation. Priority moving in the counterclockwise direction is given the ‘S’ designation. In our example, the 2-butanol on the left shows priority moving in the counterclockwise direction giving the S-enantiomer. The molecule on the right shows the R-enantiomer with priority moving in the clockwise direction.
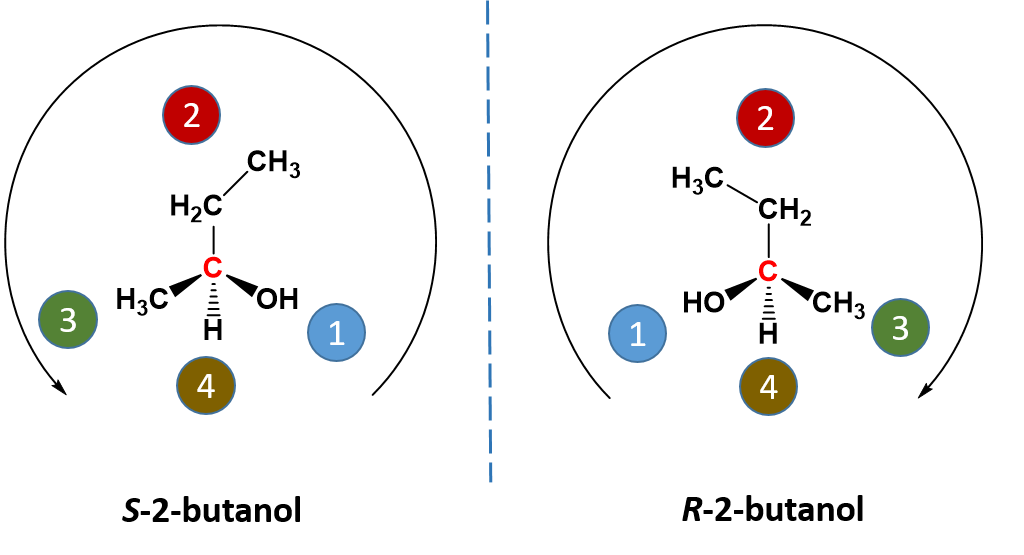
Figure 5.5: Stereochemistry of 2-butanol. The CIP priority system can be used to determine the absolute stereo-conformation of enantiomers
Thalidomide – A Story of Unintended Consequences
Interestingly, enantiomers have the same physical properties and exactly the same chemical properties, except when reacting with other chiral molecules. Thus, chiral molecules have potentially drastic differences in physiology and medicine. For example, in the 1960’s, a drug called thalidomide was widely prescribed in Western Europe to alleviate morning sickness in pregnant women.
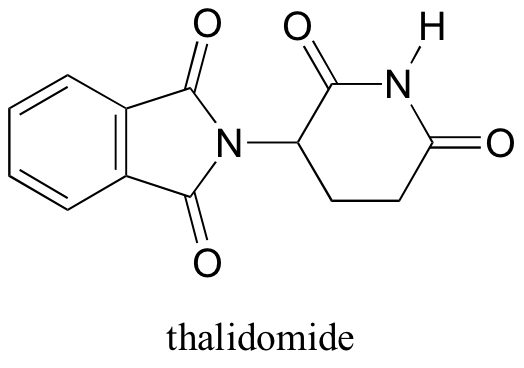
Thalidomide had previously been used in other countries as an antidepressant, and was believed to be safe and effective. It was not long, however, before doctors realized that something had gone horribly wrong: many babies born to women who had taken thalidomide during pregnancy suffered from severe birth defects.
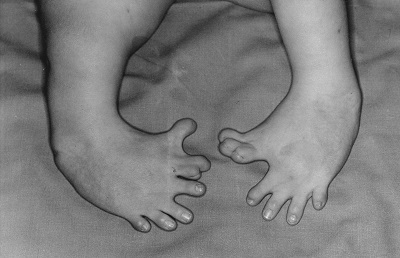 Baby born to a mother who had taken thalidomide while pregnant.
Baby born to a mother who had taken thalidomide while pregnant.
Researchers later realized the that problem lay in the fact that thalidomide was being provided as a mixture of two different isomeric forms, called a racemic mixture.

One of the isomers is an effective medication, while the other caused the side effects. Both isomeric forms have the same molecular formula and the same atom-to-atom connectivity, so they are not merely structural isomers. Where they differ is in the arrangement in three-dimensional space about one tetrahedral chiral carbon. Thus, these two forms of thalidomide are enantiomers.
Note that the carbon in question has four different substituents (two of these just happen to be connected by a ring structure). Tetrahedral carbons with four different substituent groups are called stereocenters.

Looking at the structures of what we are referring to as the two isomers of thalidomide, you may not be entirely convinced that they are actually two different molecules. In order to convince ourselves that they are indeed different, let’s create a generalized picture of a tetrahedral carbon stereocenter, with the four substituents designated R1-R4. The two stereoisomers of our simplified model look like this:
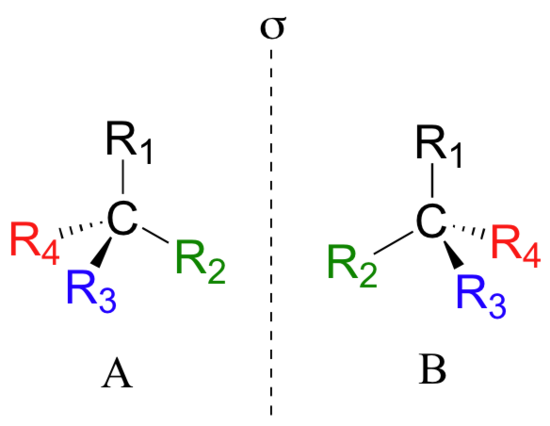
If you look carefully at the figure above, you will notice that molecule A and molecule B are mirror images of each other (the line labeled ‘σ’ represents a mirror plane). Furthermore, they are not superimposable: if we pick up molecule A, flip it around, and place it next to molecule B, we see that the two structures cannot be superimposed on each other. They are two different molecules!
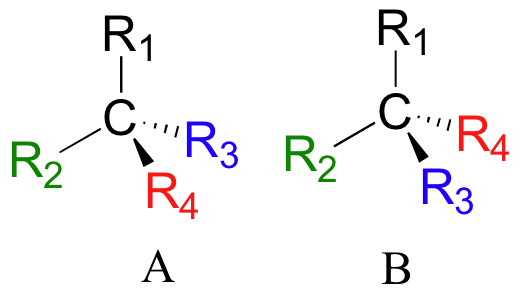
If you make models of the two stereoisomers of thalidomide and do the same thing, you will see that they too are mirror images, and cannot be superimposed (it will help to look at a color version of the figure below).

