Home » Student Resources » Online Chemistry Textbooks » CH103: Allied Health Chemistry » CH103 – Chapter 6: Natural Products and Organic Chemistry
MenuCH103: Allied Health Chemistry
Chapter 6: Natural Products and Organic Chemistry
This text is published under creative commons licensing. For referencing this work, please click here.
6.1 Definition and Uses
6.2 Primary metabolites
6.3 Lipids
6.4 Carbohydrates
6.5 Proteins
6.6 Nucleic Acids
6.7 Secondary metabolites
6.8 Where Do We Find Secondary Natural Products?
6.9 Chapter Summary
6.10 References
6.1 Definition and Uses
What is a natural product chemistry and why should we be interested in studying it? The broadest definition of a natural product is anything that is produced by life, and includes biotic materials (e.g. wood, silk), bio-based materials (e.g. bioplastics, cornstarch), bodily fluids (e.g. milk, plant exudates), and other natural materials that were once found in living organisms (e.g. soil, coal). A more restrictive definition of a natural product is any organic compound that is synthesized by a living organism. The science of organic chemistry, in fact, has its origins in the study of natural products, and has given rise to the fields of synthetic organic chemistry where scientists create organic molecules in the laboratory, and semi-synthetic organic chemistry where scientists modify existing natural products to improve or alter their activities.
Natural products have high structural diversity and unique pharmacological or biological activities due to the natural selection and evolutionary processes that have shaped their utility over hundreds of thousands of years. In fact, the structural diversity of natural products far exceeds the capabilities of synthetic organic chemists within the laboratory. Thus, natural products have been utilized in both traditional and modern medicine for treating diseases. Currently, natural products are often used as starting points for drug discovery followed by synthetic modifications to help reduce side effects and increase bioavailabilty. In fact, natural products are the inspiration for approximately half of U.S. Food and Drug Administration (FDA) approved drugs. In addition to medicine, natural products and their derivatives are commonly used as food additives in the form of spices and herbs, antibacterial agents, and antioxidants to protect food freshness and longevity. In fact, natural organic products find their way into almost every facet of our lives, from the clothes on our backs, to plastics and rubber products, health and beauty products, and even the energy we use to power our automobiles.
Natural products may be classified according to their biological function, biosynthetic pathway, or their source. They are often divided into two major classes: primary and secondary metabolites. Primary metabolites are organic molecules that have an intrinsic function that is essential to the survival of the organism that produces them (i.e. the organism would die without these metabolites). Examples of primary metabolites include the core building block molecules (nucleic acids, amino acids, sugars, and fatty acids) required to make the major macromolecules (DNA, RNA, proteins, carbohydrates, and lipids) responsible for sustaining life. Many hormones, neurotransmitters, and other chemical messengers are also primary metabolites. Secondary metabolites in contrast are organic molecules that typically have an extrinsic function that mainly affects other organisms outside of the producer. Secondary metabolites are not essential to survival but do increase the competitiveness of the organism within its environment.
Natural products, especially within the field of organic chemistry, are often defined as primary and secondary metabolites. A more restrictive definition limiting natural products to secondary metabolites is commonly used within the fields of medicinal chemistry and pharmacognosy, where the study and use of natural products is in the discovery of new medicinal treatments.
6.2 Primary metabolites
Primary metabolites are components of basic metabolic pathways that are required for life. They are associated with essential cellular functions such as nutrient assimilation, energy production, and growth/development. They have a wide species distribution that span many phyla and frequently more than one kingdom. Primary metabolites include the building blocks required to make the four major macromolecules within the body: carbohydrates, lipids, proteins, and nucleic acids (DNA and RNA).
These are large polymers of the body that are built up from repeating smaller monomer units (Fig. 6.1). The monomer units for building the nucleic acids, DNA and RNA, are the nucleotide bases, whereas the monomers for proteins are amino acids, for carbohydrates are sugar residues, and for lipids are fatty acids or acetyl groups.
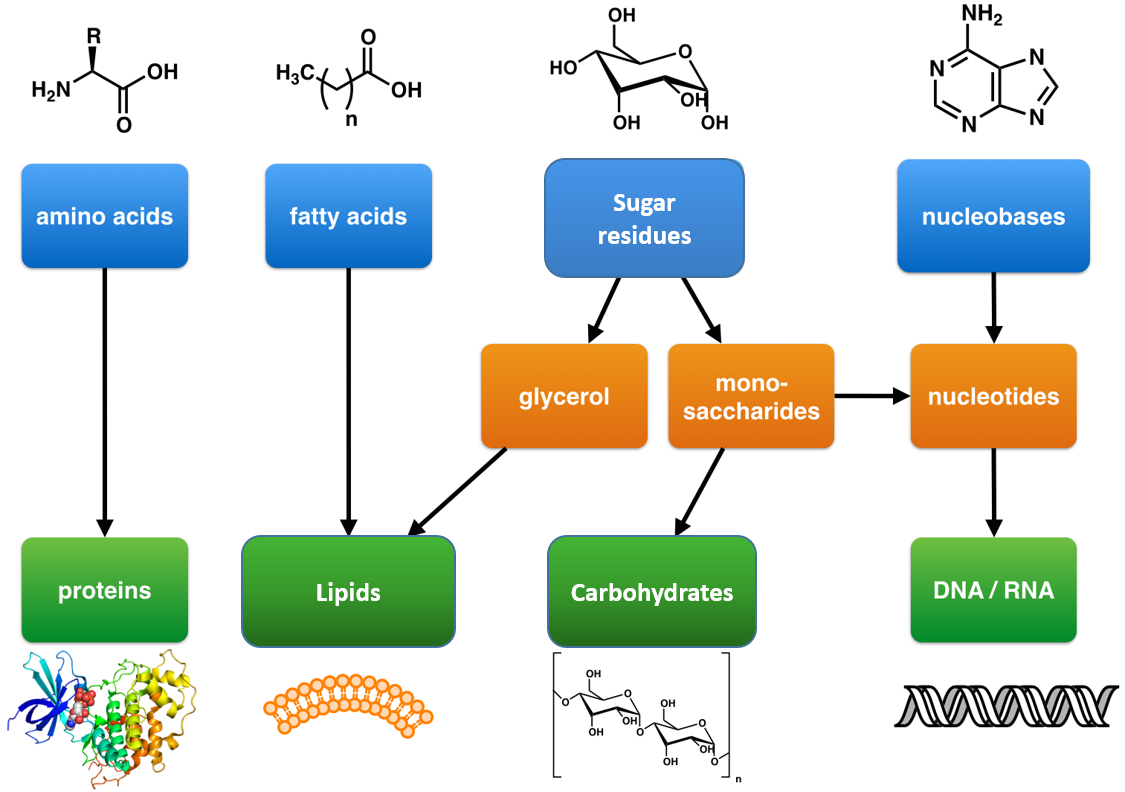
Figure 6.1: The Molecular building blocks of life are made from organic compounds.
Modified from: Boghog
Primary metabolites that are involved with energy production include numerous enzymes that breakdown food molecules, such as carbohydrates and lipids, and capture the energy released in molecules of adenosine triphosphate (ATP). Enzymes are biological catalysts that speed up the rate of chemical reactions. Typically they are proteins, which are composed of amino acid building blocks. The basic structure of cells and of organisms are also composed of primary metabolites. These include cell membranes (e.g. phospholipids), cell walls (e.g. peptidoglycan, chitin), and cytoskeletons (proteins). DNA and RNA which store and transmit genetic information are composed of nucleic acid primary metabolites. Primary metabolites also include molecules involved in cellular signaling, communication and transport. The next few sections will discuss the four major macromolecules in greater detail.
6.3 Lipids
Lipids are a diverse group of compounds that are united by a common feature. Lipids are hydrophobic (“water-fearing”), or insoluble in water. Lipids perform many different functions in a cell. Cells store energy for long-term use in the form of lipids called triacylglycerides. Lipids also provide insulation from the environment for plants and animals. For example, they help keep aquatic birds and mammals dry because of their water-repelling nature. Lipids are also the building blocks of many hormones and are an important constituent of the plasma membrane. Lipids include fats, oils, waxes, phospholipids, and steroids.

Figure 6.2 The Importance of Lipids in Nature. Water birds, such as Larus argentatus shown here, maintain and waterproof their feathers by smoothing with an oily substance produced by the uropygial gland located near the anus.
Photo By Lamiot – Own work, CC BY 2.5, https://commons.wikimedia.org/w/index.php?curid=1383465
Fats and oils are primarily composed of triacylglycerides (TAGS). These macromolecules consist of two main components—glycerol and fatty acids. Glycerol is an organic alcohol that contains three carbons, five hydrogens, and three hydroxyl (OH) groups. Fatty acids have a long chain of hydrocarbons to which a carboxylic acid group (a carboxyl-) is attached, hence the name “fatty acid.” The number of carbons in the fatty acid may range from 4 to 36; most common are those containing 12–18 carbons. In a TAG, three fatty acids are attached to the glycerol molecule through the alcohol functional groups. This reaction, termed dehydration synthesis, is accompanied with the release of water and will be covered in more detail in chapter 7.
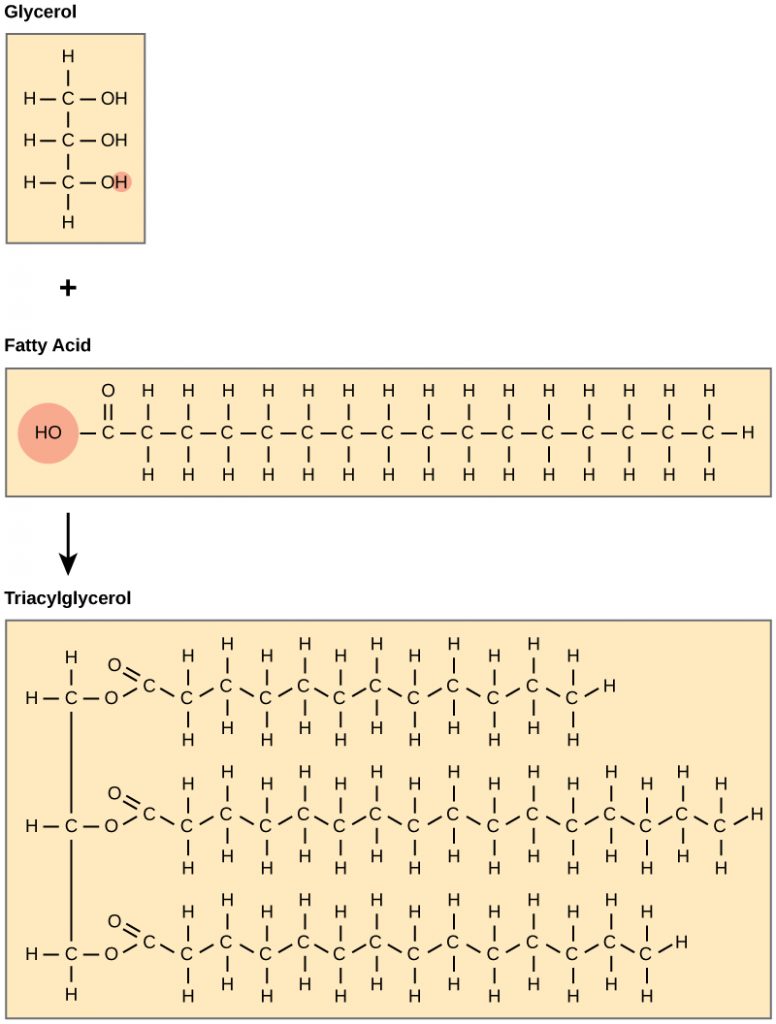 Figure 6.3 Formation of Triacylglycerides (TAGS). Triacylglycerides (TAGS) are formed by the joining of three fatty acids to a glycerol backbone in a dehydration reaction (remember this removes a water molecule and forms a covalent bond). Three molecules of water are released in the process.
Figure 6.3 Formation of Triacylglycerides (TAGS). Triacylglycerides (TAGS) are formed by the joining of three fatty acids to a glycerol backbone in a dehydration reaction (remember this removes a water molecule and forms a covalent bond). Three molecules of water are released in the process.
The fatty acids that make up TAGS can be either saturated (containing only C-C single bonds) or they can be unsaturated (containing some C-C double bonds). Terms such as saturated fat or unsaturated oil are often used to describe the fats or oils obtained from foods. Saturated fats contain a high proportion of saturated fatty acids and are typically solids at room temperature, while unsaturated oils contain a high proportion of unsaturated fatty acids and are typically liquids at room temperature. This is due to the intermolecular forces present in the different kinds of fats. The most common type of Unsaturated fatty acids found in nature contain double bonds in the cis conformation. This causes bends in the fatty acid chain that do not allow the chains to stack upon one another. This keeps them from forming stronger London Dispersion interactions that are seen in the tighter stacking of saturated fatty acids (Figure 6.4). Thus, unsaturated fats in the cis conformation tend to have lower melting temperatures than saturated fatty acids and are liquids at room temperature. Unsaturated fats that have trans double bonds do not have bends in their chain and can still stack in a similar fashion to saturated fats. Thus, unsaturated trans fatty acids tend to be solids at room temperature. Cis unsaturated fatty acids are common in nature, while trans unsaturated fatty acids are rare. Trans-unsaturated fatty acids are typically a by-product of food processing or deep-fat frying. The high consumption of saturated fats or trans-unsaturated fats is a factor, along with the high consumption of cholesterol, in increased risks of heart disease.
![]()
Figure 6.4 Saturated and Unsaturated Fatty Acids. Saturated fatty acids only contain carbon-carbon single bonds and thus, can stack on one another forming many London Dispersion intermolecular interactions (dashed lines). Unsaturated fatty acids in the cis conformation have bends in their chains that prevent them from stacking and forming substantial London Dispersion bonds. Thus, they tend to have lower melting temperatures and are liquids at room temperature. Unsaturated fatty acids in the trans conformation, do not have bends and thus, can stack and form London Dispersion interactions similar to that of saturated fatty acids.
(back to the top)
Waxes
Waxes are produced by many different plants and animals. Waxes made by animals are typically esters of fatty acids, as shown in Figure 6.5, whereas those made by plants are commonly mixtures of unesterified hydrocarbons. Plants commonly use waxes on the cuticles of plant leaves where they can repel water. Bees use wax to form their intricate honeycombs, and the sperm whale produces large amounts of waxes and oils called spermaceti. The spermaceti organ is located in the head of the sperm whale, where it can hold large amounts of oil. The sperm whale is capable of heating and lowering the temperature of the spermaceti oils and waxes, helping the whale control its buoyancy in the ocean. Heating the oil lowers its density and allows the whale to float, whereas lowering the temperature increases the density and allows the whale to sink again. In the late 1800’s and early 1900’s sperm whale oil was considered the finest lubricating oil on Earth, and was used for the lubrication of fine machinery, such as pocket watches.