Thalidomide is a chiral molecule.
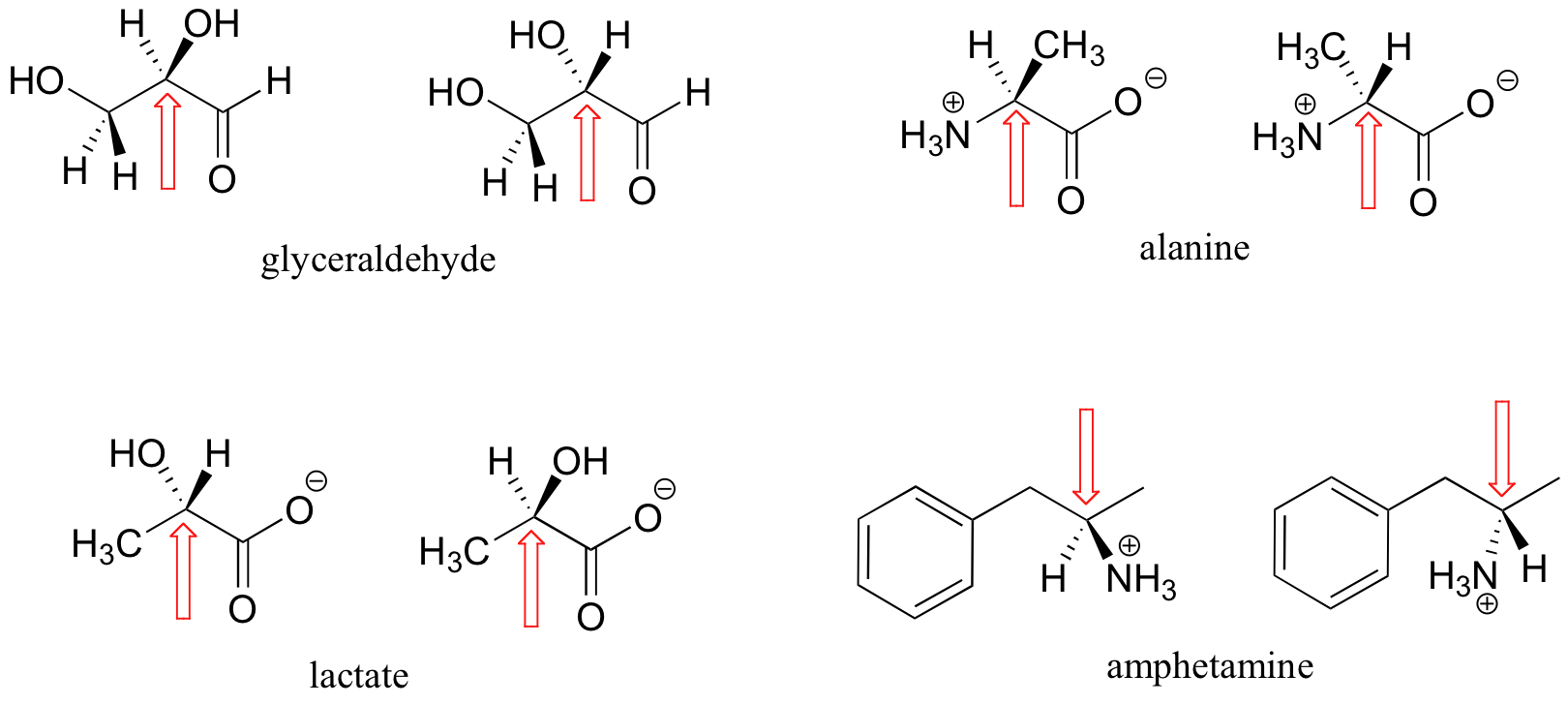
Here are some more examples of chiral molecules that exist as pairs of enantiomers. In each of these examples, there is a single stereocenter, indicated with an arrow. (Many molecules have more than one stereocenter, but we will get to that that a little later!)
Here are some examples of molecules that are achiral (not chiral). Notice that none of these molecules has a stereocenter (an atom that is bound to four different substituents).
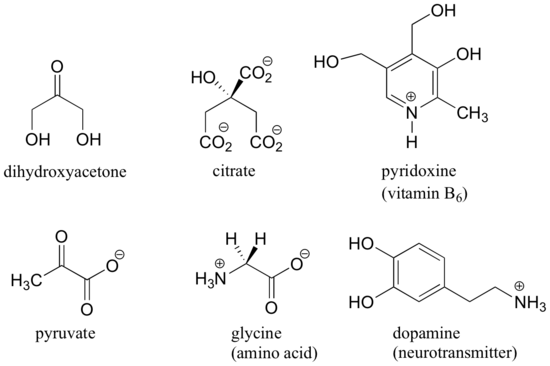
When evaluating a molecule for chirality, it is important to recognize that the use of the dashed/solid wedge drawing does not necessarily mean that the molecule is chiral. Chiral molecules are sometimes drawn without using wedges. Conversely, wedges may be used on carbons that are not stereocenters – look, for example, at the drawings of glycine and citrate in the figure above. Just because you see dashed and solid wedges in a structure, do not automatically assume that you are looking at a stereocenter.
Other elements in addition to carbon can be stereocenters. The phosphorus center of phosphate ion and organic phosphate esters, for example, is tetrahedral, and thus is potentially a stereocenter.


Having trouble visualizing chirality and enantiomers? It may be helpful to watch this
5.5 The Importance of Chirality in Protein Interactions
The thalidomide that was used in the 1960s to treat depression and morning sickness was sold as a 50:50 mixture of both the R and the S enantiomer – this is referred to as a racemic mixture. A ‘squiggly’ bond in a chemical structure indicates a racemic mixture – thus racemic (R/S) thalidomide would be drawn as:
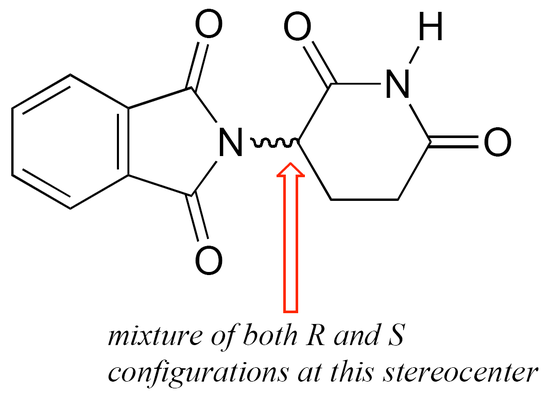
The problem with racemic thalidomide, as we learned above, is that only the R enantiomer is an effective medicine, while the S enantiomer causes mutations in the developing fetus. How does such a seemingly trivial structural variation lead to such a dramatic (and in this case, tragic) difference in biological activity? Virtually all drugs work by interacting in some way with important proteins in our cells: they may bind to pain receptor proteins to block the transmission of pain signals, for instance, or clog up the active site of an enzyme that is involved in the synthesis of cholesterol. Proteins are chiral molecules, and are very sensitive to stereochemistry: just as a right-handed glove won’t fit on your left hand, a protein that is able to bind tightly to (R)-thalidomide may not bind well at all to (S)-thalidomide (it will help to view a color version of the figure below).

Instead, it seems that (S)-thalidomide interacts somehow with a protein involved in the development of a growing fetus, eventually causing the observed birth defects.
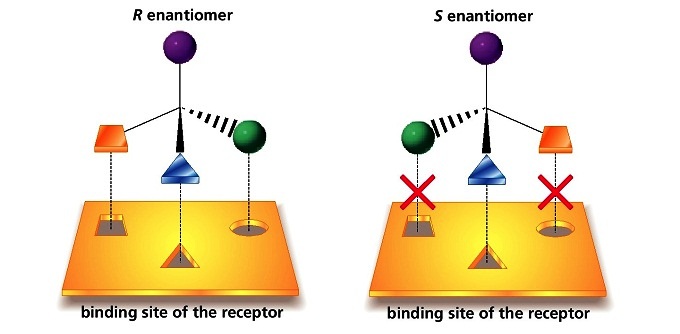
Figure 5.5 Drug binding sites on proteins are stereospecific.
Source: www.kshitij-iitjee.com/Study/Chemistry/Part2/Chapter3/109.jpg
The over-the-counter painkiller ibuprofen is currently sold as a racemic mixture, but only the S enantiomer is effective.
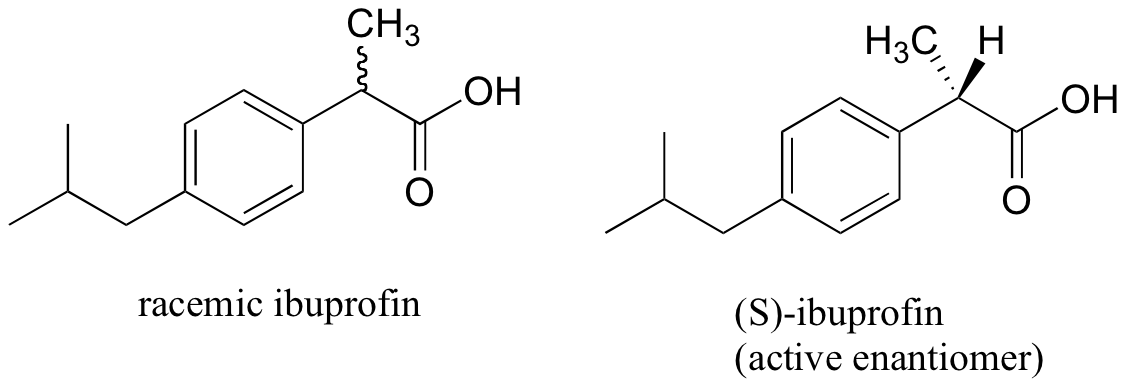
Fortunately, the R enantiomer does not produce any dangerous side effects, although its presence does seem to increase the amount of time that it takes for (S)-ibuprofen to take effect.
You can, with the assistance your instructor, directly experience the biological importance of stereoisomerism. Carvone is a chiral, plant-derived molecule that smells like spearmint in the R form and caraway (a spice) in the S form.
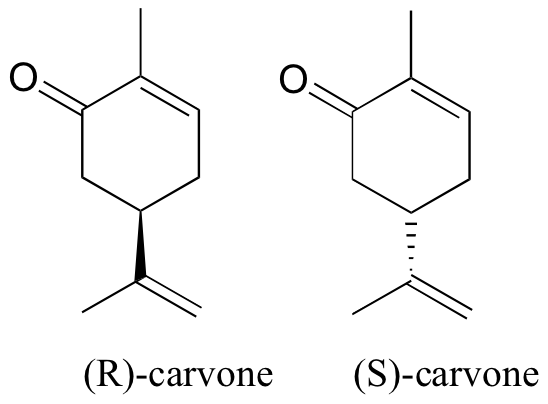
The two enantiomers interact differently with smell receptor proteins in your nose, generating the transmission of different chemical signals to the olfactory center of your brain.
5.6 Recognizing Common Organic Functional Groups
The number of known organic compounds is a quite large. In fact, there are many times more organic compounds known than all the other (inorganic) compounds discovered so far, about 7 million organic compounds in total. Fortunately, organic chemicals consist of a relatively few similar parts, combined in different ways, that allow us to predict how a compound we have never seen before may react, by comparing how other molecules containing the same types of parts are known to react.
These parts of organic molecules are called functional groups and are made up from specific bonding patterns with the atoms most commonly found in organic molecules (C, H, O, N, S, and P). The identification of functional groups and the ability to predict reactivity based on functional group properties is one of the cornerstones of organic chemistry.
Functional groups are specific atoms, ions, or groups of atoms having consistent properties. A functional group makes up part of a larger molecule.
For example, -OH, the hydroxyl group that characterizes alcohols, is an oxygen with a hydrogen attached. It could be found on any number of different molecules.
Just as elements have distinctive properties, functional groups have characteristic chemistries. An -OH functional group on one molecule will tend to react similarly, although perhaps not identically, to an -OH on another molecule.
Organic reactions usually take place at the functional group, so learning about the reactivities of functional groups will prepare you to understand many other things about organic chemistry.
Functional groups are structural units within organic compounds that are defined by specific bonding arrangements between specific atoms. The structure of capsaicin, the compound discussed in the beginning of this chapter, incorporates several functional groups, labeled in the figure below and explained throughout this section.
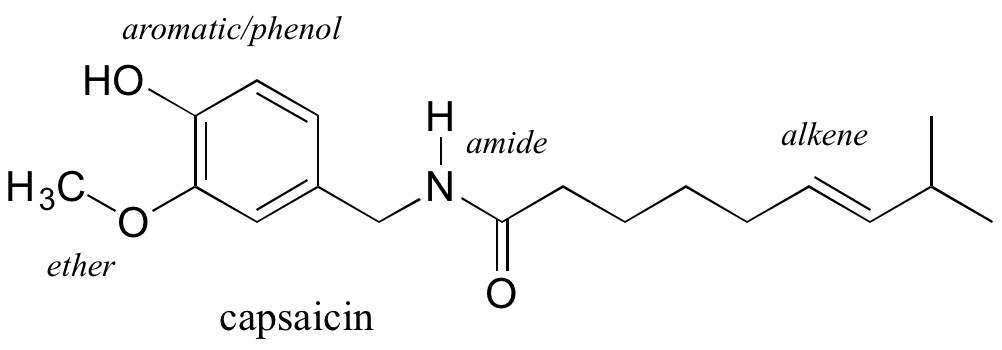
As we progress in our study of organic chemistry, it will become extremely important to be able to quickly recognize the most common functional groups, because they are the key structural elements that define how organic molecules react. For now, we will only worry about drawing and recognizing each functional group, as depicted by Lewis and line structures. Much of the remainder of your study of organic chemistry will be taken up with learning about how the different functional groups behave in organic reactions. Below is a brief introduction to the major organic functional groups.