Figure 6.5 Examples of Waxes in Nature. (A) A typical wax ester contains two long chain hydrocarbons joined by an ester linkage. (B) Photo of water beading on the waxy cuticle of a kale leaf. (C) honeycomb made of beeswax, and (D) Spermaceti wax sample, a spemaceti candle, and spermaceti oil from the head of a sperm whale. (B) Courtesy of Rei at en.wikipedia, (C) Courtesy of Boutet, E. and (D) Courtesy of Einzelheiten zur Genehmigung
Phospholipids
Phospholipids are major constituents of the plasma membrane, the outermost layer of animal cells. Like TAGS, they are composed of fatty acid chains covalently bonded to a glycerol or sphingosine backbone. Instead of three fatty acids attached as in TAGS, however, there are two fatty acids forming diacylglycerol, and the third carbon of the glycerol backbone is occupied by a modified phosphate group (Figure 6.6).
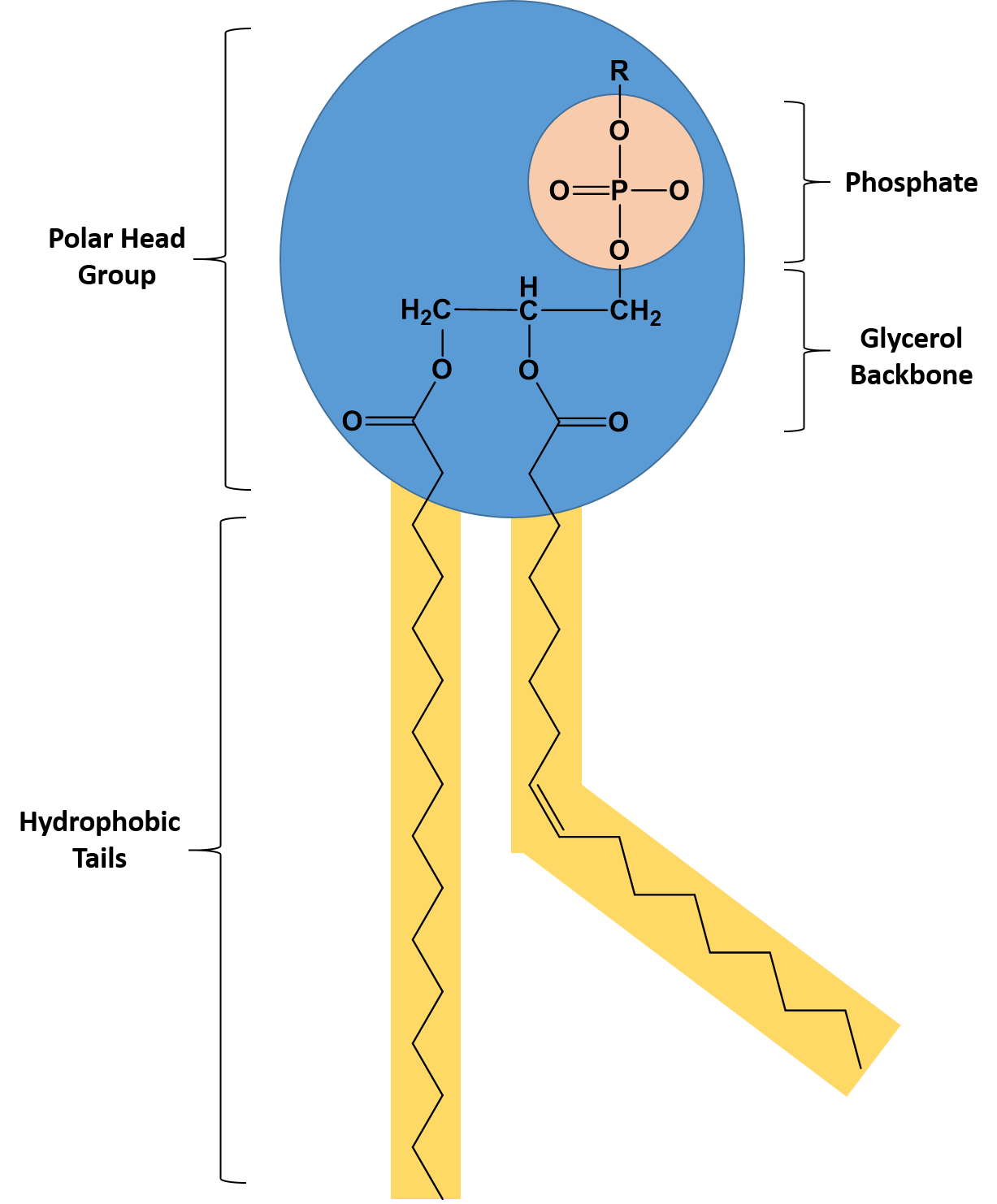
Figure 6.6 The Structure of a Phospholipid. A phospholipid is a molecule with two fatty acids and a modified phosphate group attached to a glycerol backbone. The phosphate may be modified by the addition of charged or polar chemical groups at the position designated with an R.
A phospholipid is an amphipathic molecule, meaning it has both a hydrophobic and a hydrophilic part. The fatty acid chains are hydrophobic and cannot interact with water, whereas the phosphate-containing group is hydrophilic and interacts with water (Figure 6.7). The head is the hydrophilic part, and the tail contains the hydrophobic fatty acids. In a membrane, a bilayer of phospholipids forms the matrix of the structure, the fatty acid tails of phospholipids face inside, away from water, whereas the phosphate group faces the outside, aqueous side. This forms a hydrophobic layer on the inside of the bilayer, where the tails are located.
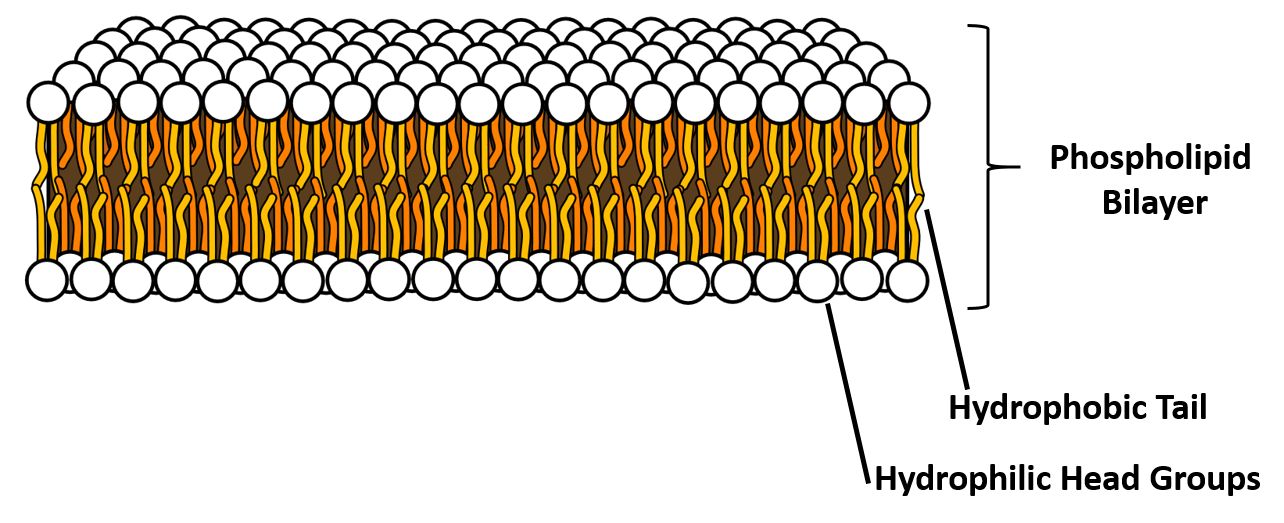
Figure 6.7 The phospholipid bilayer is the major component of all cellular membranes. The hydrophilic head groups of the phospholipids face the aqueous solution. The hydrophobic tails are sequestered in the middle of the bilayer. Credit AmitWo, Wikimedia; https://commons.wikimedia.org/wiki/File:Micelle.svg
Phospholipids are responsible for the dynamic nature of the plasma membrane. There are proteins embedded within the plasma membrane that function in the transport of molecules across the membrane or that can receive signals and serve as receptors in cell-to-cell communication (Figure 6.8). Due to the oily nature of the hydrophobic tails, the plasma membrane retains a fluid nature where the embedded proteins can move laterally from one area to another, much like they are swimming in the membrane. This is known as the fluid mosaic model. Note that some proteins extend all the way through the plasma membrane and these are called integral membrane proteins. Others are found only attached to the extracellular side or the intracellular side of the membrane. These proteins are known as peripheral membrane proteins. In addition to proteins, carbohydrates can also be attached to either lipids (glycolipids) or proteins (glycoproteins) within the plasma membrane. Carbohydrates often serve as recognition signals for cell-to-cell communication.
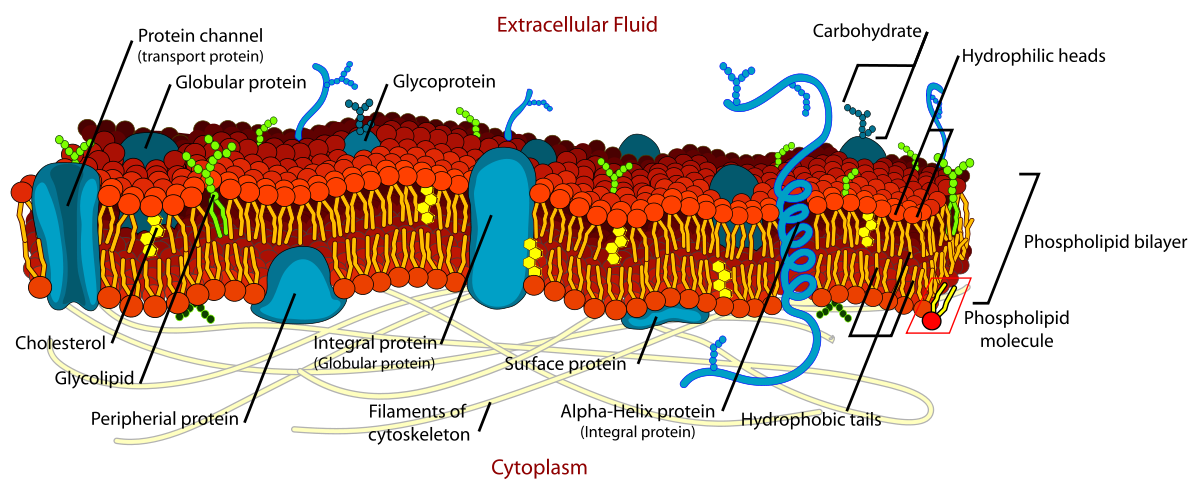
Figure 6.8. The Fluid Mosaic Model of the Plasma Membrane. The plasma membane core structure is the phospholipid bilayer. Embedded within this core structure are integral and peripheral membrane proteins. The proteins within the plasma membrane can move laterally through the plasma membrane. Carbohydrates are often attached to either lipids or proteins within the plasma membrane where they play a role in cell-to-cell communication.
(back to the top)
Steroids
Unlike the phospholipids and TAGS discussed earlier, steroids have a fused ring structure. Although they do not resemble the other lipids, they are grouped with them because they are also hydrophobic and insoluble in water. All steroids have four linked carbon rings and several of them, like cholesterol, have a short tail (Figure 6.9). Many steroids also have the –OH functional group, which puts them in the alcohol classification (sterols). Remember that each line in these diagrams of chemical structures represents a covalent bond. The points where the lines connect to each other show the location of carbon atoms – these carbon atoms are not labeled, but their existence is implied in the chemical structure.
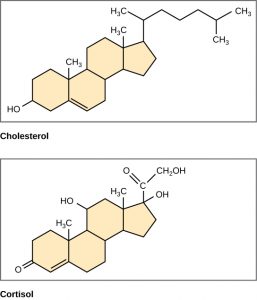
Figure 6.9 Steroids such as cholesterol and cortisol are composed of four fused hydrocarbon rings.
Cholesterol is the most common steroid. Cholesterol is mainly synthesized in the liver and is the precursor to many steroid hormones such as testosterone and estradiol, as well as to Vitamin D. Cholesterol is also the precursor for bile salts, which help in the emulsification of fats during the digestion process. and their subsequent absorption by cells. Although cholesterol is often spoken of in negative terms by lay people, it is necessary for proper functioning of the body. It is a component of the plasma membrane of animal cells and is found within the phospholipid bilayer where it regulates the rigidity of the plasma membrane. At high temperatures, cholesterol helps to stabilize the membrane and raise the melting temperature. At low temperatures, cholesterol keeps the hydrophobic tails from clustering together and stiffening too much.
Overall, lipids make up important cellular structures, such as the plasma membrane, are critical in cell-to-cell communication where they often serve as hormones or localized signaling molecules. Hormones are any molecule that is produced in one area of the body, is secreted into the blood stream where it travels to a distant location to mediate its effect. Testosterone and estradiol are good examples of steroid hormones. Lipids, such at TAGS, are also essential for providing energy for the body. Chapter 8 will look more closely at the regulation TAG and carbohydrate energy sources.
(back to the top)
6.4 Carbohydrates
Carbohydrates are macromolecules with which most consumers are somewhat familiar. To lose weight, some individuals adhere to “low-carb” diets. Athletes, in contrast, often “carb-load” before important competitions to ensure that they have sufficient energy to compete at a high level. Carbohydrates are, in fact, an essential part of our diet; grains, fruits, and vegetables are all natural sources of carbohydrates. Carbohydrates provide energy to the body, particularly through glucose, a simple sugar. Carbohydrates also have other important functions in humans, animals, and plants, including cell recognition, structural support, and by providing cushioning support in the extracellular matrix of joints.