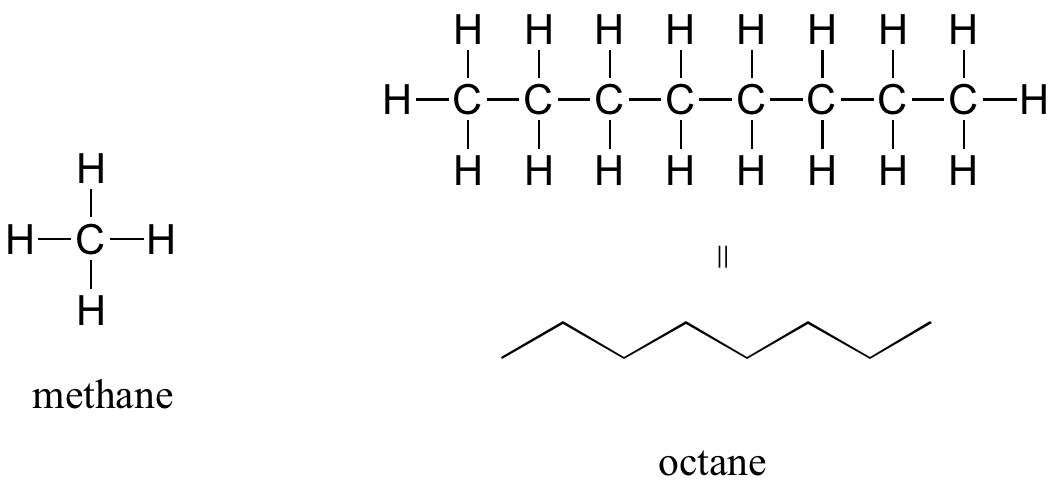
Alkanes
The ‘default’ in organic chemistry (essentially, the lack of any functional groups) is given the term alkane, characterized by single bonds between carbon and carbon, or between carbon and hydrogen. Methane, CH4, is the natural gas you may burn in your furnace. Octane, C8H18, is a component of gasoline.
Alkenes and Alkynes
Alkenes (sometimes called olefins) have carbon-carbon double bonds, and alkynes have carbon-carbon triple bonds. Ethene, the simplest alkene example, is a gas that serves as a cellular signal in fruits to stimulate ripening. (If you want bananas to ripen quickly, put them in a paper bag along with an apple – the apple emits ethene gas (also called ethylene), setting off the ripening process in the bananas). Ethyne, commonly called acetylene, is used as a fuel in welding blow torches.
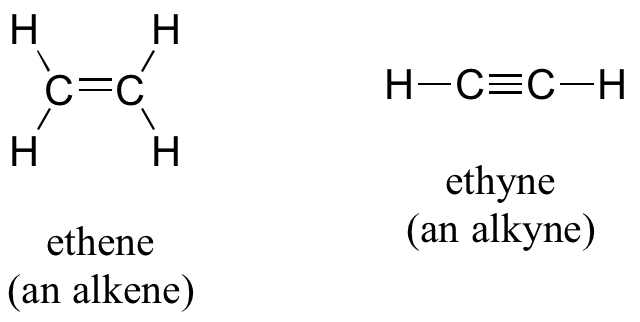
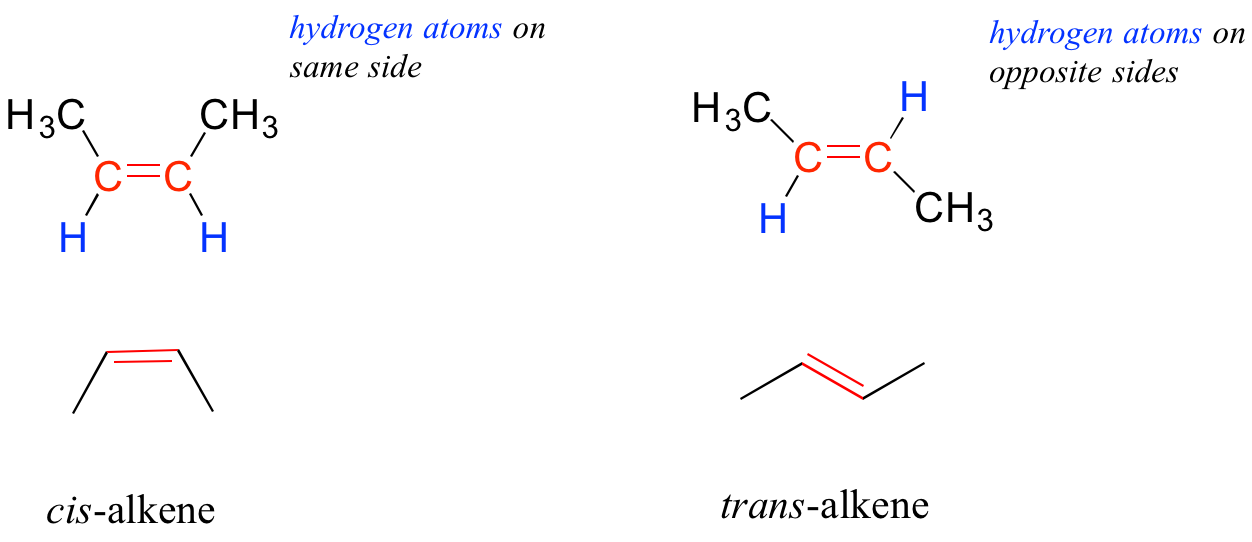
In chapter 6, we will study the nature of the bonding on alkenes and alkynes, and learn that that the bonding in alkenes is trigonal planar in in alkynes is linear. Furthermore, many alkenes can take two geometric forms: cis or trans. The cis and trans forms of a given alkene are different isomers with different physical properties because, as we will learn in chapter 6, there is a very high energy barrier to rotation about a double bond. In the example below, the difference between cis and trans alkenes is readily apparent.
Alkanes, alkenes, and alkynes are all classified as hydrocarbons, because they are composed solely of carbon and hydrogen atoms. Alkanes are said to be saturated hydrocarbons, because the carbons are bonded to the maximum possible number of hydrogens – in other words, they are saturated with hydrogen atoms. The double and triple-bonded carbons in alkenes and alkynes have fewer hydrogen atoms bonded to them – they are thus referred to as unsaturated hydrocarbons. As we will see in a later chapter, hydrogen can be added to double and triple bonds, in a type of reaction called ‘hydrogenation’.
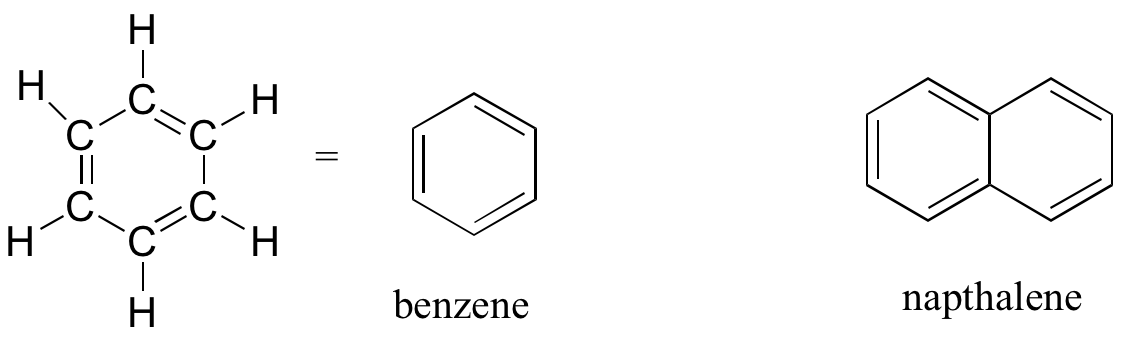
Aromatics
The aromatic group is exemplified by benzene (which used to be a commonly used solvent on the organic lab, but which was shown to be carcinogenic), and naphthalene, a compound with a distinctive ‘mothball’ smell. Aromatic groups are planar (flat) ring structures, and are widespread in nature.
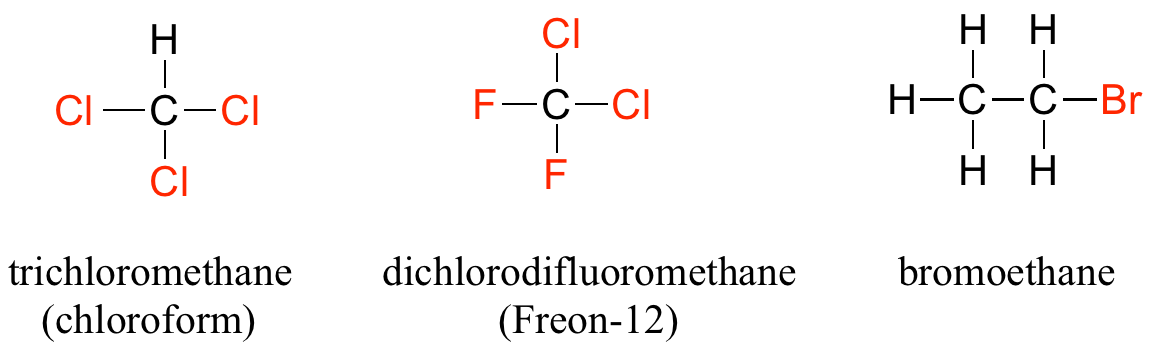
When the carbon of an alkane is bonded to one or more halogens, the group is referred to as an alkyl halide or haloalkane. Chloroform is a useful solvent in the laboratory, and was one of the earlier anesthetic drugs used in surgery. Chlorodifluoromethane was used as a refrigerant and in aerosol sprays until the late twentieth century, but its use was discontinued after it was found to have harmful effects on the ozone layer. Bromoethane is a simple alkyl halide often used in organic synthesis. Alkyl halides groups are quite rare in biomolecules.
Alcohols, Phenols, and Thiols
In the alcohol functional group, a carbon is single-bonded to an OH group (the OH group, when it is part of a larger molecule, is referred to as a hydroxyl group). Except for methanol, all alcohols can be classified as primary, secondary, or tertiary. In a primary alcohol, the carbon bonded to the OH group is also bonded to only one other carbon. In a secondary alcohol and tertiary alcohol, the carbon is bonded to two or three other carbons, respectively. When the hydroxyl group is directly attached to an aromatic ring, the resulting group is called a phenol. The sulfur analog of an alcohol is called a thiol (from the Greek thio, for sulfur).