Figure 6.10 Bread, pasta, and sugar all contain high levels of carbohydrates. (“Wheat products” by US Department of Agriculture is in the Public Domain)
Carbohydrates can be represented by the stoichiometric formula (CH2O)n, where n is the number of carbons in the molecule. In other words, the ratio of carbon to hydrogen to oxygen is 1:2:1 in carbohydrate molecules. This formula also explains the origin of the term “carbohydrate”: the components are carbon (“carbo”) and water (hence, “hydrate”). Thus, compared with lipids, carbohydrates are much more polar and many are soluble in water. Carbohydrates are classified into three subtypes: monosaccharides, disaccharides, and polysaccharides.
Monosaccharides
Monosaccharides (mono- = “one”; sacchar- = “sweet”) are simple sugars, the most common of which is glucose. In monosaccharides, the number of carbons usually ranges from three to seven. Most monosaccharide names end with the suffix -ose.
The chemical formula for glucose is C6H12O6. In humans, glucose is an important source of energy. During cellular respiration, energy is released from glucose, and that energy is used to help make adenosine triphosphate (ATP). Plants synthesize glucose using carbon dioxide and water, and glucose in turn is used for energy requirements for the plant. Excess glucose is often stored as starch that is catabolized (the breakdown of larger molecules by cells) by humans and other animals that feed on plants.
Galactose (part of lactose, or milk sugar) and fructose (found in sucrose, in fruit) are other common monosaccharides and also share the same molecular formula as glucose, C6H12O6. Although glucose, galactose, and fructose all have the same chemical formula (C6H12O6), they differ structurally and chemically (and are known as isomers) because of the different arrangement of functional groups around the asymmetric carbon; all of these monosaccharides have more than one asymmetric carbon. The glucose-fructose pair and galactose-fructose pair are structural isomers as the bonding order of their atoms differ. Glucose and galactose on the otherhand are stereoisomers, as they have the same bonding order, but a different 3-dimensional arrangement in space. In addition, you can see that glucose and galactose each have an aldehyde functional group, whereas fructose has a ketone functional group. Sugars that contain aldehyde functional groups are called aldoses, whereas sugars that have ketone functional groups are called ketoses.
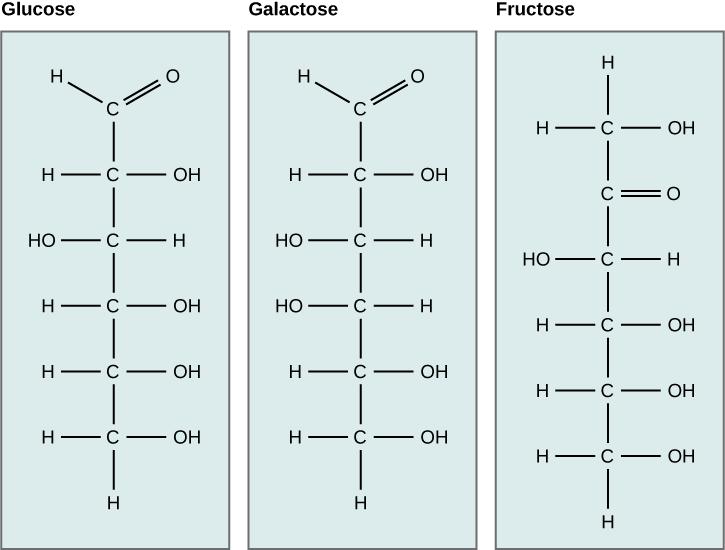
Figure 6.11 Glucose, galactose, and fructose are all hexoses. They are structural isomers, meaning they have the same chemical formula (C6H12O6) but a different arrangement of atoms. Fructose is a ketose sugar, whereas glucose and galactose are aldoses.
Sugars are structurally quite complex because they contain a high number of chiral centers. For example, if you look at glucose in Figure 6.11, you will see that only the first and the last carbons in the chain are achiral. The first carbon is bonded in the aldehyde functional group and therefore contains two bonds to the same oxygen. Thus, it cannot be chiral. Similarly, the 6th carbon is bonded to two hydrogen atoms and also lacks chirality. The remaining four carbons are each bonded to four different substituents and therefore have chirality. Due to the high amount of chirality, sugars often have many isomer possibilities. For example, the number of stereoisomers possible for glucose is 2n, where n = the number of chiral centers. For glucose, n = 4. Thus, there are a total of 2 x 2 x 2 x 2 = 16 possible stereoisomers! Note that we are only listing the stereoisomers, not the vast number of structural isomers that are also possible. Recall that for protein recognition, the shape of the molecule in 3-dimensional space is critical. Thus, since carbohydrates have such a high possibility of isomeric forms, they are ideal components for cell-to-cell recognition, as small changes in the carbohydrate structure can be used for vastly different messages to the surrounding cells.
Note that for every sugar, there will be one other sugar that is exactly opposite at all of the chiral centers of the molecule. This exact opposite is the mirror image of the other sugar, but is not superimposable. This exact opposite is called the enantiomer. Note that enantiomer pairs have all of the same physical properties, except for the direction that they can rotate plain polarized light. Thus, they are very hard to tell apart and to separate from one another. They are in fact, given the same name, with the prefix of D- or L- to designate which way that they rotate plain polarized light. D- is given for sugars that rotate light in the right-handed or dextrorotatory, and L- is given for sugars that rotate light in the left-handed or levorotatory direction. D-sugars are the ones predominantly produced in nature. To distinguish the D- and the L- conformations from one another, look at the chiral center that is farthest from the ketone or aldehyde functional group. If the hydroxyl (-OH) functional group is on the right hand side, it is the D- conformation, if the hydroxyl (-OH) functional group is on the left hand side, it is the L- conformation. The two enantiomers of glucose and fructose are shown below in Figure 6.12 as examples.
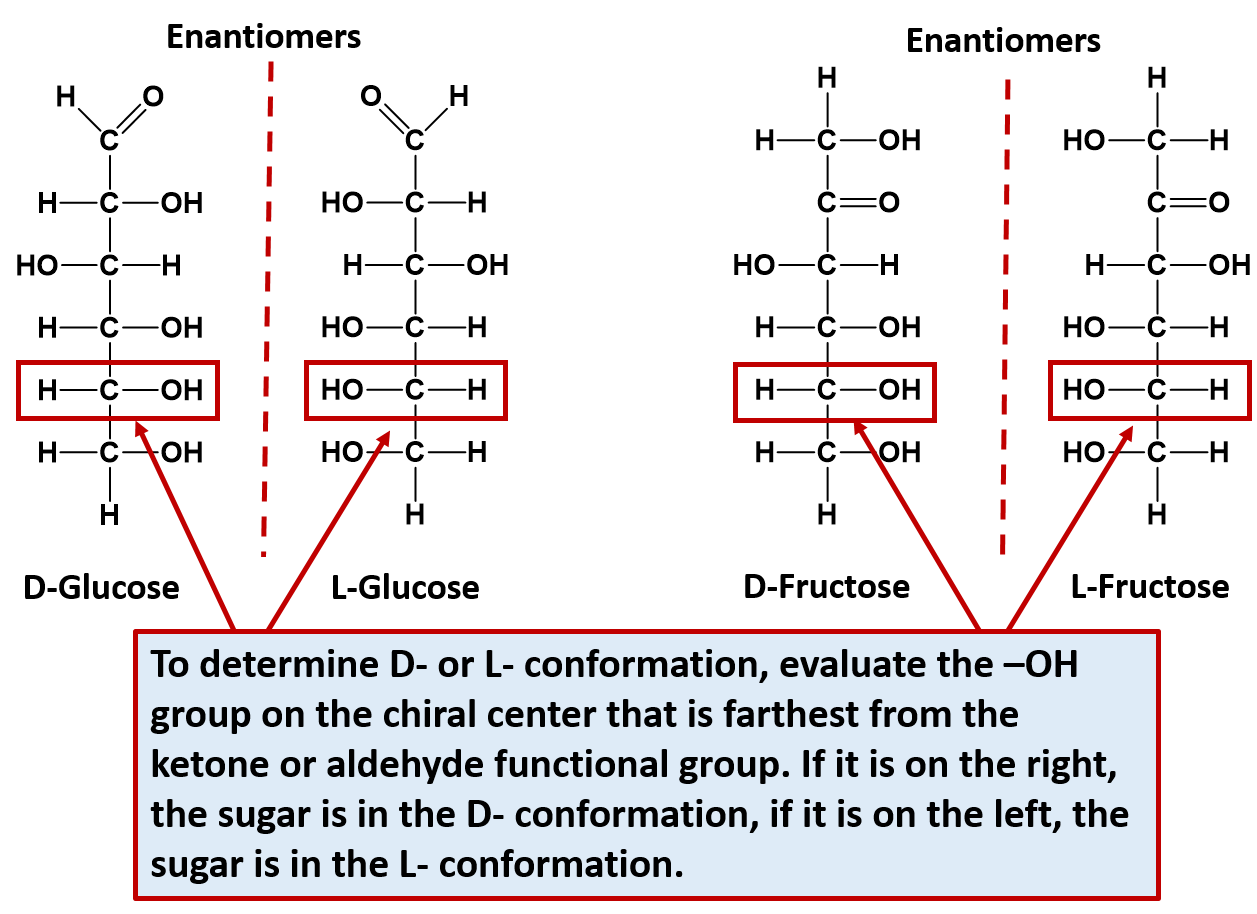
Figure 6.12 Enantiomer Pairs. Enantiomers are stereoisomers that are mirror images of one another but are not superimposable. For monosaccharides, each sugar can exist in the D- or L-conformation depending on which direction they rotate plain polarized light. To determine the D- or L- confomation, evaluate the -OH located on the chiral center farthest away from the ketone or aldehyde functional group. If it is on the right hand side, the sugar is the D- conformation. If it is on the left hand side, it is the L- conformation.
Monosaccharides that have 5 or 6 carbons, will often spontaneously cyclize to form 5- or 6-membered ring structures. When they do this, the carbon of the aldehyde or ketone functional group will accept the incoming bond causing the carbonyl bonded oxygen to become another hydroxyl functional group on the sugar. This introduces one additional chiral center into the molecule and forms another unique pair of isomers that are called anomers. The new anomers are called the alpha (α) and beta (β) conformations. Figure 6.13 demonstrates how glucose cyclizes to form the alpha and beta anomeric forms.
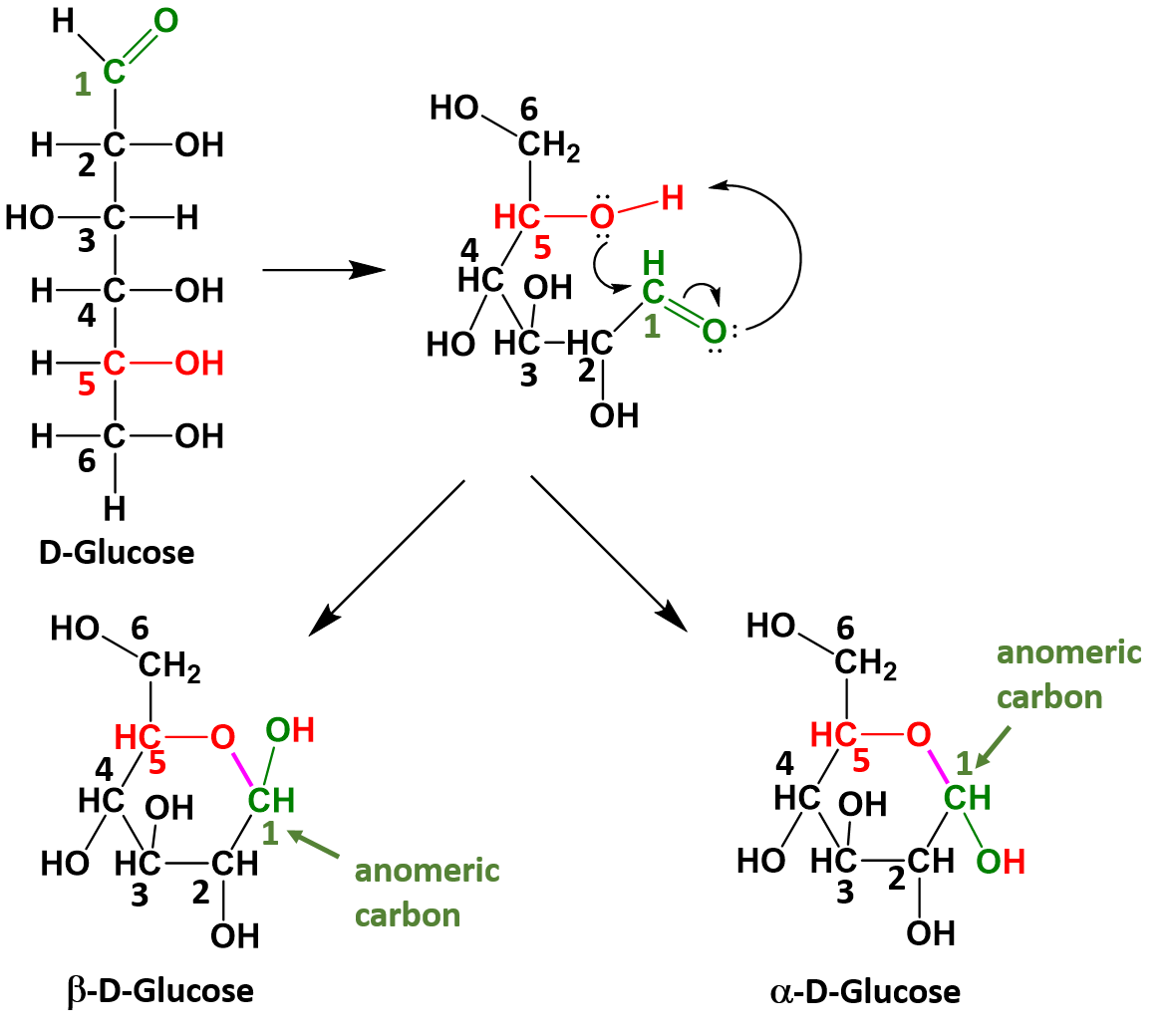
Figure 6.13 Cyclization of Glucose. When glucose cylizes the oxygen from the 5th carbon, shown in red, attacks the carbonyl carbon at position 1, shown in green. This pushes the double bond up onto the carbonyl oxygen which enables the carbonyl oxygen to take the hydrogen from the hydroxyl group on position 5. This forms a new bond, shown in purple between the oxygen at position 5 and the carbon at position 1. The carbon at position 1 is then bonded to two oxygen molecules and is known as the anomeric carbon, shown in green.
Once the linear sugar has cyclized, this forms a new functional group called a hemiacetal (which is essentially a hydroxyl group next to an ether functional group with the anomeric carbon sandwiched in between them. This functional group is represented by the red and green colored atoms present in Figure 6.13. The formation of the hemiacetal is important because this is the reactive functional group that allows for the formation of disaccharides and polysaccharides. This dehydration reaction is covered in more detail in chapter 7.
(back to the top)
Disaccharides
Disaccharides (di- = “two”) form when two monosaccharides undergo a dehydration reaction (also known as a condensation reaction or dehydration synthesis). This reaction will be covered in more detail in Chapter 7. During this process, the hydroxyl (OH) group of the hemiacetal from one monosaccharide combines with the hydrogen from a hydroxyl group of another monosaccharide, releasing a molecule of water and forming a covalent bond which joins the two monosaccharides together through an oxygen linkage. This new bond is called a glycosidic bond. Figure 6.14 shows the formation of the disaccharide maltose from two α-D-glucose monomers.
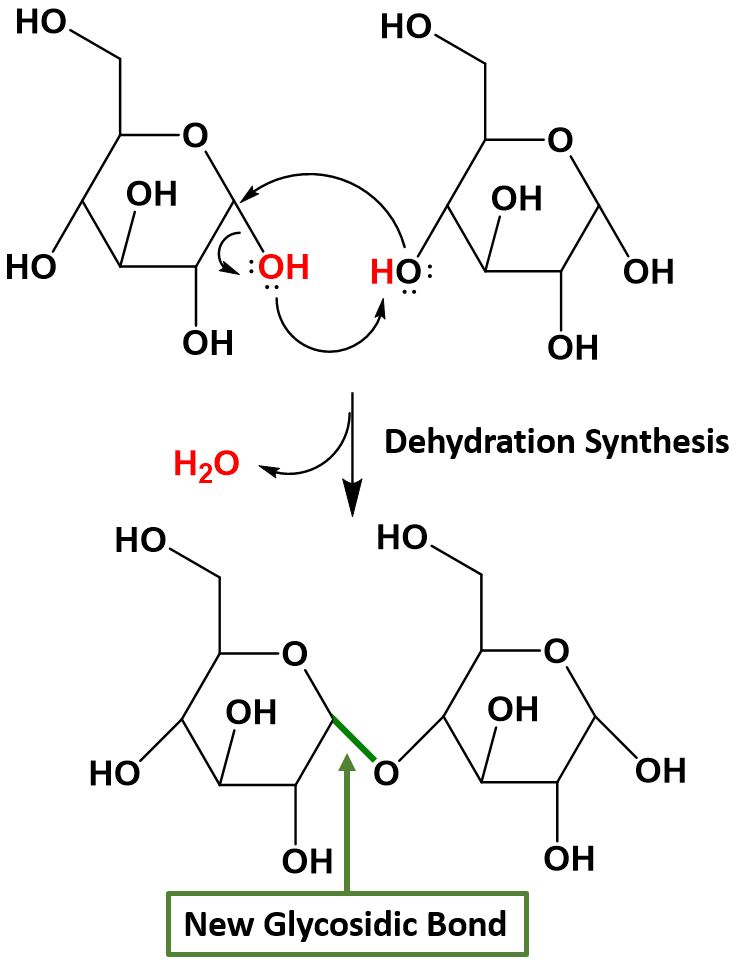
Figure 6.14 Formation of a Glycosidic Bond. In this example, two α-D-glucose monomers combine to form the disaccharide maltose. Glycosidic bonds, shown in green, are formed when two sugars undergo dehydration synthesis joining the sugar molecules through an oxygen linkage. The hydroxyl from the hemiacetal on one sugar, shown in red, combines with a hydrogen from the hydroxyl of another sugar, shown in red, to form the leaving water molecule, shown in red. The remaining oxygen from the hydroxyl group forms the glycosidic bond, shown in green, with the anomeric carbon atom from the first sugar.
Common disaccharides include maltose, lactose, and sucrose (Figure 6.15). Maltose, or malt sugar, is a disaccharide composed of two glucose molecules. It is not commonly produced in nature, but is often a breakdown product when starch is being digested. It is also common in the juice of grains such as barley. Lactose is a disaccharide commonly found in the milk of lactating mammals. Human infants are able to use lactose as a food source because they express the lactase enzyme that is responsible for breaking down the lactose into its monosaccharide units. When growing into adulthood, many people become lactose intolerant because the expression of the lactase enzyme is altered or down regulated. Certain populations of humans originating in Scandanavia and regions in Africa have acquired mutations that have allowed continued expression of the lactase enzyme and enabled the consumption of dairy products into adulthood. The most familiar disaccharide is sucrose, or table sugar, which is composed of the monomers glucose and fructose.
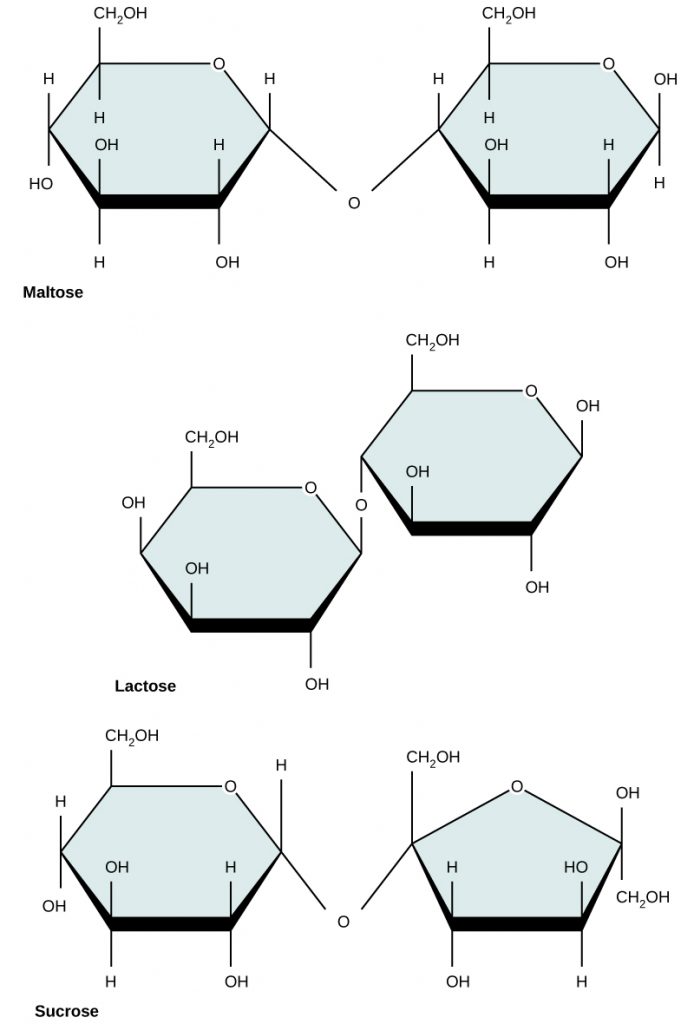
Figure 6.15 Common disaccharides include maltose (grain sugar), lactose (milk sugar), and sucrose (table sugar).
(back to the top)
Polysaccharides
A long chain of monosaccharides linked by glycosidic bonds is known as a polysaccharide (poly- = “many”). The chain may be branched or unbranched, and it may contain different types of monosaccharides. All of the monosaccharides are connected together by covalent glycosidic bonds through the process of dehydration synthesis. The molecular weight may be very large, upwards of 100,000 daltons or more depending on the number of monomers joined. Starch, glycogen, cellulose, and chitin are primary examples of polysaccharides.
Starch is the stored form of sugars in plants and is made up of a mixture of amylose and amylopectin (both polymers of glucose). Amylose is a straight chain of glucose linked together at the α1,4 position (or from the 1-position anomeric carbon on one glucose to the oxygen on the 4 carbon of the next glucose in the chain). Amylopectin is more complex than the amylose, in that it has branching associated with the structure. It has the same α1,4 glucose main chain as the amylose structure, but it also has α1,6 branches about every 25 glucose residues (Figure 6.16). Note that all of the glucose monomers present in both starch and glycogen are in the α-D-conformation. Plants are able to synthesize glucose, and the excess glucose, beyond the plant’s immediate energy needs, is stored as starch in different plant parts, including roots and seeds. The starch in the seeds provides food for the embryo as it germinates and can also act as a source of food for humans and animals. The starch that is consumed by humans is broken down by enzymes, such as salivary amylases, into smaller molecules, such as maltose and glucose. The cells can then absorb and utilize the glucose for energy.
Glycogen is the storage form of glucose in humans and other vertebrates and is very similar in structure to that of amylopectin. Glycogen, however, has a much higher rate of α1,6 branching than amylopectin (with branches occurring about every 10 residues). The need for the higher branching, is that glycogen can only be broken down starting from the ends of the molecule to release single glucose monomers. If there was only one end, as in the amylose molecule, it would take a long time to release glucose that could then be used to create energy needed by muscles and other tissues in the body. By having a branching molecule, there are more ends of the molecule that are useful for the quick breakdown and release of glucose. This is needed in animals that may need quick bursts of energy to elude a predator or chase down prey. Within animals, glycogen is predominantly stored in the liver (about 10% of the mass of the liver is glycogen!) and in muscle cells (approximately 2% of the total mass).
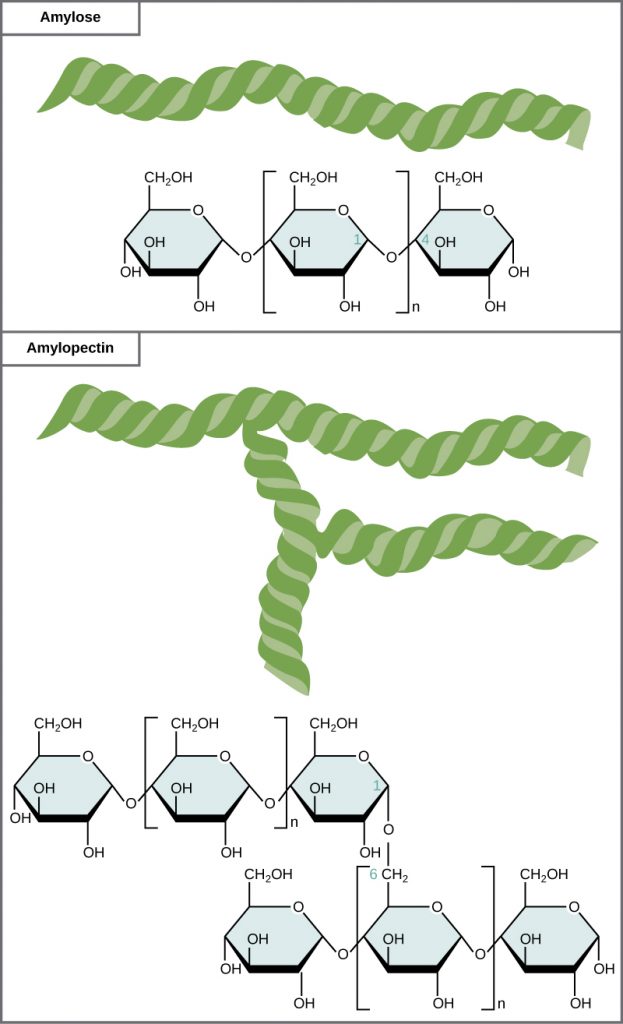
Figure 6.16 Amylose and amylopectin are two different forms of starch. Amylose is composed of unbranched chains of glucose monomers. Amylopectin is composed of branched chains of glucose monomers. Because of the way the subunits are joined, the glucose chains have a helical structure. Glycogen (not shown) is similar in structure to amylopectin but more highly branched.
In addition to being a tasty food, carbohydrate polymers can serve as structural support molecules as well. Cellulose is the most abundant natural carbohydrate and serves as a structural biopolymer. It is made up of β1,4 linkages between the glucose molecules. This creates a linear structure where each glucose monomer is flipped upside down compared with the last. When the fibers from one cellulose strand are then aligned with another fiber they can form strong hydrogen bond interactions that build strong fiber networks (Figure 6.17). The cell wall of plants is mostly made of cellulose; this provides structural support to the cell. Wood and paper are also mostly cellulosic in nature.
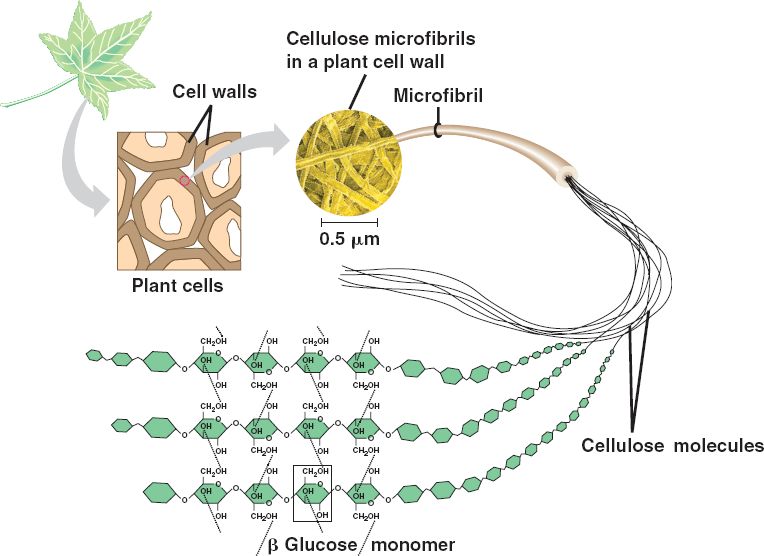
Figure 6.17 In cellulose, glucose monomers are linked in unbranched chains by β1,4 linkages. Because of the way the glucose subunits are joined, every glucose monomer is flipped relative to the next one resulting in a linear structure that can form hydrogen bonds with neighboring strands. The result of the hydrogen bonded strands produces very strong fibrous material.
Figure provided by Marta O. under Creative Commons
Interestingly, the exoskeleton of many insects is made from a modified form of cellulose that is called chitin. Chitin is modified with the incorporation of nitrogen into the sugar structure. The repeating structural units are called N-acetyl-β-d-glucosamine and are shown in Figure 6.18. Chitin is also a major component of fungal cell walls; fungi are neither animals nor plants and form a kingdom of their own in the domain Eukarya. Polymers containing N-acetyl-β-d-glucosamine also occur in humans where they are present in extracellular matrix and provide cushioning for joints. In fact, N-acetyl-β-d-glucosamine is one of the most prominent dietary supplements sold in the United States, provided to support joint health.
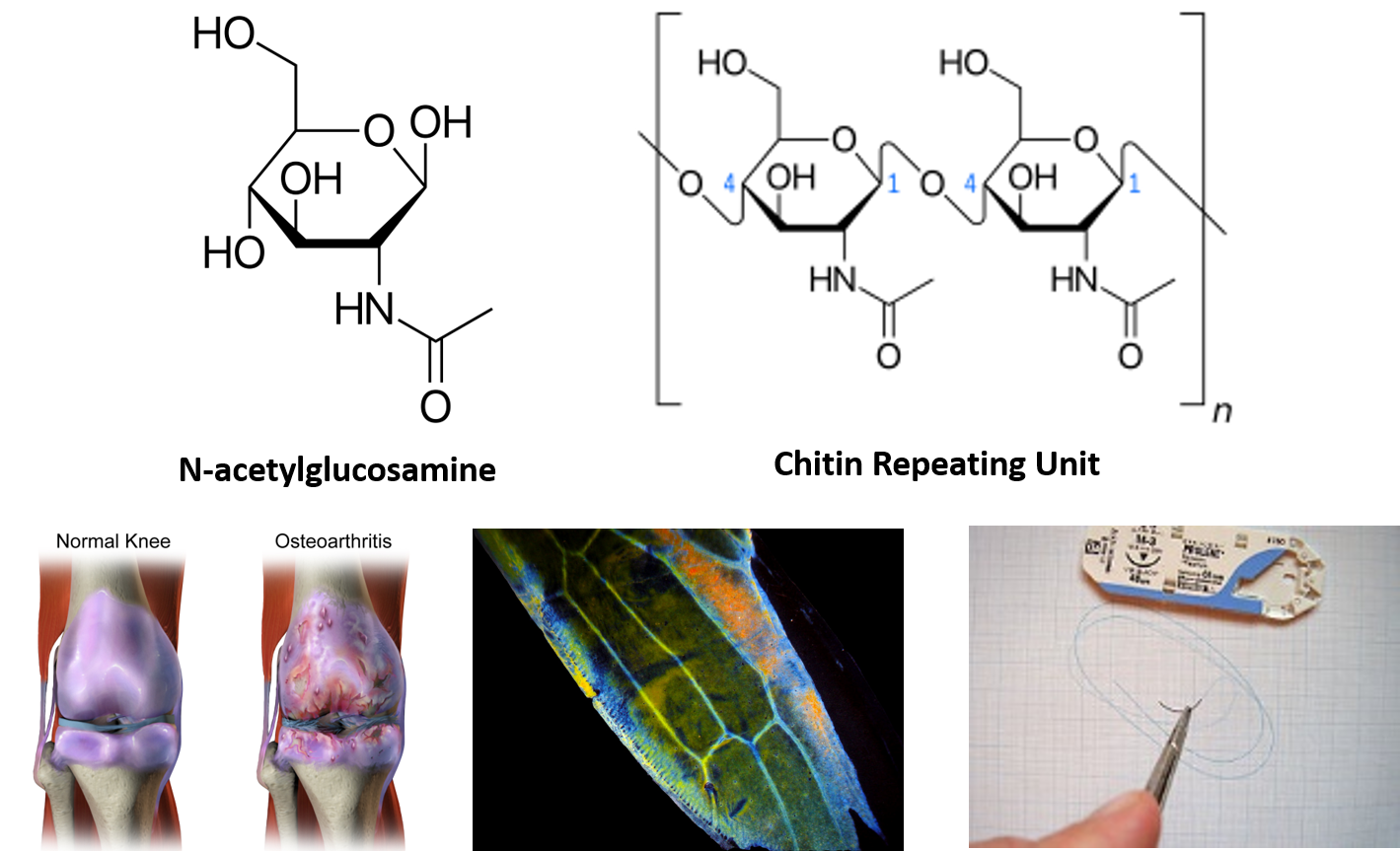
Figure 6.18 N-acetyl-β-d-glucosamine is a common modified sugar in polysaccharides. N-acetyl-β-d-glucosamine (upper left) is the repeating sugar unit in the polymer, chitin (upper right). N-acetyl-β-d-glucosamine is a component of normal joint cushioning (lower left). Chitin is a primary polysaccharide in the hard exoskeleton of insects as shown in the wing of the leafhopper (middle photo). Chitin has been utilized in medical technology to serve as material for surgical sutures. It provides a self dissolving matrix that will last about two weeks in the body.
lower left photo provided by BruceBlaus middle photo provided by Zituba, and lower right photo provided by Werneuchen
Learn more about chitin and its role in the insect world from this video by Nancy Miorelli
Access more great insect tutorials from Entomologist Explains, by Nancy Miorelli
(back to the top)
6.5 Proteins
Proteins are one of the most abundant organic molecules in living systems and have the most diverse range of functions of all macromolecules. Proteins may be structural, regulatory, contractile, or protective; they may serve in transport, storage, or membranes; or they may be toxins or enzymes. Each cell in a living system may contain thousands of different proteins, each with a unique function. Their structures, like their functions, vary greatly. They are all, however, polymers of amino acids, arranged in a linear sequence and connected together by covalent bonds.
Amino Acids and Primary Protein Structure
The major building block of proteins are called alpha (α) amino acids. As their name implies they contain a carboxylic acid functional group and an amine functional group. The alpha designation is used to indicate that these two functional groups are separated from one another by one carbon group. In addition to the amine and the carboxylic acid, the alpha carbon is also attached to a hydrogen and one additional group that can vary in size and length. In the diagram below, this group is designated as an R-group. Within living organisms there are 20 amino acids used as protein building blocks. They differ from one another only at the R-group position. The basic structure of an amino acid is shown below:
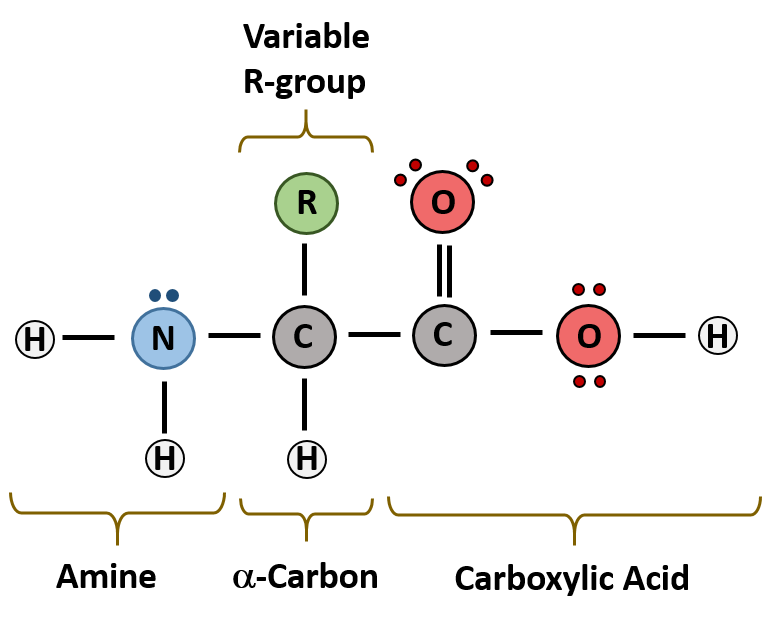
Figure 6.19 General Structure of an Alpha Amino Acid
Within cellular systems, proteins are linked together by a large enzyme complex that contains a mixture of RNA and proteins. This complex is called the ribosome. Thus, as the amino acids are linked together to form a specific protein, they are placed within a very specific order that is dictated by the genetic information contained within the messenger RNA molecule. This specific ordering of amino acids is known as the protein’s primary sequence. The primary sequence of a protein is linked together using dehydration synthesis that combine the carboxylic acid of the upstream amino acid with the amine functional group of the downstream amino acid to form an amide linkage (Figure 6.20). Within protein structures, this amide linkage is known as the peptide bond. Subsequent amino acids will be added onto the carboxylic acid terminal of the growing protein. Thus, proteins are always synthesized in a directional manner starting with the amine and ending with the carboxylic acid tail. New amino acids are always added onto the carboxylic acid tail, never onto the amine of the first amino acid in the chain. The directionality of protein synthesis is dictated by the ribosome. In addition, because the R-groups can be quite bulky, they usually alternate on either side of the growing protein chain in the trans conformation. The cis conformation is only preferred with one specific amino acid known as proline.
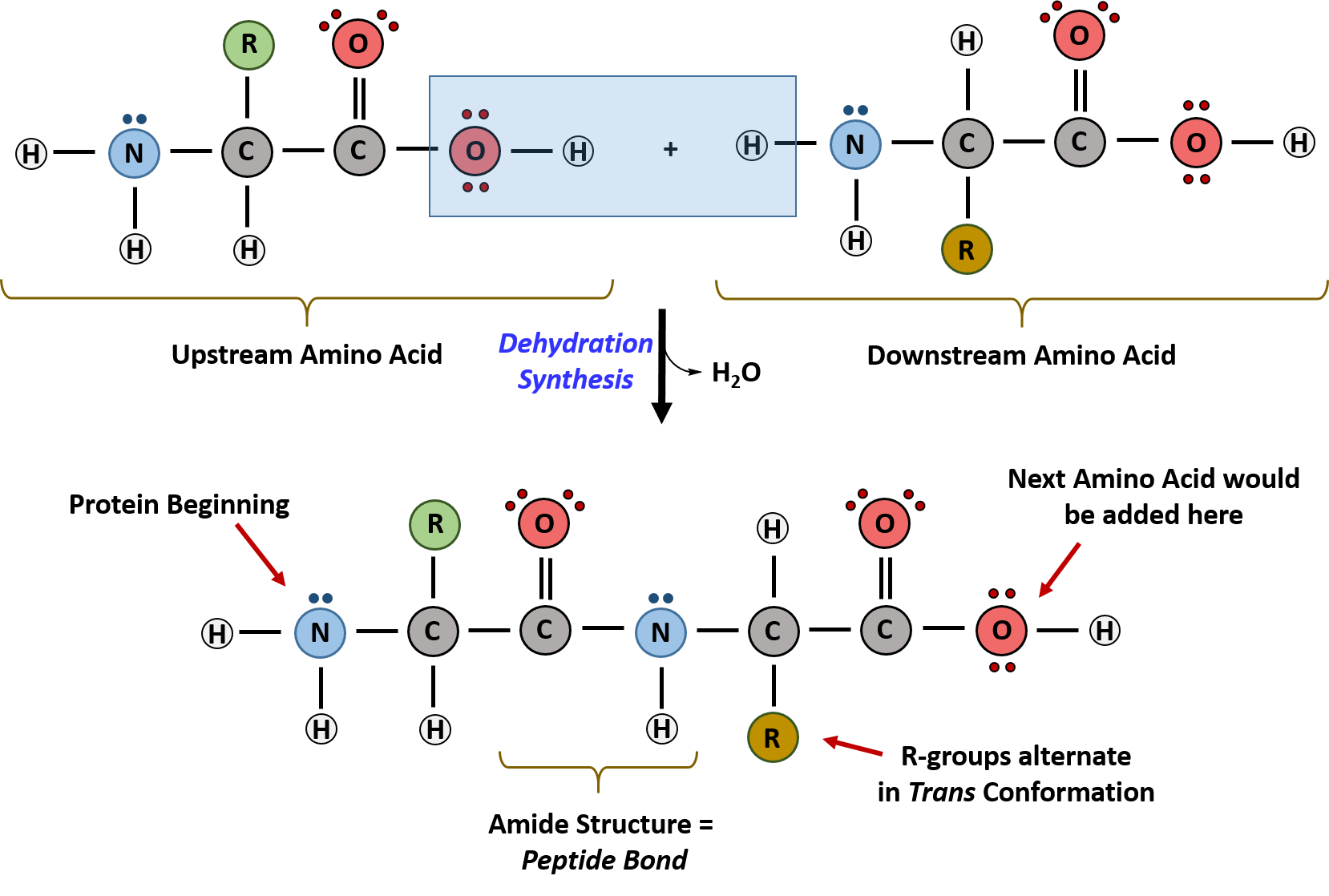
Figure 6.20 Formation of the Peptide Bond. The addition of two amino acids to form a peptide requires dehydration synthesis.
Proteins are very large molecules containing many amino acid residues linked together in very specific order. Proteins range in size from 50 amino acids in length to the largest known protein containing 33,423 amino acids. Macromolecules with fewer than 50 amino acids are known as peptides.