Note that the definition of a phenol states that the hydroxyl oxygen must be directly attached to one of the carbons of the aromatic ring. The compound below, therefore, is not a phenol – it is a primary alcohol.
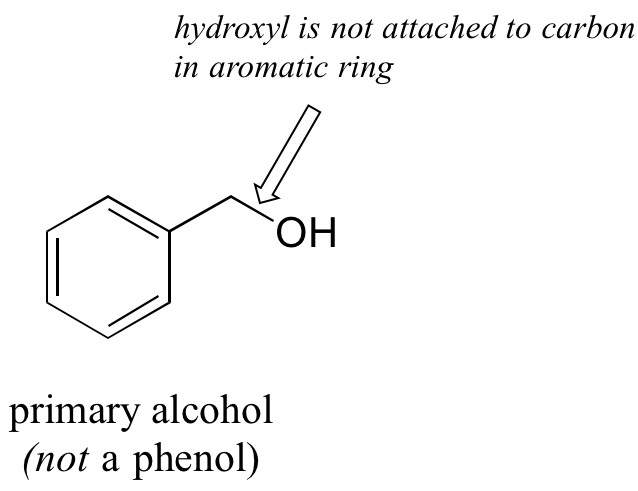
The distinction is important, because as we will see later, there is a significant difference in the reactivity of alcohols and phenols
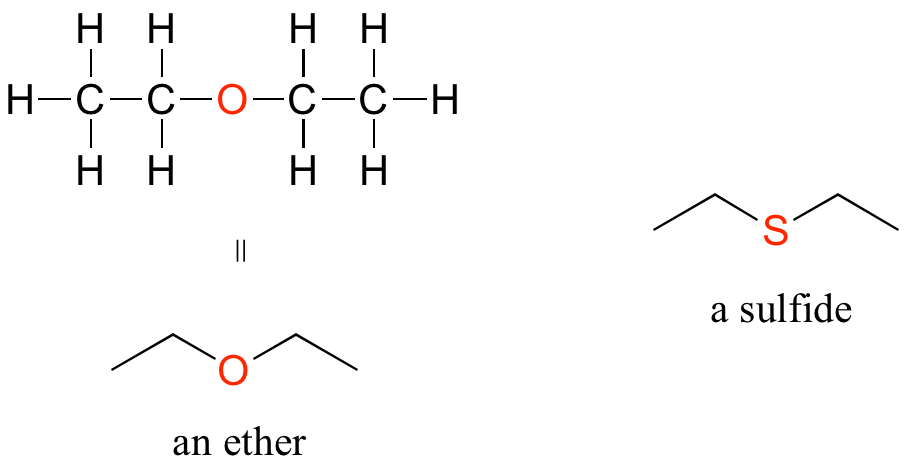
Ethers and Sulfides
In an ether functional group, an oxygen is bonded to two carbons. Below is the structure of diethyl ether, a common laboratory solvent and also one of the first compounds to be used as an anesthetic during operations. The sulfur analog of an ether is called a thioether or sulfide.
Amines
Amines are characterized by nitrogen atoms with single bonds to hydrogen and carbon. Just as there are primary, secondary, and tertiary alcohols, there are primary, secondary, and tertiary amines. Ammonia is a special case with no carbon atoms.
One of the most important properties of amines is that they are basic, and are readily protonated to form ammonium cations. In the case where a nitrogen has four bonds to carbon (which is somewhat unusual in biomolecules), it is called a quaternary ammonium ion.
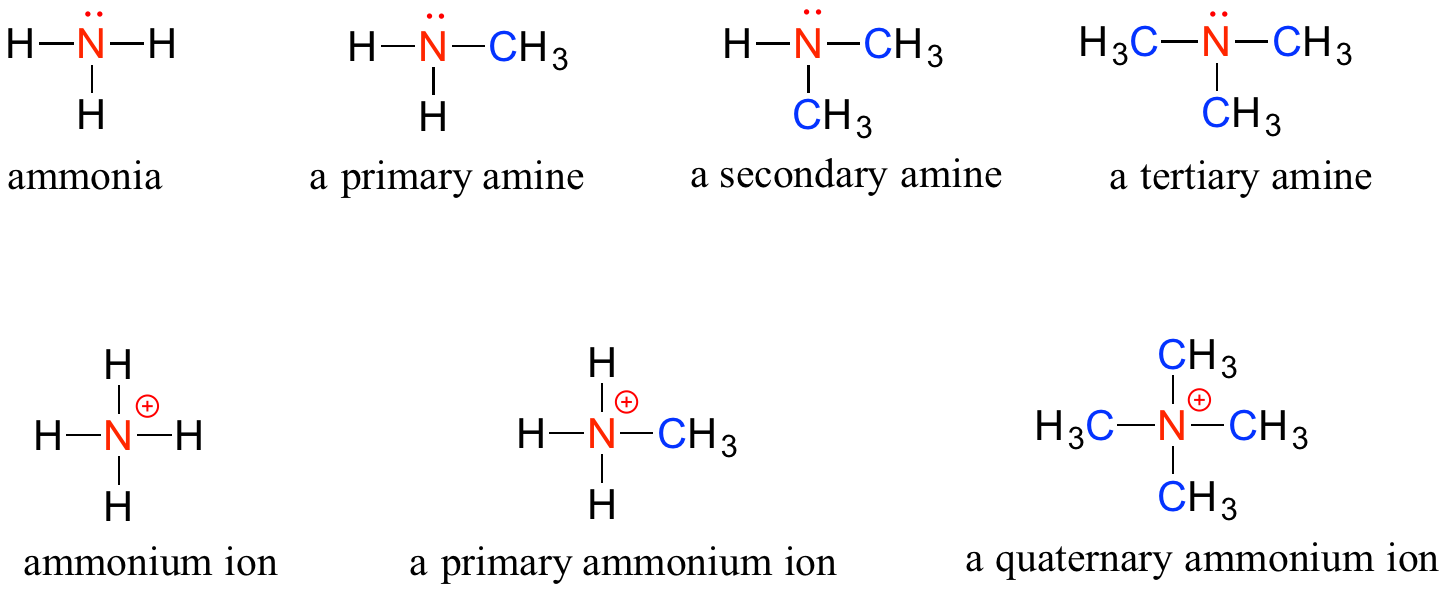
Note: Do not be confused by how the terms ‘primary’, ‘secondary’, and ‘tertiary’ are applied to alcohols and amines – the definitions are different. In alcohols, what matters is how many other carbons the alcohol carbon is bonded to, while in amines, what matters is how many carbons the nitrogen is bonded to.
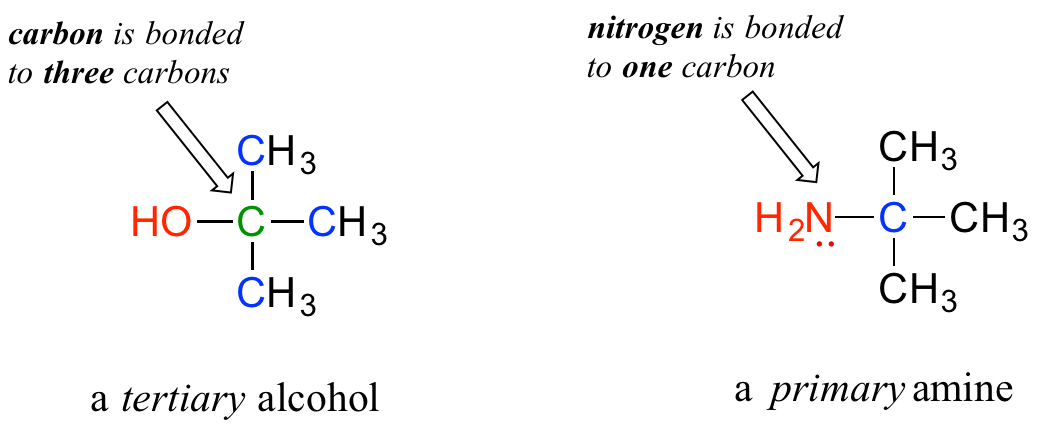
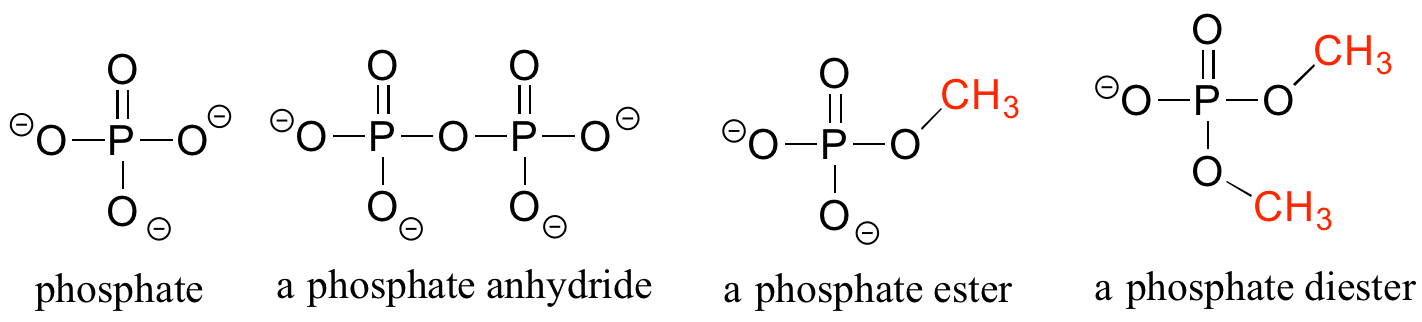
Organic Phosphates
Phosphate and its derivative functional groups are ubiquitous in biomolecules. Phosphate linked to a single organic group is called a phosphate ester; when it has two links to organic groups it is called a phosphate diester. A linkage between two phosphates creates a phosphate anhydride.
Aldehydes and Ketones
There are a number of functional groups that contain a carbon-oxygen double bond, which is commonly referred to as a carbonyl. Ketones and aldehydes are two closely related carbonyl-based functional groups that react in very similar ways. In a ketone, the carbon atom of a carbonyl is bonded to two other carbons. In an aldehyde, the carbonyl carbon is bonded on one side to a hydrogen, and on the other side to a carbon. The exception to this definition is formaldehyde, in which the carbonyl carbon has bonds to two hydrogens.

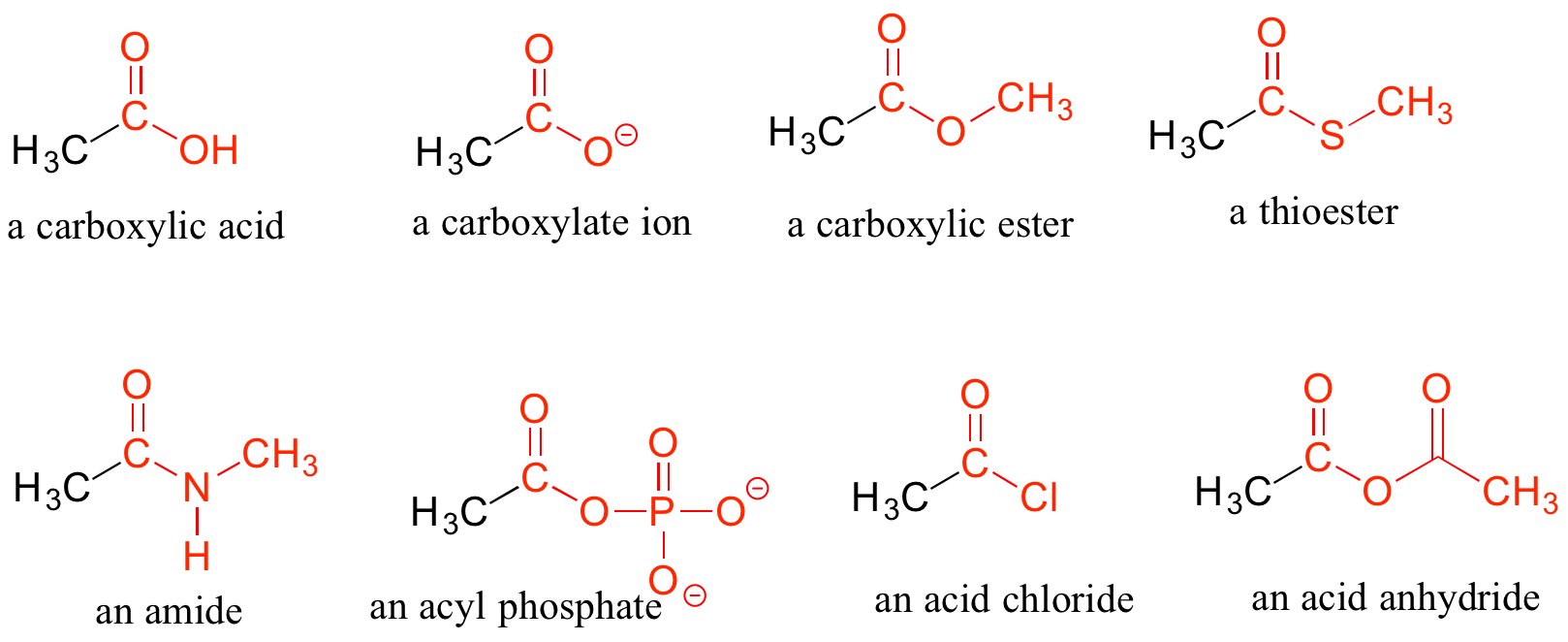
Carboxylic Acids and Their Derivatives
When a carbonyl carbon is bonded on one side to a carbon (or hydrogen) and on the other side to an oxygen, nitrogen, or sulfur, the functional group is considered to be one of the ‘carboxylic acid derivatives’, a designation that describes a set of related functional groups. The main member of this family is the carboxylic acid functional group, in which the carbonyl is bonded to a hydroxyl group. The carboxylate ion form has donated the H+ to the solution. Other derivatives are carboxylic esters (usually just called ‘esters’), thioesters, amides, acyl phosphates, acid chlorides, and acid anhydrides. With the exception of acid chlorides and acid anhydrides, the carboxylic acid derivatives are very common in biological molecules and/or metabolic pathways, and their structure and reactivity will be discussed in more detail in later chapters.
Finally, a nitrile group is characterized by a carbon-nitrogen triple bond as shown in the structure of acetonitrile.