Figure 6.21 Peptides and Proteins are macromolecules built from long chains of amino acids joined together through amide linkages.
The identity and function of a peptide or a protein is determined by the primary sequence of amino acids within its structure. There are a total of 20 alpha amino acids that are commonly incorporated into protein structures (Figure 6.22). The different R-groups have different characteristics based on the nature of atoms incorporated into the functional groups. There are R-groups that only contain carbon and hydrogen and are very nonpolar or hydrophobic. Others contain polar uncharged functional groups such as alcohols, amides, and thiols. A few amino acids are basic (containing amine functional groups) or acidic (containing carboxylic acid functional groups). These amino acids are capable of forming full charges and can have ionic interactions. The order and nature of amino acids in the primary sequence of a protein determine the folding pattern of the protein based on the surrounding environment of the protein (ie if it is inside the cell, it is likely surrounded by water in a very polar environment, whereas if the protein is embedded in the plasma membrane, it will be surrounded by very nonpolar hydrocarbon tails).
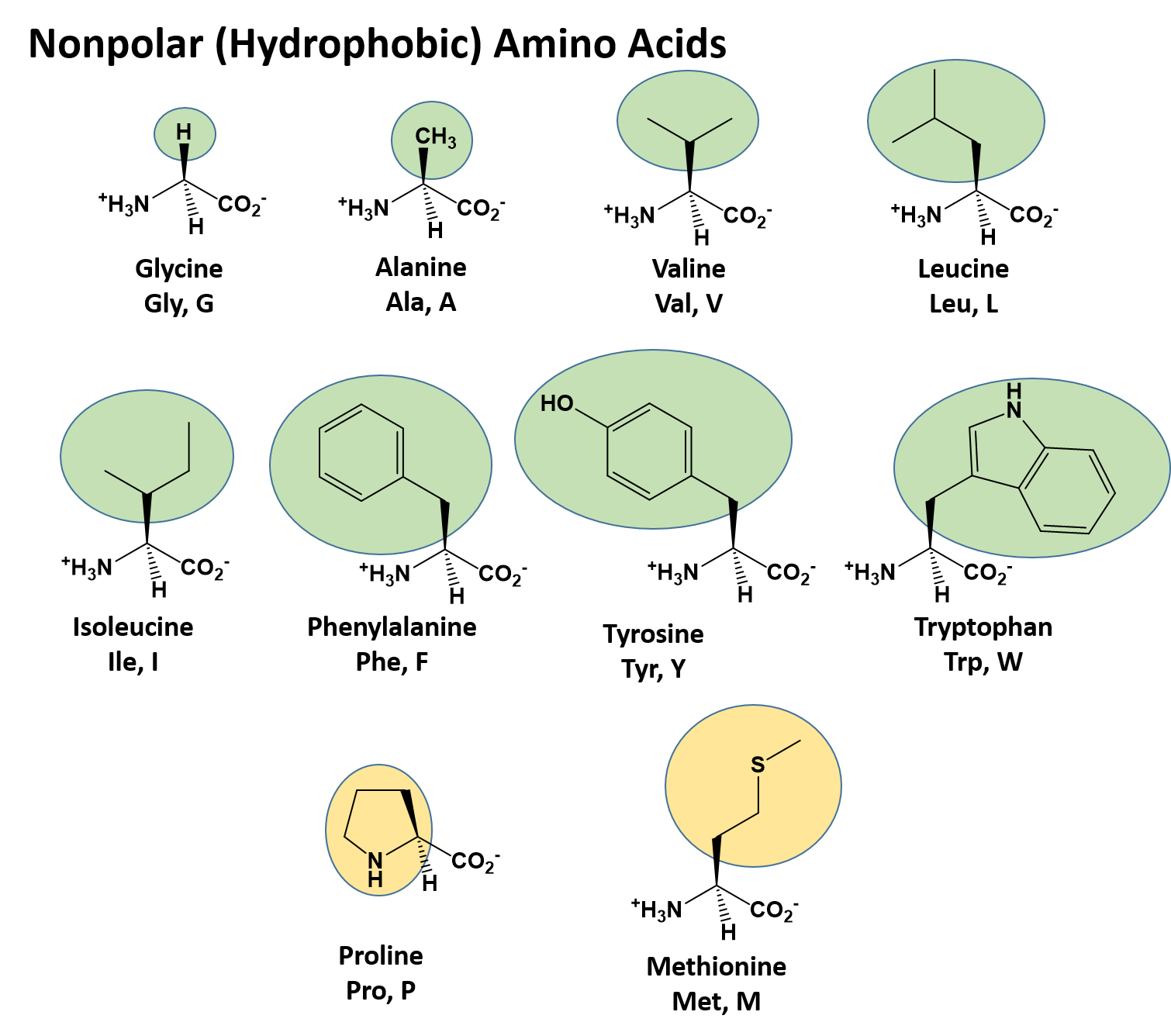
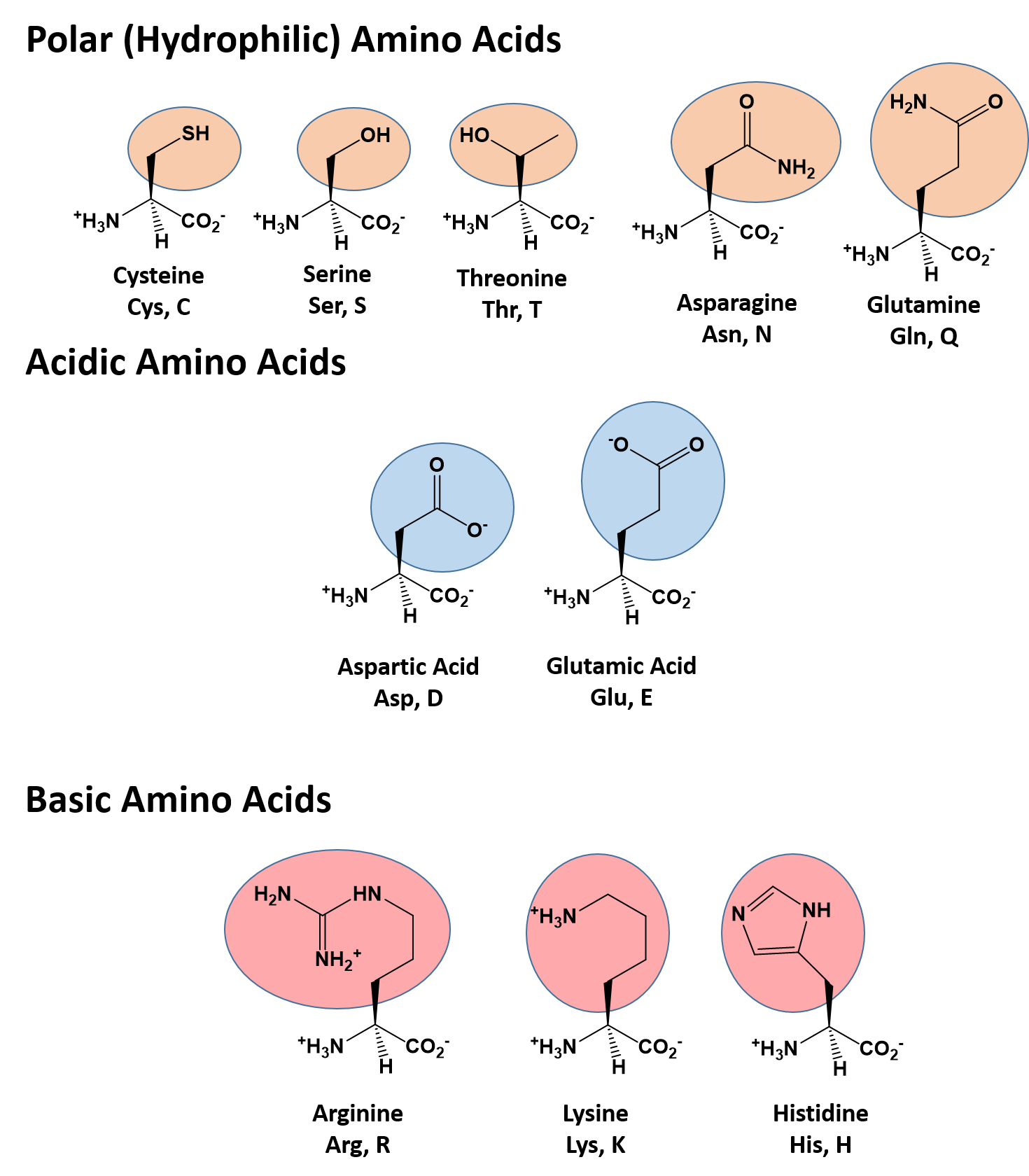
Figure 6.22 Structure of the 20 Alpha Amino Acids used in Protein Synthesis.
(back to the top)
Due to the large pool of amino acids that can be incorporated at each position within the protein, there are billions of different possible protein combinations that can be used to create novel protein structures! For example, think about a tripeptide made from this amino acid pool. At each position there are 20 different options that can be incorporated. Thus, the total number of resulting tripeptides possible would be 20 X 20 X 20 or 203, which equals 8,000 different tripeptide options! Now think about how many options there would be for a small peptide containing 40 amino acids. There would be 2040 options, or a mind boggling 1.09 X 1052 potential sequence options! Each of these options would vary in the overall protein shape, as the nature of the amino acid side chains helps to determine the interaction of the protein with the other residues in the protein itself and with its surrounding environment.
The character of the amino acids throughout the protein help the protein to fold and form its 3-dimentional structure. It is this 3-D shape that is required for the functional activity of the protein (ie. protein shape = protein function). For proteins found inside the watery environments of the cell, hydrophobic amino acids will often be found on the inside of the protein structure, whereas water-loving hydrophilic amino acids will be on the surface where they can hydrogen bond and interact with the water molecules. Proline is unique because it has the only R-group that forms a cyclic structure with the amine functional group in the main chain. This cyclization is what causes proline to adopt the cis conformation rather than the trans conformation within the backbone. This shift is structure will often mean that prolines are positions where bends or directional changes occur within the protein. Methionine is unique, in that it serves as the starting amino acid for almost all of the many thousands of proteins known in nature. Cysteines contain thiol functional groups and thus, can be oxidized with other cysteine residues to form covalent disulfide bonds within the protein structure (Figure 6.23). Disulfide bridges add additional stability to the 3-D structure and are often required for correct protein folding and function (Figure 6.23).
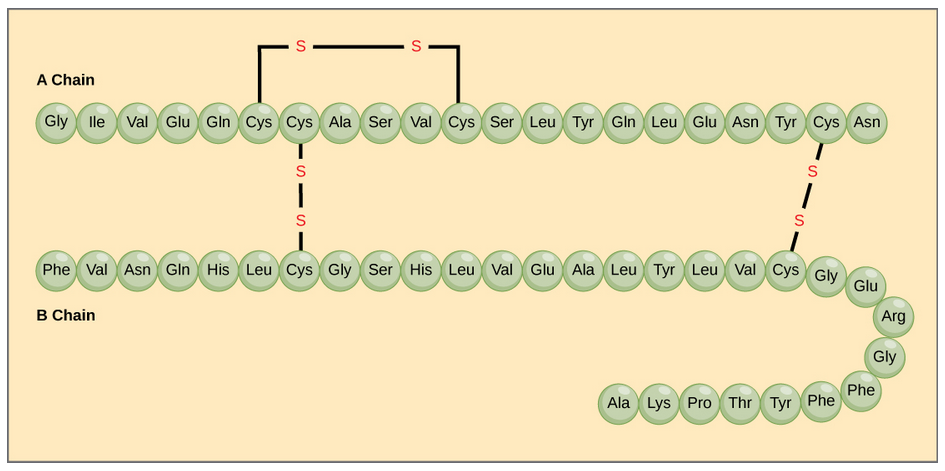
Figure 6.23 Disulfide Bonds. Disulfide bonds are formed between two cysteine residues within a peptide or protein sequence or between different peptide or protein chains. In the example above the two peptide chains that form the hormone insulin are depicted. Disulfide bridges between the two chains are required for the proper function of this hormone to regulate blood glucose levels.
Protein Shape and Function
The primary structure of each protein leads to the unique folding pattern that is characteristic for that specific protein. Recall that this is the linear order of the amino acids as they are linked together in the protein chain (Figure 6.24).
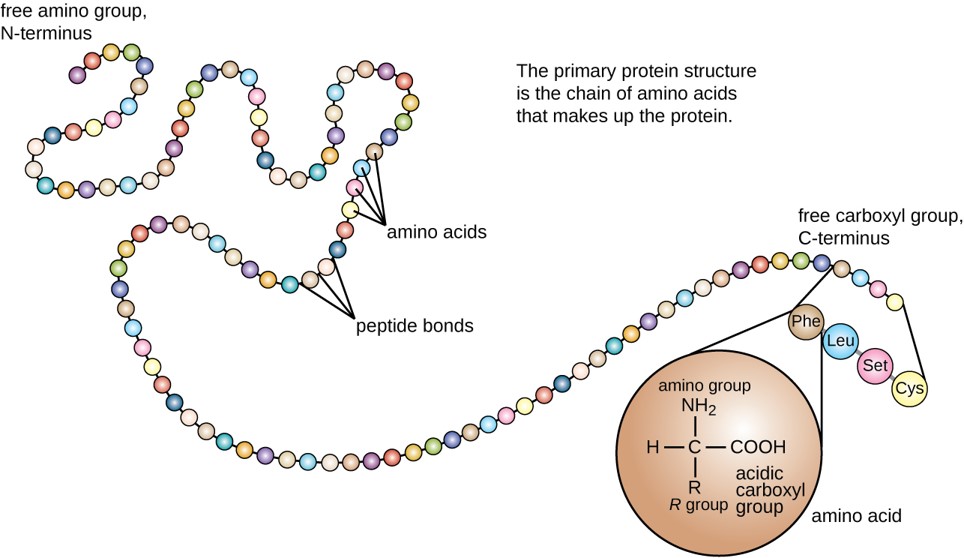
Figure 6.24 Primary protein structure is the linear sequence of amino acids.
(credit: modification of work by National Human Genome Research Institute)
Within each protein small regions may adopt specific folding patterns. These specific motifs or patterns are called secondary structure. Common secondary structural features include alpha helix and beta-pleated sheet (Figure 6.25). Within these structures, intramolecular interactions, especially hydrogen bonding between the backbone amine and carbonyl functional groups are critical to maintain 3-dimensional shape. Every helical turn in an alpha helix has 3.6 amino acid residues. The R groups (the variant groups) of the polypeptide protrude out from the α-helix chain. In the β-pleated sheet, the “pleats” are formed by hydrogen bonding between atoms on the backbone of the polypeptide chain. The R groups are attached to the carbons and extend above and below the folds of the pleat. The pleated segments align parallel or antiparallel to each other, and hydrogen bonds form between the partially positive nitrogen atom in the amino group and the partially negative oxygen atom in the carbonyl group of the peptide backbone. The α-helix and β-pleated sheet structures are found in most proteins and they play an important structural role.
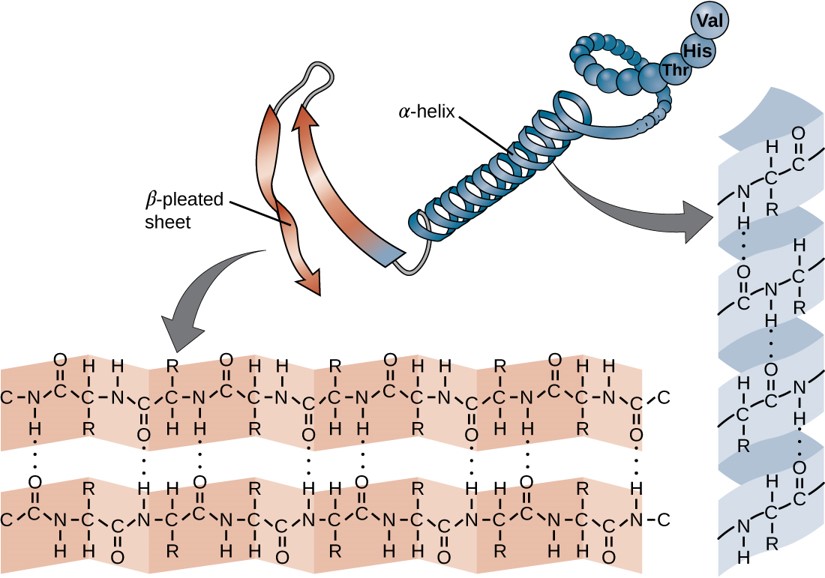
Figure 6.25 Secondary Structural Features in Protein Structure. The alpha helix and beta-pleated sheet are common structural motifs found in most proteins. They are held together by hydrogen bonding between the amine and the carbonyl oxygen within the amino acid backbone.
A Closer Look: Secondary Protein Structure in Silk
There were many trade routes throughout the ancient world. The most highly traveled and culturally significant of these was called the Silk Road. The Silk Road ran from the Chinese city of Chang’an all the way through India and into the Mediterranean and Egypt. The reason that the Silk road was so culturally significant was because of the great distance that it covered. Essentially the entire ancient world was connected by one trade route.