Practice Recognizing Functional Groups in Molecules
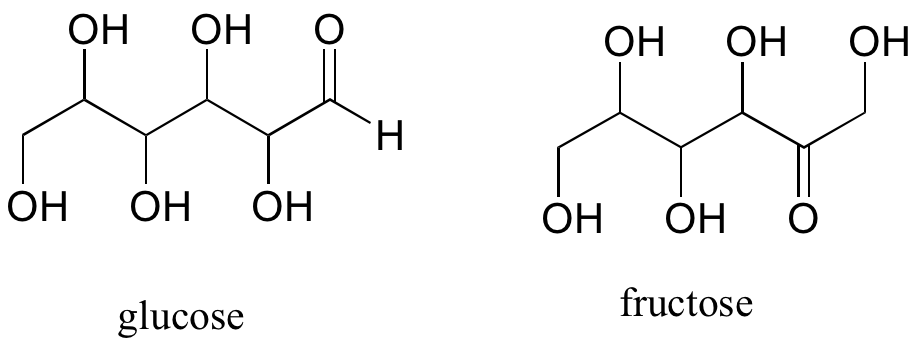
A single compound often contains several functional groups, particularly in biological organic chemistry. The six-carbon sugar molecules glucose and fructose, for example, contain aldehyde and ketone groups, respectively, and both contain five alcohol groups. A compound with several alcohol groups is often referred to as a ‘polyol’.
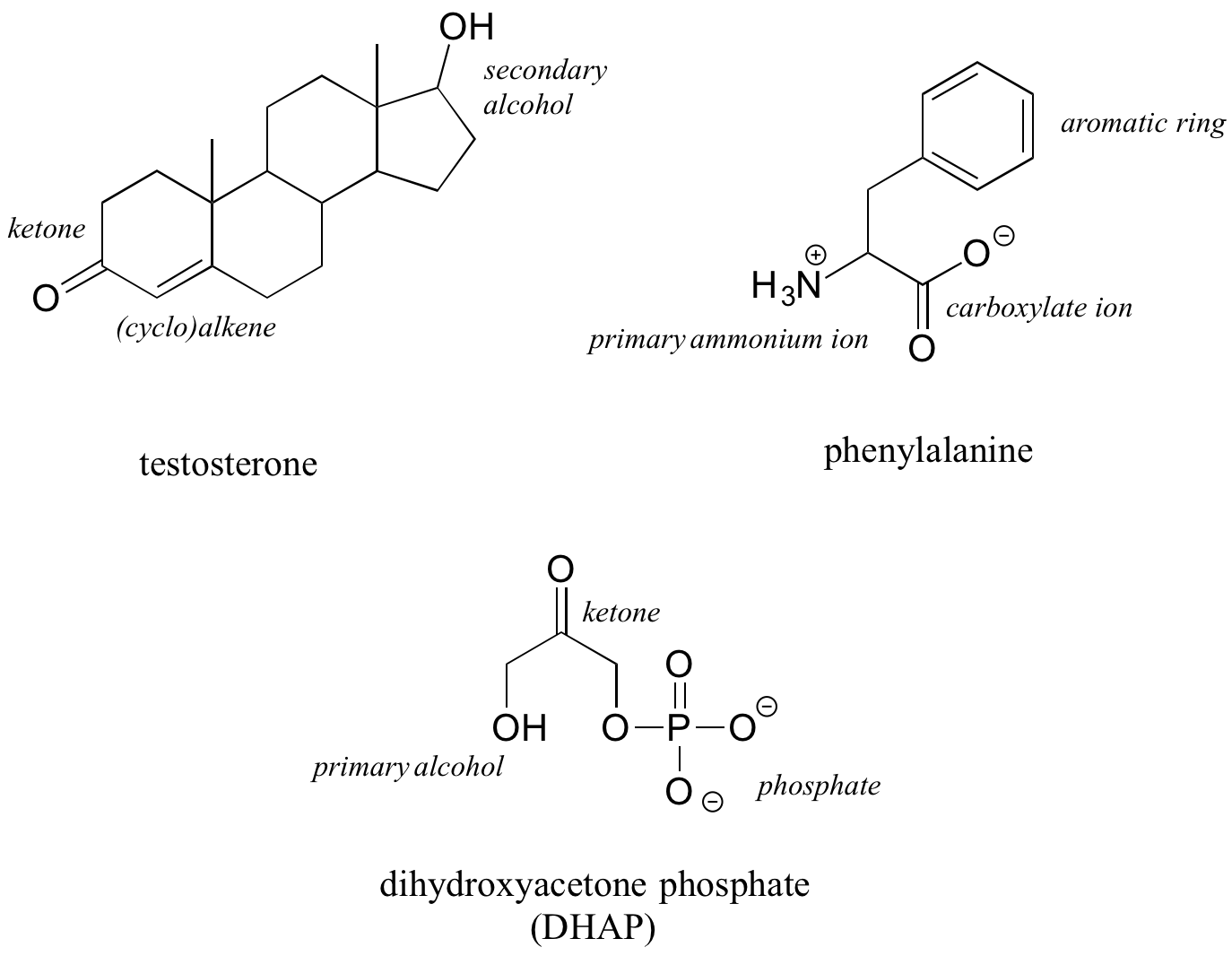
The hormone testosterone, the amino acid phenylalanine, and the glycolysis metabolite dihydroxyacetone phosphate all contain multiple functional groups, as labeled below.
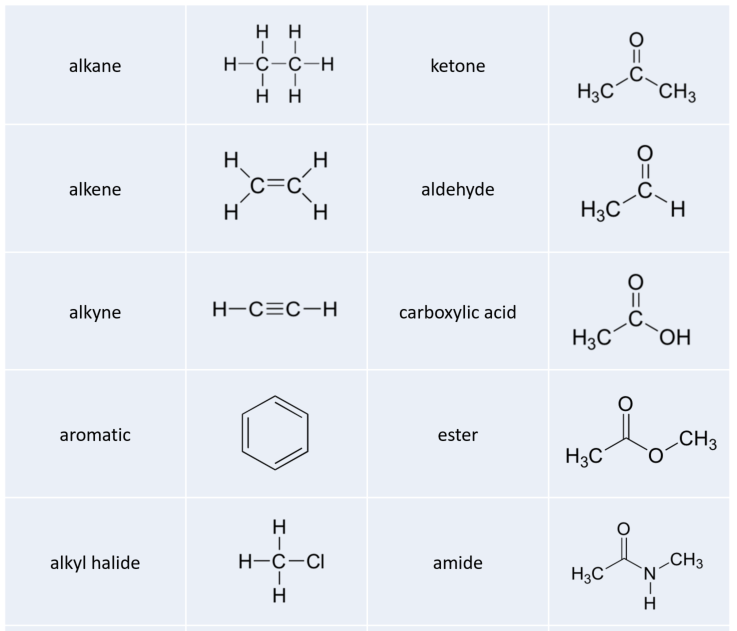
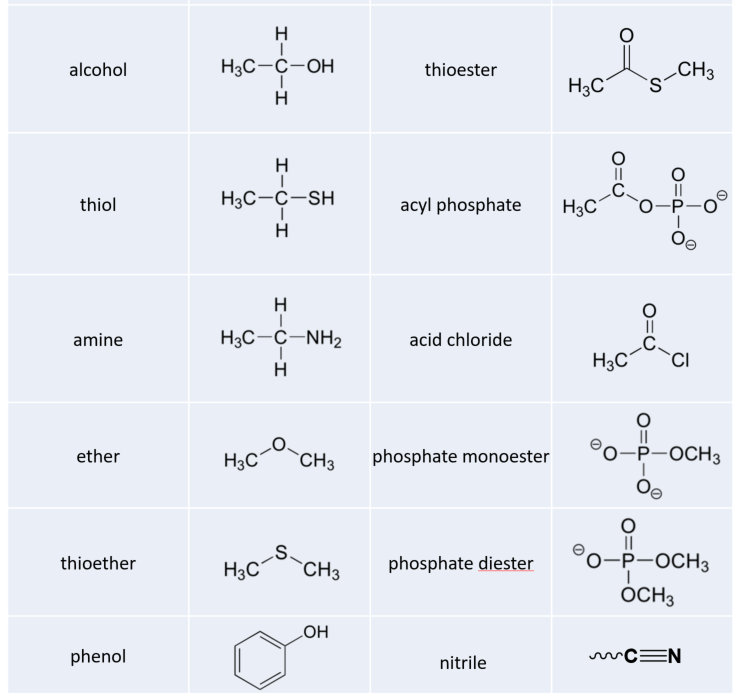
While not in any way a complete list, this section has covered most of the important functional groups that we will encounter in biochemistry. Table 5.2 provides a summary of all of the groups listed in this section.
Table 5.2 Common Organic Functional Groups
Exercise 5.6.1
Identify the functional groups (other than alkanes) in the following organic compounds. State whether alcohols and amines are primary, secondary, or tertiary.
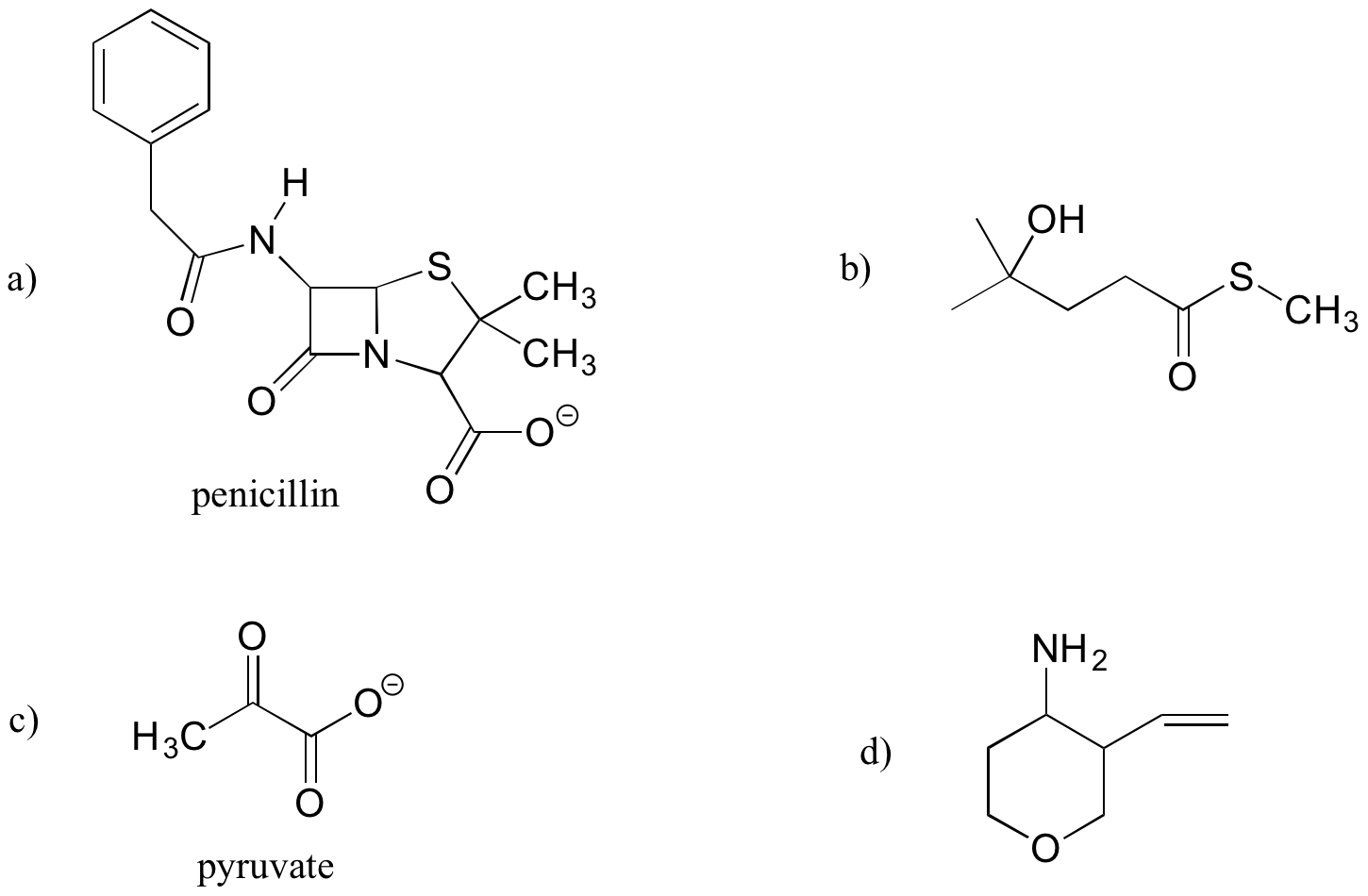
Exercise 5.6.2
Draw one example each of compounds fitting the descriptions below, using line structures. Be sure to designate the location of all non-zero formal charges. All atoms should have complete octets (phosphorus may exceed the octet rule). There are many possible correct answers for these, so be sure to check your structures with your instructor or tutor.
a) a compound with molecular formula C6H11NO that includes alkene, secondary amine, and primary alcohol functional groups
b) an ion with molecular formula C3H5O6P2- that includes aldehyde, secondary alcohol, and phosphate functional groups.
c) A compound with molecular formula C6H9NO that has an amide functional group, and does not have an alkene group.
5.7 A Brief Overview of Organic Nomenclature
A system has been devised by the International Union of Pure and Applied Chemistry (IUPAC, usually pronounced eye-you-pack) for naming organic compounds. While the IUPAC system is convenient for naming relatively small, simple organic compounds, it is not generally used in the naming of biomolecules, which tend to be quite large and complex. It is, however, a good idea (even for biologists) to become familiar with the basic structure of the IUPAC system, and be able to draw simple structures based on their IUPAC names.
Naming an organic compound usually begins with identifying what is referred to as the ‘parent chain’, which is the longest straight chain of carbon atoms. We’ll start with the simplest straight chain alkane structures. CH4 is called methane, and C2H6 ethane. The table below continues with the names of longer straight-chain alkanes: be sure to commit these to memory, as they are the basis for the rest of the IUPAC nomenclature system (and are widely used in naming biomolecules as well).
Names for straight-chain alkanes:
1 carbon: methane
2 carbons: ethane
3 carbons: propane
4 carbons: butane
5 carbons: pentane
6 carbons: hexane
7 carbons: heptane
8 carbons: octane
9 carbons: nonane
10 carbons: decane
Substituents branching from the main parent chain are located by a carbon number, with the lowest possible numbers being used (for example, notice below that the compound on the left is named 1-chlorobutane, not 4-chlorobutane). When the substituents are small alkyl groups, the terms methyl, ethyl, and propyl are used.