Figure 6.26 Silkworms
On the route many things were traded, including silk, spices, slaves, ideas, and gun powder. The silk road had an astounding effect on the creation of many societies. It was able to bring economic wealth into areas along the route, and new ideas traveled the distance and influence many things including art. An example of this is Buddhist art that was found in India. The painting has many western influences that can be identified in it, such as realistic musculature of the people being painted. Also, the trade of gun powder to the West helped influence warfare, and in turn shaped the modern world. The real reason the Silk Road was started though was for the product that it takes its name from: Silk.
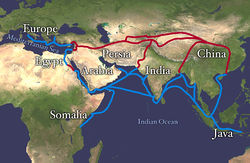
Figure 6.27 Land route in Red, Sea route in Blue
Silk was prized by the Kings and Queens of both European and Middle Eastern Society. The Silk showed that the rulers had power and wealth because the silk was not easy to come by, and therefore was definitely not cheap. Silk was first developed in China, and is made by harvesting the silk from the cocoons of the mulberry silkworm. The silk itself is called a natural protein fiber because it is composed of a pattern of amino acids in a secondary protein structure. The secondary structure of silk is the beta pleated sheet. The primary structure of silk contains the amino acids of glycine, alanine, serine, in specific repeating pattern. These three amino acids make up 90% of the protein in silk. The last 10% is comprised of the amino acids glutamic acid, valine, and aspartic acid. These amino acids are used as side chains and affect things such as elasticity and strength. they also vary between various species. The beta pleated sheet of silk is connected by hydrogen bonds. The hydrogen bonds in the silk form beta pleated sheets rather than alpha helixes because of where the bonds occur. The hydrogen bonds go from the amide hydrogens on one protein chain to the corresponding carbonyl oxygen across the way on the other protein chain. This is in contrast to the alpha helix because in that structure the bonds go from the amide to the carbonyl oxygen, but they are not adjacent. The carbonyl oxygen is on the amino acid that is four residues before.
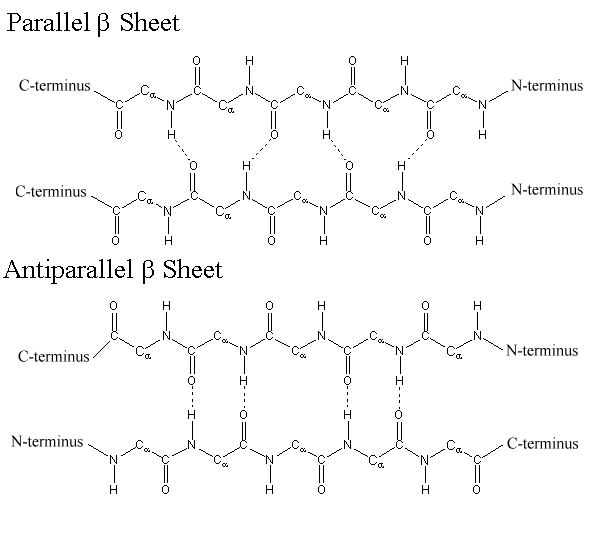
Figure 6.28 Parallel and Antiparallel Beta-Pleated Sheets
Silk is a great example of the beta pleated sheet structure. The formation of this secondary structure in the silk protein allows it to have very strong tensile strength. Silk also helped to form one of the greatest trading routes in history, allowing for the exchange of ideas, products and cultures while advancing the societies that were involved. Silk contains both anti-parallel and parallel arrangements of beta sheets. Unlike the α helix, though, the side chains are squeezed rather close together in a pleated-sheet arrangement. In consequence very bulky side chains make the structure unstable. This explains why silk is composed almost entirely of glycine, alanine, and serine, the three amino acids with the smallest side chains. Some species of silk worm produce varying amounts of bulky side chains, but these silks are not as prized as the mulberry silkworm (which has no bulky amino acid side chains) because the silk with bulky side chains is weaker and doesn’t have as much tensile strength.
(back to the top)
The complete 3-dimensional shape of the entire protein (or sum of all the secondary structures) is known as the tertiary structure of the protein and is a unique and defining feature for that protein (Figure 6.29). Primarily, the interactions among R groups creates the complex three-dimensional tertiary structure of a protein. The nature of the R groups found in the amino acids involved can counteract the formation of the hydrogen bonds described for standard secondary structures. For example, R groups with like charges are repelled by each other and those with unlike charges are attracted to each other (ionic bonds). When protein folding takes place, the hydrophobic R groups of nonpolar amino acids lay in the interior of the protein, whereas the hydrophilic R groups lay on the outside. The former types of interactions are also known as hydrophobic interactions. Interaction between cysteine side chains forms disulfide linkages in the presence of oxygen, the only covalent bond forming during protein folding.

Figure 6.29 Tertiary Protein Structure. The tertiary structure of proteins is determined by a variety of chemical interactions. These include hydrophobic interactions, ionic bonding, hydrogen bonding and disulfide linkages.
All of these interactions, weak and strong, determine the final three-dimensional shape of the protein. When a protein loses its three-dimensional shape, it is usually no longer be functional.
In nature, some proteins are formed from several polypeptides, also known as subunits, and the interaction of these subunits forms the quaternary structure. Weak interactions between the subunits help to stabilize the overall structure. For example, insulin (a globular protein) has a combination of hydrogen bonds and disulfide bonds that cause it to be mostly clumped into a ball shape. Insulin starts out as a single polypeptide and loses some internal sequences during cellular processing that form two chains held together by disulfide linkages as shown in figure 6.23. Three of these structures are then grouped further forming an inactive hexamer (Figure 6.30). The hexamer form of insulin is a way for the body to store insulin in a stable and inactive conformation so that it is available for release and reactivation in the monomer form.
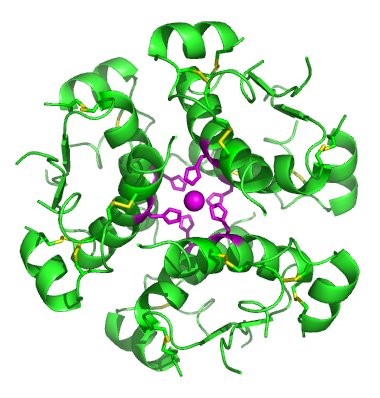
Figure 6.30 The Insulin Hormone is a Good Example of Quaternary Structure. Insulin is produced and stored in the body as a hexamer (a unit of six insulin molecules), while the active form is the monomer. The hexamer is an inactive form with long-term stability, which serves as a way to keep the highly reactive insulin protected, yet readily available.
Figure By: Isaac Yonemoto
The four levels of protein structure (primary, secondary, tertiary, and quaternary) are summarized in Figure 6.31.

Figure 6.31 The four levels of protein structure can be observed in these illustrations. (credit: modification of work by National Human Genome Research Institute)
Hydrolysis is the breakdown of the primary protein sequence by the addition of water to reform the individual amino acids monomer units.
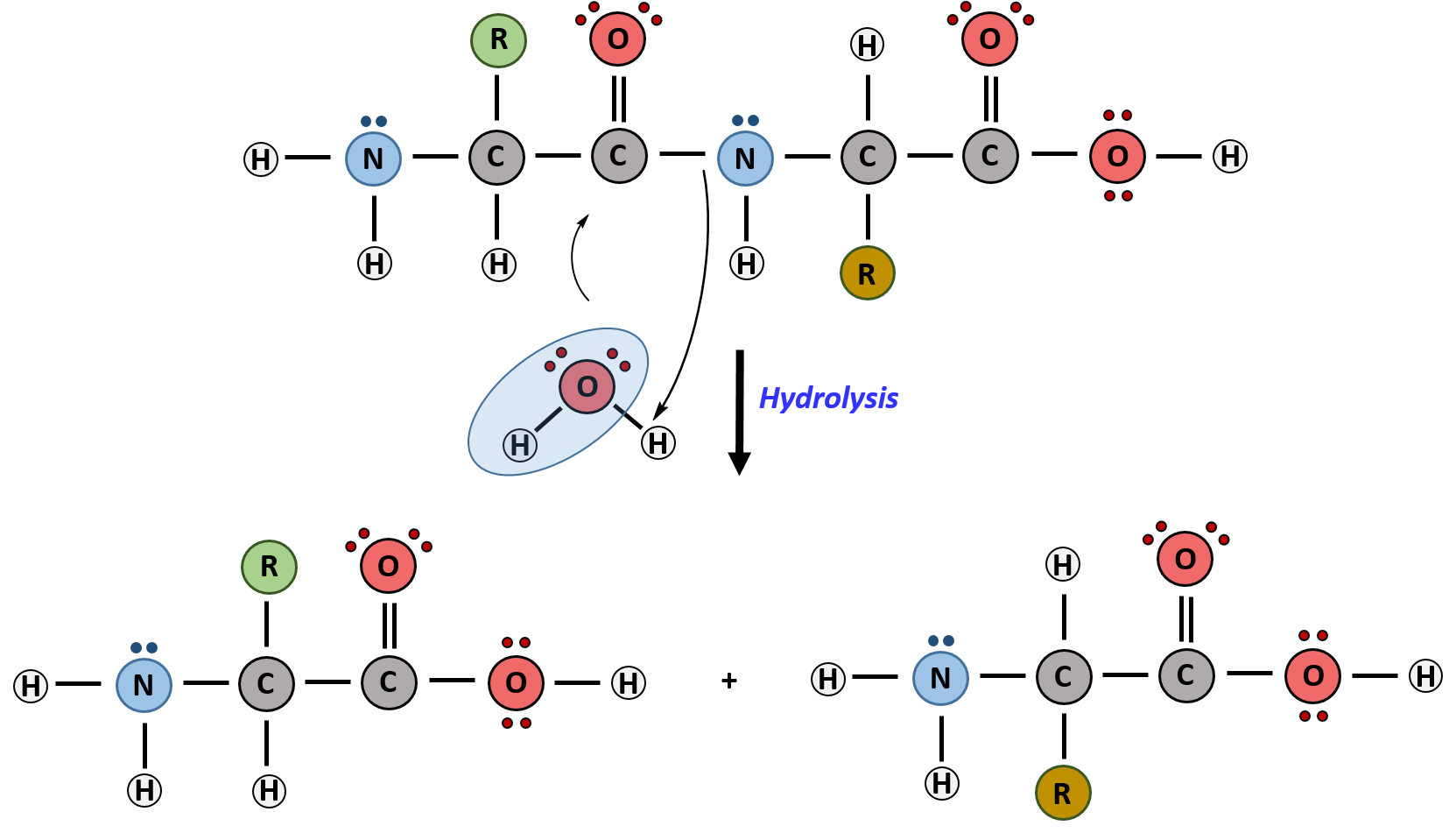
Figure 6.32 Hydrolysis of Proteins. In the hydrolysis reaction, water is added across the amide bond incorporating the -OH group with the carbonyl carbon and reforming the carboxylic acid. The hydrogen from the water reforms the amine.
If the protein is subject to changes in temperature, pH, or exposure to chemicals, the protein structure may unfold, losing its shape without breaking down the primary sequence in what is known as denaturation (Figure 6.33). Denaturation is different from hydrolysis, in that the primary strcture of the protein is not affected. Denaturation is often reversible because the primary structure of the polypeptide is conserved in the process if the denaturing agent is removed, allowing the protein to refold and resume its function. Sometimes, however, denaturation is irreversible, leading to a permanent loss of function. One example of irreversible protein denaturation is when an egg is fried. The albumin protein in the liquid egg white is denatured when placed in a hot pan. Note that not all proteins are denatured at high temperatures; for instance, bacteria that survive in hot springs have proteins that function at temperatures close to boiling. The stomach is also very acidic, has a low pH, and denatures proteins as part of the digestion process; however, the digestive enzymes of the stomach retain their activity under these conditions.
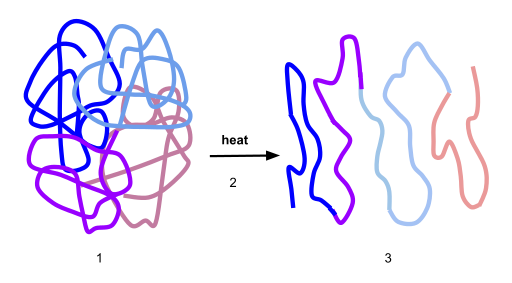
Figure 6.33 Protein Denaturation. Figure (1) depicts the correctly folded intact protein. Step (2) applies heat to the system that is above the threshold of maintaining the intramolecular protein interactions. Step (3) shows the unfolded or denatured protein. Colored regions in the denatured protein correspond to the colored regions of the natively folded protein shown in (1).
Diagram provided by: Scurran15
(back to the top)
Protein folding is critical to its function. It was originally thought that the proteins themselves were responsible for the folding process. Only recently was it found that often they receive assistance in the folding process from protein helpers known as chaperones (or chaperonins) that associate with the target protein during the folding process. They act by preventing aggregation of polypeptides that make up the complete protein structure, and they disassociate from the protein once the target protein is folded.
Proteins are involved in many cellular functions. Proteins can act as enzymes which enhance the rate of chemical reactions. In fact, 99% of enzymatic reactions within a cell are mediated by proteins. Thus, they are integral in the processes of building up or breaking down of cellular components. Proteins can also act as structural scaffolding within the cell, helping to maintain cellular shape. Proteins can also be involved in cellular signaling and communication, as well as the transport of molecules from one location to another. Under extreme circumstances such as starvation, proteins can also be used as an energy source within the cell.
Review Questions:
1. What type of protein facilitates or accelerates chemical reactions?
- an enzyme
- a hormone
- a membrane transport protein
- a tRNA molecule
2. What are the monomers that make up proteins called?
- amino acids
- chaperones
- disaccharides
- nucleotides
- between the R group of one amino acid and the R group of the second
- between the carboxyl group of one amino acid and the amino group of the other
- between the 6 carbon of both amino acids
- between the nitrogen atoms of the amino groups in the amino acids
- the primary structure
- the secondary structure
- the tertiary structure
- the quaternary structure
- changes in pH
- high temperatures
- all of the above
- the addition of some chemicals
- Different amino acids produce different proteins based on the bonds formed between them.
- Differences in amino acids lead to the recycling of proteins, which produces other functional proteins.
- Different amino acids cause rearrangements of amino acids to produce a functional protein.
- Differences in the amino acids cause post-translational modification of the protein, which reassembles to produce a functional protein.
- The primary chain forms secondary α-helix and β-pleated sheets which fold onto each other forming the tertiary structure.
- The primary structure undergoes alternative splicing to form secondary structures, which fold on other protein chains to form tertiary structures.
- The primary structure forms secondary α-helix and β-pleated sheets. This further undergoes phosphorylation and acetylation to form the tertiary structure.
- The primary structure undergoes alternative splicing to form a secondary structure, and then disulfide bonds give way to tertiary structures.
(back to the top)
6.6 Nucleic Acids
Nucleic acids are key macromolecules in the continuity of life. They carry the genetic blueprint of a cell and carry instructions for the functioning of the cell. The two main types of nucleic acids are deoxyribonucleic acid (DNA) and ribonucleic acid (RNA). DNA is the genetic material found in all living organisms, ranging from single-celled bacteria to multicellular mammals. The other type of nucleic acid, RNA, is mostly involved in protein synthesis. The DNA molecules never leave the nucleus, but instead use an RNA intermediary to communicate with the rest of the cell. Other types of RNA are also involved in protein synthesis and its regulation. We will be going into more detail about nucleic acids in a later section.
DNA and RNA are made up of monomers known as nucleotides connected together in a chain with covalent bonds. Each nucleotide is made up of three components: a nitrogenous base, five-carbon sugar, and a phosphate group (Figure 6.34). The nitrogenous base in one nucleotide is attached to the sugar molecule, which is attached to the phosphate group.
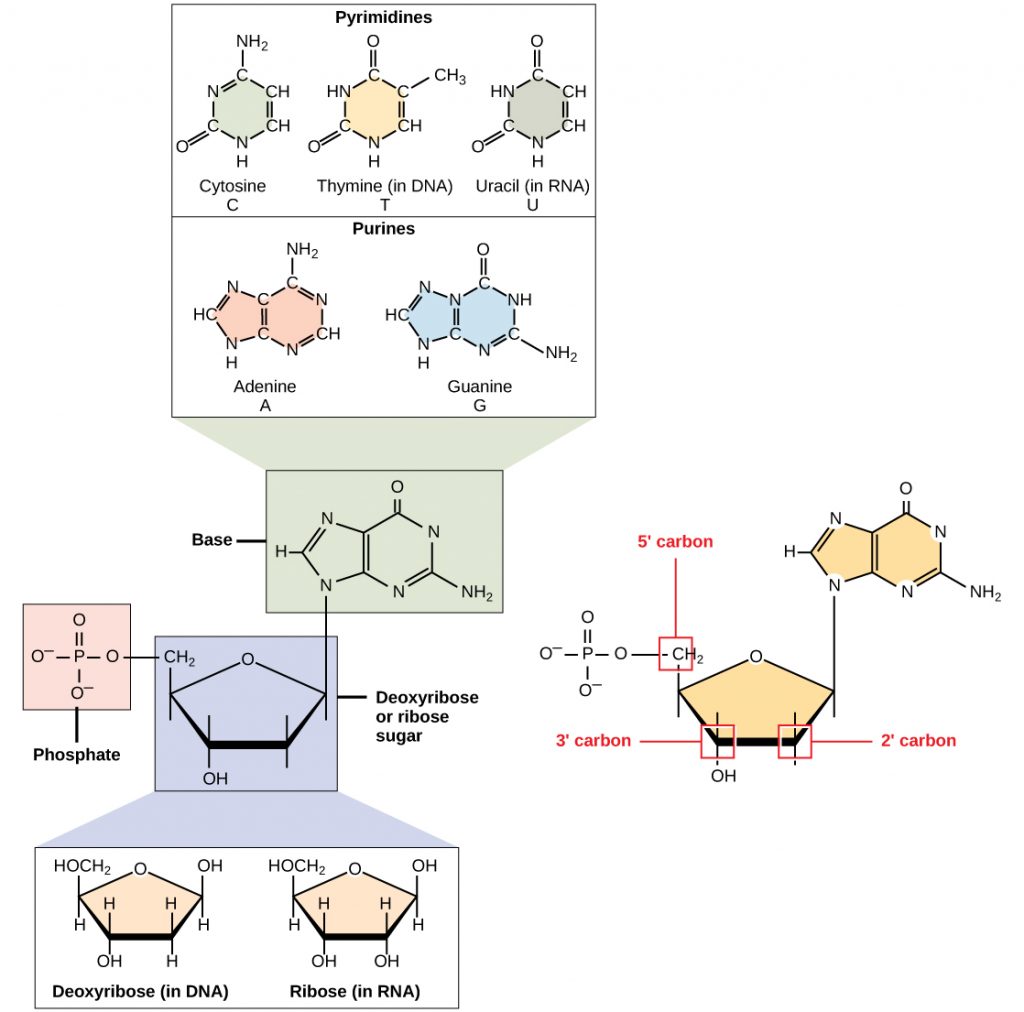
Figure 6.34 The Monomers of DNA. A nucleotide is made up of three components: a nitrogenous base, a pentose sugar, and one or more phosphate groups.
Each nucleotide in DNA contains one of four possible nitrogenous bases: adenine (A), guanine (G) cytosine (C), and thymine (T). RNA contains the base uracil (U) instead of thymine. The order of the bases in a nucleic acid determines the information that the molecule of DNA or RNA carries. This is because the order of the bases in a DNA gene determines the order that amino acids will be assembled together to form a protein.
The pentose sugar in DNA is deoxyribose, and in RNA, the sugar is ribose (Figure 6.34). The difference between the sugars is the presence of the hydroxyl group on the second carbon of the ribose and hydrogen on the second carbon of the deoxyribose. The carbon atoms of the sugar molecule are numbered as 1′, 2′, 3′, 4′, and 5′ (1′ is read as “one prime”). The phosphate residue is attached to the hydroxyl group of the 5′ carbon of one sugar and the hydroxyl group of the 3′ carbon of the sugar of the next nucleotide, which forms a 5′–3′ phosphodiester linkage (a specific type of covalent bond). A polynucleotide may have thousands of such phosphodiester linkages.
DNA Double-Helical Structure
DNA has a double-helical structure (Figure 6.35). It is composed of two strands, or chains, of nucleotides. The double helix of DNA is often compared to a twisted ladder. The strands (the outside parts of the ladder) are formed by linking the phosphates and sugars of adjacent nucleotides with strong covalent bonds. The rungs of the twisted ladder are made up of the two bases attached together with a weaker intermolecular hydrogen bonds. Two bases hydrogen bonded together is called a base pair. The ladder twists along its length, hence the “double helix” description, which means a double spiral.
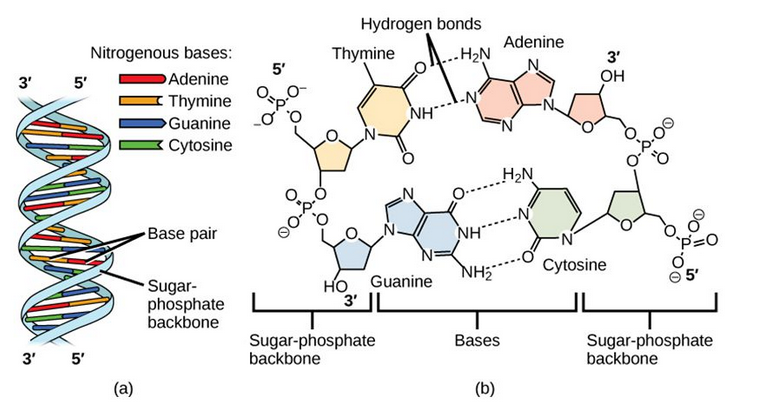
Figure 6.35 The Helical Structure of DNA. (a) DNA forms a double-stranded helix, and (b) adenine pairs with thymine forming two hydrogen bonds and cytosine pairs with guanine forming three hydrogen bonds. This figure is modified from work by Jerome Walker and Dennis Myts.
The alternating sugar and phosphate groups lie on the outside of each strand, forming the backbone of the DNA. The nitrogenous bases are stacked in the interior, like the steps of a staircase, and these basespair; the pairs are bound to each other by hydrogen bonds. The bases pair in such a way that the distance between the backbones of the two strands is the same all along the molecule.
The major function of both DNA and RNA is to store and carry genetic information. The specific order of nucleotides in the molecule of DNA or RNA is what determines the genetic information it carries. You can think of it like letters in a book – if the order of the letters were changed, the book would no longer contain the same (or correct) information.
(back to the top)
6.7 Secondary metabolites
Secondary metabolites, in contrast to primary metabolites are dispensable and not absolutely required for survival. Furthermore, secondary metabolites typically have a narrow species distribution. For example, the deadly nightshade, Atropa belladonna, produces toxic hallucinogenic compounds, like scopolamine, but other plant species do not have this capacity. To date hundreds of thousands of secondary metabolites have been discovered!
Secondary metabolites have a broad range of functions. These include pheromones that act as social signaling molecules with other individuals of the same species, other communication molecules that attract and activate symbiotic organisms, agents that solubilize and transport nutrients, known as siderophores, and competitive weapons (repellants, venoms, toxins etc.) that are used against competitors, prey, and predators. The function of many other secondary metabolites is unknown. One hypothesis is that they confer a competitive advantage to the organism that produces them. An alternative view is that, in analogy to the immune system, these secondary metabolites have no specific function, but having the machinery in place to produce these diverse chemical structures is important. A few secondary metabolites are, therefore, produced and selected for depending on what the organism is exposed to during its lifetime.
Secondary metabolites have a diversity of structures and include examples such as alkaloids, phenylpropanoids, polyketides and terpenoids, as shown in Figure 6.36. Alkaloids are secondary metabolites that contain nitrogen as a component of their organic structure and can be divided into many subclasses of compounds. Nicotine, the addictive substance in tobacco is provided as an example alkaloid (Fig 6.36). The Phenylpropanoids are a diverse family of organic compounds that are synthesized from the amino acids phenylalanine and tyrosine (phenylalanine is shown in Figure 6.36). Cinnamic acid one of the volatile flavor molecules found in cinnamon is a phenylpropanoid. Polyketides are assembled from the building blocks of acetate and malonate to form large, complex structures. Alflatoxin B1, shown below, is a polyketide structure produced by fungi from the Aspergillus genus. These types of molds commonly grow of stored food crops, such as corn and peanuts and contaminate them with aflatoxins. Aflatoxins damage DNA molecules and act as a carcinogen, or cancer causing agent. Food crops contaminated with aflatoxins have been linked with cases of liver cancer. Terpenoids are another large class of natural products that are constructed from 5-carbon monomer units called isoprene (Fig 6.36). Natural rubber is a good example of a terpenoid-based structure. It is assembled from multiple reapeating isoprene units (Fig 6.36). As we explore organic structures in more detail in the next few chapters we will continue to evaluate examples from these diverse classes of metabolites and how they impact our lives.
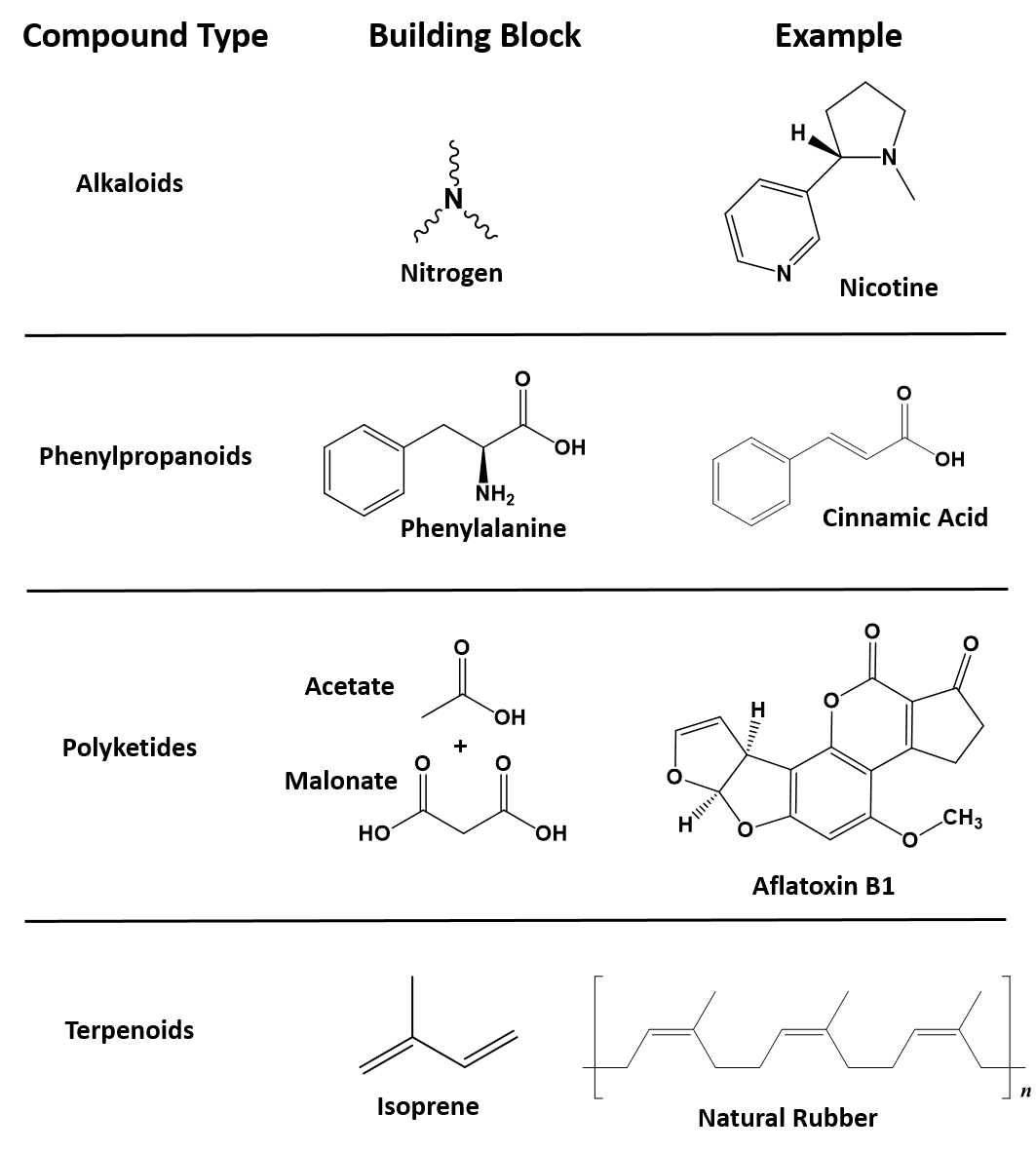
6.36. Representative examples of each of the major classes of secondary metabolites
(back to the top)
6.8 Where Do We Find Secondary Natural Products?
Natural products may be extracted from the cells, tissues, and secretions of microorganisms, plants and animals. A crude (unfractionated) extract from any one of these sources will contain a range of structurally diverse and often novel chemical compounds. Chemical diversity in nature is based on biological diversity, so researchers travel around the world obtaining samples to analyze and evaluate in drug discovery screens or bioassays. This effort to search for natural products is known as bioprospecting.
The discipline of pharmacognosy, which is the study of natural products with biological activity, provides the tools to identify, select and process natural products destined for medicinal use. Usually, a natural extract has some form of biological activity that can be detected and attributed to a single compound or a set of related compounds produced by the organism. These active compounds can be used in drug discovery and development directly as they are, or they may be synthetically modified to enhance biological properties or reduce side effects. Examples of biological sources used to find new natural products are described below.
Prokaryotic Organisms
A prokaryote is a unicellular organism that lacks a membrane-bound nucleus(karyon), mitochondria, or any other membrane-bound organelle. The word prokaryote comes from the Greek πρό (pro) “before” and καρυόν (karyon) “nut” or “kernel”. Prokaryotes can be divided into two domains, Archaea and Bacteria. In contrast, species with nuclei and organelles (Animals, Plants, Fungi and Protists) are placed in the domain Eukaryota.
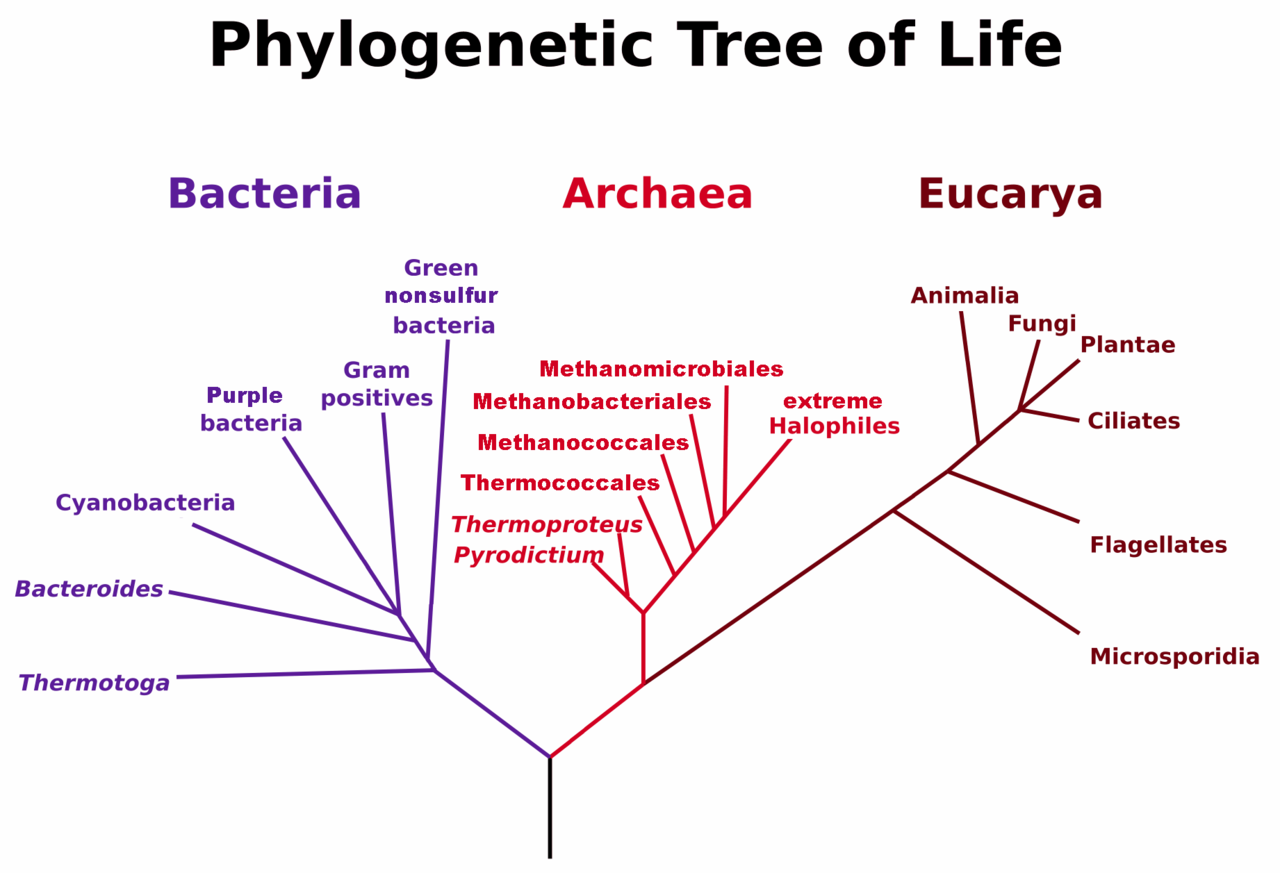
Figure 6.37. Phylogenetic Tree of Life Based on Genetic Sequencing of Ribosomal RNA. Developed by: Maulucioni.
In the prokaryotes, all the intracellular water-soluble components (proteins, DNA and metabolites) are located together in the cytoplasm enclosed by the cell membrane, rather than in separate cellular compartments. Prokaryotes are also much smaller than eukaryotic cells.
Bacteria
Typically a few micrometres in length, bacteria have a number of shapes, ranging from spheres to rods and spirals. Bacteria were among the first life forms to appear on Earth, and are present in most of its habitats. Bacteria inhabit soil, water, acidic hot springs, radioactive waste, and the deep portions of Earth’s crust. Bacteria also live in symbiotic and parasitic relationships with plants and animals. Most bacteria have not been characterised, and only about half of the bacterial phyla have species that can be grown in the laboratory. The study of bacteria is known as bacteriology, a branch of microbiology. There are typically 40 million bacterial cells in a gram of soil and a million bacterial cells in a millilitre of fresh water. Bacteria are a prominent source of natural products. Figure 6.38 shows a few examples of bacterial natural products that have had an impact on our society, including several antibiotics.
The serendipitous discovery and subsequent clinical success of penicillin prompted a large-scale search for other environmental microorganisms that might produce anti-infective natural products. Soil and water samples were collected from all over the world, leading to the discovery of streptomycin (derived from the bacterium, Streptomyces griseus), and the realization that bacteria, not just fungi, represent an important source of antibacterial natural products. This, in turn, led to the development of an impressive arsenal of antibacterial and antifungal agents including amphotericin B, chloramphenicol, erythromycin, neomycin B, daptomycin and tetracycline (all from Streptomyces spp.), the polymyxins (from Paenibacillus polymyxa), and the rifamycins (from Amycolatopsis rifamycinica).