Other common names for hydrocarbon substituent groups include isopropyl, tert-butyl and phenyl.

Notice in the example below, an ‘ethyl group’ (in blue) is not treated as a substituent, rather it is included as part of the parent chain, and the methyl group is treated as a substituent. The IUPAC name for straight-chain hydrocarbons is always based on the longest possible parent chain, which in this case is four carbons, not three.

Cyclic alkanes are called cyclopropane, cyclobutane, cyclopentane, cyclohexane, and so on:

In the case of multiple substituents, the prefixes di, tri, and tetra are used.
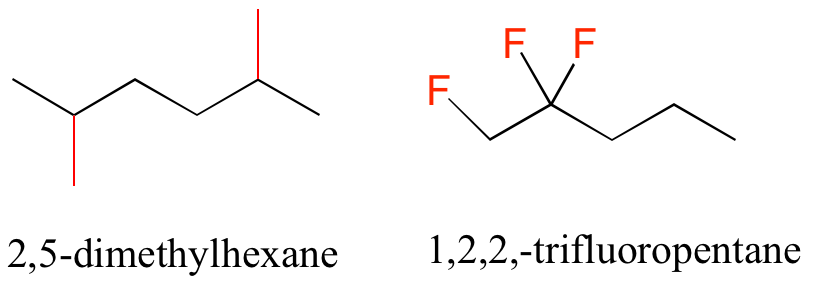
Functional groups have characteristic suffixes. Alcohols, for example, have ‘ol’ appended to the parent chain name, along with a number designating the location of the hydroxyl group. Ketones are designated by ‘one’.

Alkenes are designated with an ‘ene’ ending, and when necessary the location and geometry of the double bond are indicated. Compounds with multiple double bonds are called dienes, trienes, etc.

Some groups can only be present on a terminal carbon, and thus a locating number is not necessary: aldehydes end in ‘al’, carboxylic acids in ‘oic acid’, and carboxylates in ‘oate’.

Ethers and sulfides are designated by naming the two groups on either side of the oxygen or sulfur.

If an amide has an unsubstituted –NH2 group, the suffix is simply ‘amide’. In the case of a substituted amide, the group attached to the amide nitrogen is named first, along with the letter ‘N’ to clarify where this group is located. Note that the structures below are both based on a three-carbon (propan) parent chain.

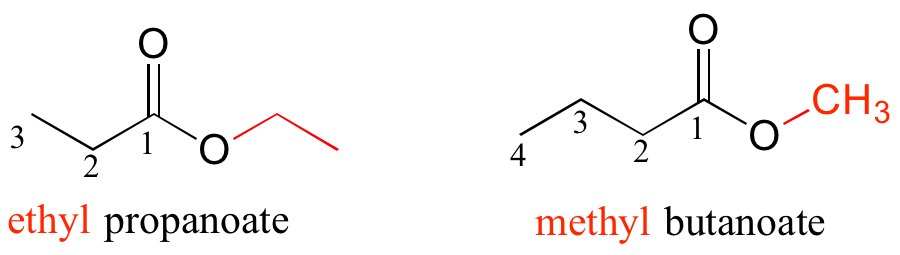
For esters, the suffix is ‘oate’. The group attached to the oxygen is named first.
All of the examples we have seen so far have been simple in the sense that only one functional group was present on each molecule. There are of course many more rules in the IUPAC system, and as you can imagine, the IUPAC naming of larger molecules with multiple functional groups, ring structures, and substituents can get very unwieldy very quickly. The illicit drug cocaine, for example, has the IUPAC name ‘methyl (1R,2R,3S,5S)-3-(benzoyloxy)-8-methyl-8-azabicyclo[3.2.1] octane-2-carboxylate’ (this name includes designations for stereochemistry).

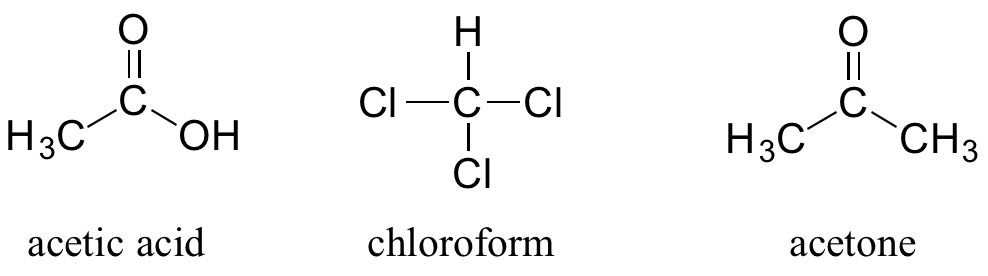
You can see why the IUPAC system is not used very much in biochemistry – the molecules are just too big and complex. A further complication is that, even outside of a biological context, many simple organic molecules are known almost universally by their ‘common name’, rather than IUPAC names. The compounds acetic acid, chloroform, and acetone are only a few examples.
In biochemistry, nonsystematic names (like ‘cocaine’, ‘capsaicin’, ‘pyruvate’ or ‘ascorbic acid’) are usually used, and when systematic nomenclature is employed it is often specific to the class of molecule in question: different systems have evolved, for example, for fats and for carbohydrates. We will not focus very intensively in this text on IUPAC nomenclature or any other nomenclature system, but if you undertake a more advanced study in organic or biological chemistry you may be expected to learn one or more naming systems in some detail.
(Back to the Top)

{kind=link}
{kind=link}
{kind=link}
{kind=link}
References:
Chapter 5 materials have been adapted and modified from the following creative commons resources unless otherwise noted:
1. Wikibooks. (2015) Organic Chemistry. Available at: https://en.wikibooks.org/wiki/Organic_Chemistry.
2. Clark, J. (2014) How to Draw Organic Molecules. Available at: http://chem.libretexts.org/Core/Organic_Chemistry/Fundamentals/How_to_Draw_Organic_Molecules
(2016).
Organic Chemistry With a Biological Emphasis . Published under Creative Commons by-nc-sa 3.0.
4. Anonymous. (2012) Introduction to Chemistry: General, Organic, and Biological (V1.0). Published under Creative Commons by-nc-sa 3.0. Available at: http://2012books.lardbucket.org/books/introduction-to-chemistry-general-organic-and-biological/index.html