Figure 6.38. Bacteria isolated from soil are prolific producers of antibacterial compounds.
Soil photo by: Pam Dumas. Available at: Flicker
Soil bacteria photo by: Alexander Raths. Available at: Shutterstock
Although most of the drugs derived from bacteria are employed as anti-infectives, some have found use in other fields of medicine. Botulinum toxin (from Clostridium botulinum) and bleomycin (from Streptomyces verticillus) are two examples. Botulinum toxin is the neurotoxin responsible for botulism food poisoning (Fig. 6.39). It is caused by the bacterium, Clostridium botulinum, which can grow in improperly sterilized canned meats and other preserved foods. The poisoning can be fatal depending on how much of the toxin is ingested. It causes muscle weakness and paralysis. This toxin is now used cosmetically to help reduce facial wrinkles. It is injected in small doses into areas such as the forehead to cause paralysis to the muscles that create wrinkles. Also, the glycopeptide bleomycin is used for the treatment of several cancers including Hodgkin’s lymphoma, head and neck cancer, and testicular cancer. Newer trends in the field include the metabolic profiling and isolation of natural products from novel bacterial species present in underexplored environments. Examples include secondary metabolite discovery from symbionts or endophytes. Symbionts are organisms that live in close association with another, often larger, organism known as a host. Endophytes are non-harmful symbionts that are associated with plants for at least part of their life cycle. In addition, discovery of organisms from tropical environments, subterranean bacteria found deep underground via mining/drilling, and marine bacteria continue to add to the complexity of secondary metabolites discovered.
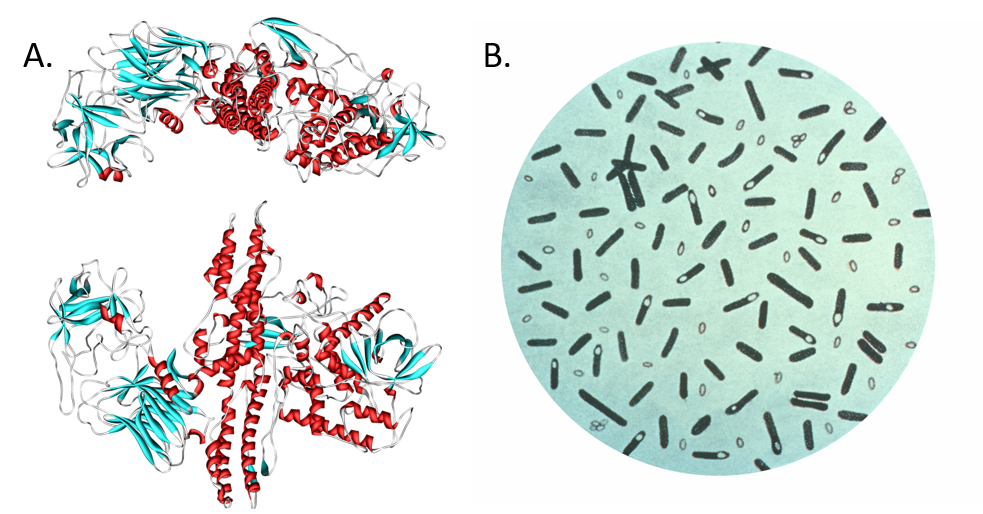
Figure 6.39. Botulinum toxin. (A) Diagram of botulinum toxin A. Consuming food products tainted with the neurotoxin produced by (B) the bacterium Clostridium botulinum, can cause paralysis and death. Interestingly, the neurotoxin (marketed as Botox, Dysport, Xeomin, and MyoBloc) has been adapted for medicinal use to reduce epileptic seizures and for cosmetic use to reduce wrinkles and frown lines by paralyzing muscle tissue in the forehead. Diagram (A) provided at Wikipedia. Diagram (B) provided by the CDC Prevention’s Public Health Image Library
(back to the top)
Archaea
The discovery of organisms now classified as Archaea is fairly recent in our history, dating back to 1977 by the researchers, Carl Woese and George E. Fox. Genetic sequencing was used to show that a separate branch of ancient prokaryotic organisms diverged at an early stage in the history of life on Earth (Fig. 6.40). Thus, Woese suggested dividing the prokaryotic organisms into two major categories, Bacteria and Archaea, based on these genetic differences. It is noteworthy that many Archaea have adapted to life in extreme environments such as the polar regions, hot springs, acidic springs, alkaline springs, salt lakes, and the high pressure of deep ocean water. These Archaea species are known as extremophiles.
Before the discovery by Woese and Fox, scientists thought that prokaryotic extremophiles were bacteria evolved from common bacterial species that are more familiar to us. Now, evidence suggests that they are actually very ancient lifeforms, and may have robust evolutionary connections to early life forms on Earth. Woese’s work on Archaea is significant in its implications for the search for life on other planets, as extremophiles may be hearty enough to exist in the extreme environments located on distant worlds. Because many Archaea have adapted to life in extreme environments they also possess enzymes that are functional under quite unusual conditions. These enzymes are of potential use in the food, chemical, and pharmaceutical industries, where biotechnological processes frequently involve high temperatures, extremes of pH, high salt concentrations, and / or high pressure.
For example, Pyrococcus furiosus is an extremophilic species of Archaea (Fig. 6.40). It can be classified as a hyperthermophile because it thrives best under extremely high temperatures—higher than those preferred of a thermophile. It is notable for having an optimum growth temperature of boiling water – 100°C (a temperature that would destroy most living organisms). Recently, Dr. Tang’s research group isolated a thermostable enzyme from this species that can breakdown lactose, a disaccharide sugar found in milk (Fig. 6.40). Lactose intolerance is a common health concern causing gastrointestinal symptoms and avoidance of dairy products by afflicted individuals. Since milk is a primary source of calcium and vitamin D, lactose intolerant individuals often obtain insufficient amounts of these nutrients which may lead to adverse health outcomes. Production of lactose-free milk can provide a solution to this problem, although it requires use of lactase from microbial sources and increases potential for contamination. Use of thermostable lactase enzymes can overcome this issue by functioning under pasteurization conditions. Early explorations of this enzyme show that it has optimal activity at 100oC and that it is thermostable even at 110oC (Fig. 6.40).
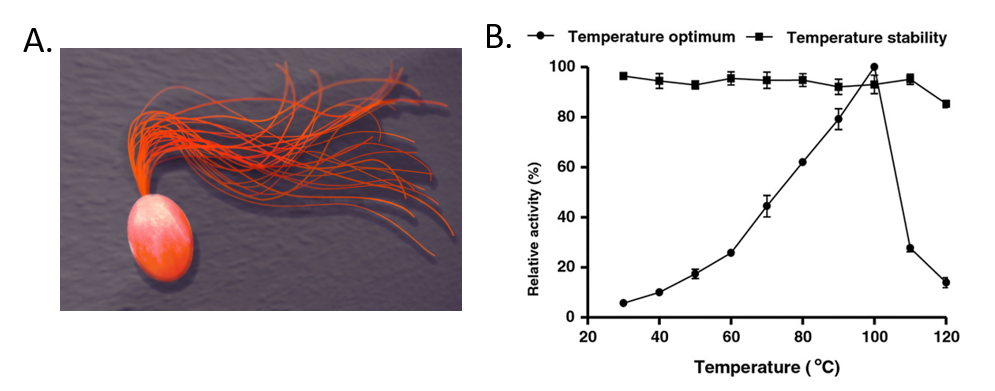
Figure 6.40 The Extremophile Pyrococcus furiosus. (A) Shows a computer recreation of P. furiosus. (B) Shows the effects of temperature on the stability of the lactase enzyme, β-glucosidase.
(A) Recreation of P. furiosus by: Fulvio314 (B) Effects of temperature figure on P. furiousus lactase activity and text adapted from: Li, et al. (2013) BMC Biotechnol. 13:73
(back to the top)
Eukaryotic Organisms
Eukaryotic organisms include four major kingdoms: Protista, Fungi, Plantae, and Animalia (Fig 6.41). Fungi are heterotrophic, eukaryotic organisms, either single-celled or multicellular, that are primarily decomposers within the environment. Heterotrophs are organisms that cannot produce their own food. Plants are multicellular eukaryotic organisms that are autotrophic, or capable of producing their own food. Plants are also characterized by having true roots, stems and leaves. Animals are multicellular, eukaryotic organisms that are heterotrophic, and are characterized by being mobile at some point in their lifetime. The term Protista (or sometimes Protoctista) is still often used to describe all other eurkaryotic organisms that do not fit in the Fungi, Plantae, or Animalia kingdoms. However, it is not an ideal grouping, as there are protists that are animal-like, plant-like and fungi-like grouped under one umbrella term. Many scientists prefer to reclassify the protist kingdom into sub-groupings of related organisms based on phylogenetic data, rather than use the older protist classification. In fact, the phylogenetic classification proposed by Carl Woese breaks Kingdom Protista into three major groups; the ciliates, the flagellates, and the microsporidia (Fig 6.37). In the following section, we will focus on natural product examples from the Fungi, Plant, and Animal kingdoms. However, keep in mind that many protists are also producers of interesting natural products.
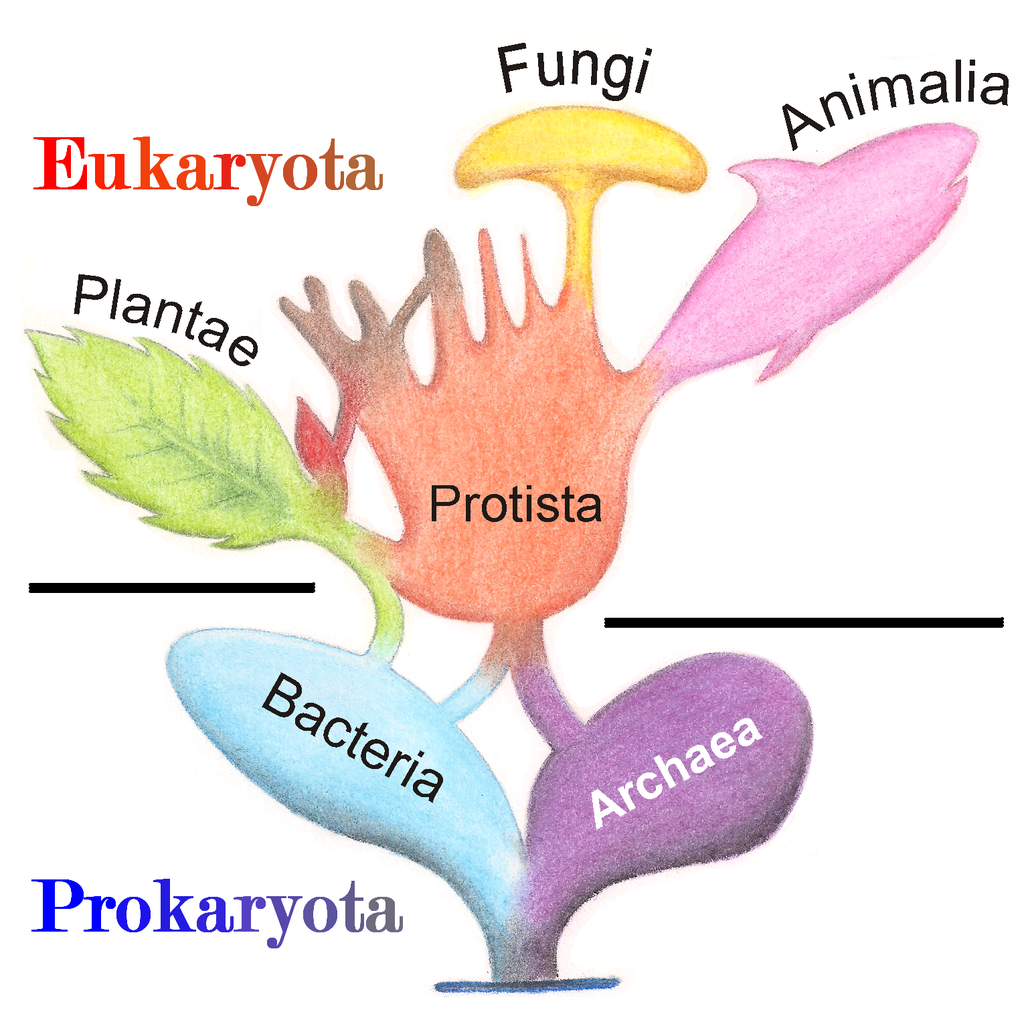
Figure 6.41 The Major Domains and Kingdoms of Life. By: Maulucioni y Doridí
(back to the top)
Fungi
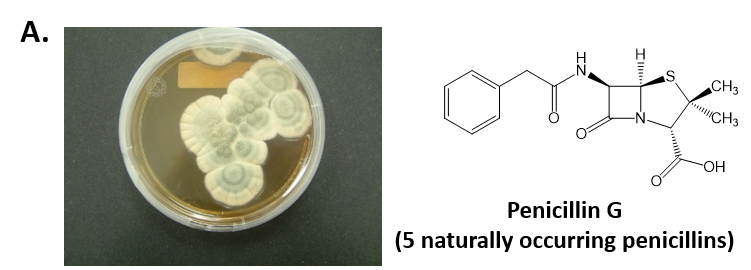
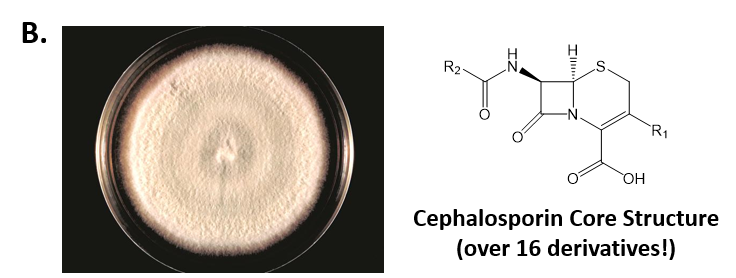
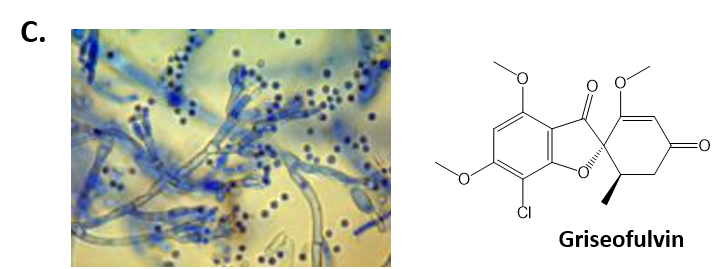
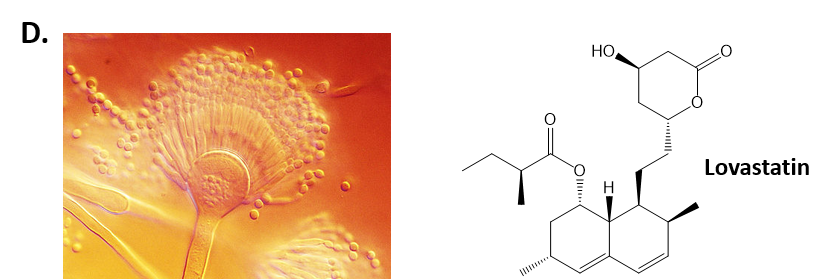
As mentioned above, Fungi are heterotrophic, eukaryotic organisms that are primarily decomposers within the environment. They include single-celled organisms such as yeast and molds, and multicellular organisms that have fruiting bodies, such as mushrooms. Fungi produce a myriad of secondary natural products. Some are very toxic and have spurred common names such as death cap, destroying angel, and fool’s mushroom. Others have found great utility in medicine. For example, several anti-infective medications have been derived from fungi including the penicillins and the cephalosporins (antibacterial drugs from Penicillium chrysogenum and Cephalosporium acremonium, respectively), and griseofulvin (an antifungal drug from Penicillium griseofulvum) (Fig 6.42, parts A-C). Another medicinally useful fungal metabolite is lovastatin (from Aspergillus terreus), which became a lead for the statins, a series of drugs commonly used to lower cholesterol levels (Fig 6.42, part D).

Ergometrine (from Claviceps spp.) acts as a vasoconstrictor, and is used to prevent bleeding after childbirth (Fig 6.42, part E). You will notice in the photograph of Claviceps spp. that this genus of fungi commonly grows on grain crops such as wheat and barley. Contamination of grain crops with this fungi can lead to human poisoning if high quantities of the fungi are consumed. This type of poisoning is known as ergotism and can cause convulsions. The vasoconstrictive properties of ergometrine can also cause gangrenous side effects when ingested in toxic doses. Distal structures that are more poorly vascularized like the fingers and the toes are affected first. This can cause loss of peripheral sensation, edema, and ultimately the death and loss of affected tissues.
Cyclosporin is another amazing example of a fungal metabolite with important medical implications. Cyclosporin is an alkaloid structure that is assembled from amino acid building blocks that forms a cyclic peptide structure (Fig 6.43). Its major biological activity is to suppress the immune response. Thus, it is widely prescribed to patients following an organ transplant, to help reduce the chance of organ rejection. Cyclosporin was isolated in 1971 from the fungus Tolypocladium inflatum (Fig 6.43). After 12 years of laboratory investigations and clinical testing, it was approved by the FDA for use in 1983. It is on the World Health Organization’s List of Essential Medicines, as one of the most effective and safe medicines needed in a health system. Of note, T. inflatum is the asexual, single-celled form of a fungus that can also take on a sexually-reproducing multicellular life-stage, where it is known as the fungi, Cordyceps subsessilis (Fig 6.43). Cyclosporin is only produced during the asexual life-stage of the organism, demonstrating that gene expression can vary dramatically within an organism due to life-stage or other factors present within the environment of the organism.

Photos By: Kathie Hodge
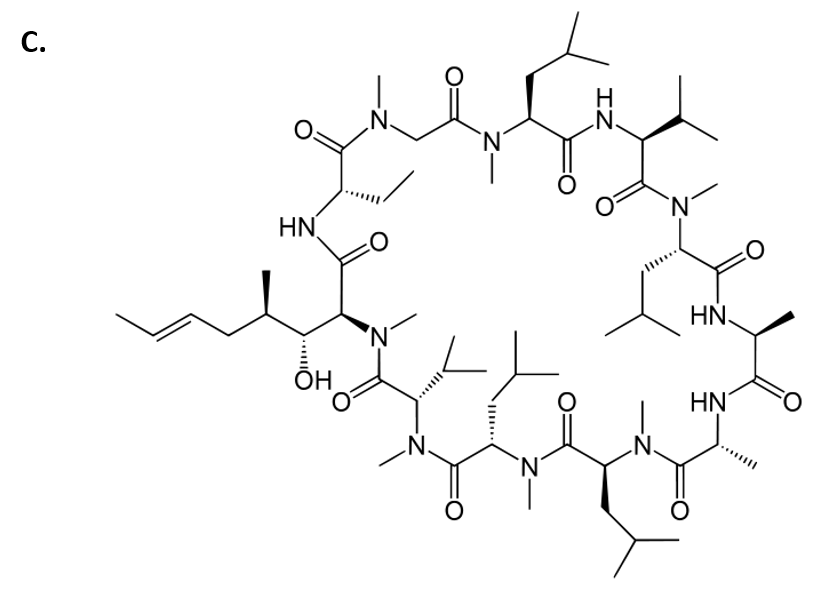
Cyclosporin Structure from Yikrazuul
Figure 6.43 Fungal Production of Cyclosporin. (A) Multicellular life-stage of the fungus, known as Cordyceps subsessilis, (B) unicellular life-stage of the fungus, known as Tolypocladium inflatum. (C) Structure of cyclosporine.
(back to the top)
Plants
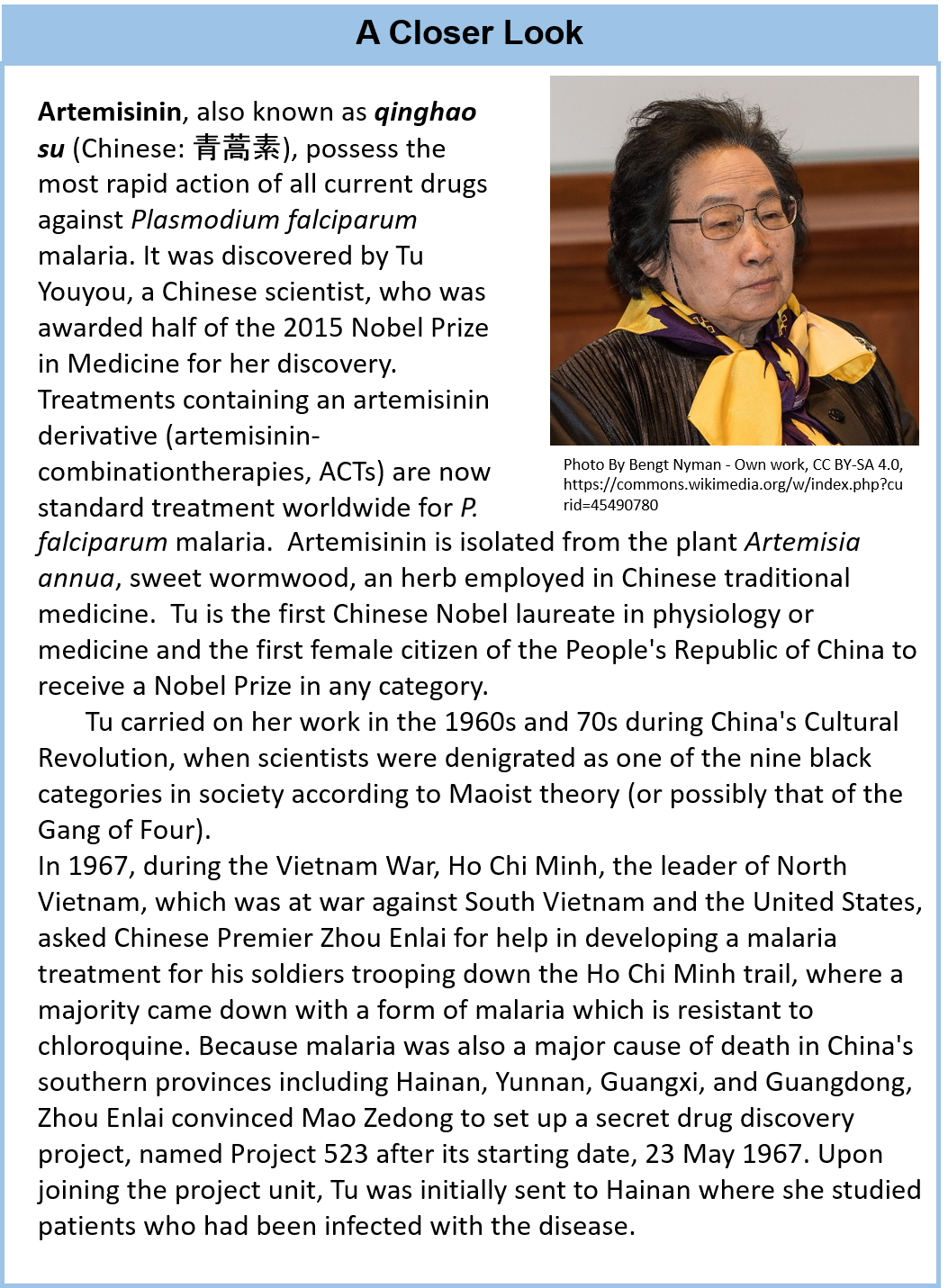
Life forms that are classified in the Plant Kingdom are multicellular eukaryotic organisms that are autotrophic, or capable of producing their own food. They produce their own food through the process of photosynthesis, where they utilize light energy from the sun to convert carbon dioxide and water into simple sugars. Oxygen is a by-product of this reaction. Thus, plants are a major source of oxygen on the planet. It is estimated that there are approximately 250,000 to 300,000 different species of plants on the planet. In addition to producing oxygen and being utilized as a food source, plants are also a major source of complex and highly structurally diverse secondary metabolites. This structural diversity is attributed in part to the natural selection of organisms producing potent compounds to deter herbivory (feeding deterrents). Though the number of plants that have been extensively studied is relatively small, many pharmacologically active natural products have been identified and are currently used as medical treatments. Clinically useful examples include the anticancer agents paclitaxel and vinblastine (from Taxus brevifolia and Catharanthus roseus, respectively), the antimalarial agent artemisinin (from Artemisia annua),the opioid analgesic drug morphine (from Papaver somniferum), and galantamine (from Galanthus spp.), used to treat Alzheimer’s disease (Fig 6.44).

(Photo by:Jason Hollinger)

(Photo by:Joydeep)

(Photo by:Kristian Peters)

(Photo by:Dinkum)

(Photo by:Meneerke Bloem and Peter Coxhead)
Figure 6.44. Examples of biologically active metabolites from plants.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
#/media/File:Process_of_Denaturation.svg){kind=link}
Animals
Animals are multicellular, eukaryotic organisms of the kingdom Animalia. As described earlier, animals are heterotrophic organisms and are characterized by being mobile at some point in their lifetime. Animals can be divided broadly into vertebrates and invertebrates. Vertebrates have a backbone or spine (vertebral column), and amount to less than five percent of all described animal species. They include fish, amphibians, reptiles, birds and mammals. The remaining animals are the invertebrates, which lack a backbone. These include molluscs (clams, oysters, octopuses, squid, snails); arthropods (millipedes, centipedes, insects, spiders, scorpions, crabs, lobsters, shrimp); annelids (earthworms, leeches), nematodes (filarial worms, hookworms), flatworms (tapeworms, liver flukes), cnidarians (jellyfish, sea anemones, corals), ctenophores (comb jellies), and sponges. The study of animals is called zoology.
Animals also represent a source of bioactive natural products. In particular, venomous animals such as snakes, spiders, scorpions, caterpillars, bees, wasps, centipedes, ants, toads, and frogs have attracted much attention. This is because venom constituents (peptides, enzymes, nucleotides, lipids, biogenic amines etc.) often have very specific interactions with a macromolecular target in the body. As with plant feeding deterrents, this biological activity is attributed to natural selection, organisms capable of killing or paralyzing their prey and/or defending themselves against predators being more likely to survive and reproduce.
For example, Chlorotoxin is a 36-amino acid peptide found in the venom of the deathstalker scorpion (Leiurus quinquestriatus) which blocks small-conductance chloride channels (Fig. 6.45). It uses this toxin to immobilize it’s prey.

Figure 6.45 Chlorotoxin from the deathstalker scorpion (Leiurus quinquestriatus). A ribbon diagram of the chlorotoxin protein is shown on the right. Photo of the deathstalker scorpion by: Ester Inbar and Ribbon diagram of chlorotoxin by: Lijealso.
Remarkably, in humans chlorotoxin binds preferentially to glioma brain cancer cells. A glioma is a type of tumor that forms in the brain or spinal chord. It can often become malignant, which is a term used to describe cancer that has poor prognosis and is prone to spreading to different areas of the body. Remarkably, chlorotoxin only binds with the tumor cells and not with normal brain tissue. This feature has allowed the development of new methods to treat, diagnosis, and remove several different types of cancer. For example, TM-601 which is the synthetic version of chlorotoxin is currently under phase II clinical trial. Radioactive Iodine-131 can be attached to TM-601 and used to treat malignant glioma. TM-601 crosses blood-brain and tissue barriers and binds to the malignant brain tumor cells without affecting healthy tissue. When TM-601 is attached to the radioactive Iodine-131 the iodine will also be recruited specifically to the tumor where it can preferentially kill the tumor cells.
In addition, researchers at Fred Hutchinson Cancer Research Center have also created a chlorotoxin derivative called BLZ-100 that is attached to a fluorescent dye. This provides a long lasting signal that makes the tumor glow, almost as if all the parts of the tumor have been painted. It can be used in real time to help a surgeon determine where the edges of the tumor are or where the tumor has spread, so that in can be removed completely. Animal trials with this ‘tumor paint’ have shown positive results with many types of cancer. Figure 6.46 shows a tumor that has been removed from a dog that has breast cancer — it’s called mammary carcinoma in a dog — and the surgeons knew about that big spot down in the bottom right, that was cancer, but really that’s all they were able to tell from the clinical exam and the scans that were done in advance. This dog received a dose of tumor paint the day before surgery, and in the right panel of Figure 6.46 is what the surgeons were able to see. Not only could they see the main tumor, but they could see additional areas of cancer that were not visible to the naked eye.
Figure 6.46 Making Cancer Visible. On the left is a photo of a mammary tumor that has been removed from dog. On the right, is the same mammary tumor exposed to BLZ-100. The fluorescent areas are where the cancer tissue is present. Photo by Todd Bishop at Geekwire.
All across America everyday, women who have had breast cancer surgery are told, “you have clean margins, everything looks good, we’ll follow it with some scans”, and then six to nine months later they start to get some bad news. Unfortunately, the surgeons can’t always see exactly where the cancer is, and sometimes cancer isn’t contiguous. It jumps around into some spots a little ways away from the primary, and tumor paint is helping making cancer much more visible. To hear more about this and other related drug developments, listen to Jim Olson’s Geekwire Talk posted below.
Other novel drugs that have arisen from animal venoms include, teprotide, a peptide isolated from the venom of the Brazilian pit viper Bothrops jararaca (Fig 6.47). Teprotide was found to have activity as an antihypertensive agent and provided an initial lead compound for the development of blood pressure lowering medications. It was not a good drug candidate on its own, due to the expense in isolating it and the lack of oral availability. However the structure was used as a lead compound and many derivative structures were made to try and find smaller, more soluble, orally active compounds that had the same biological activity. This has resulted in the development of the currently presecribed antihypertensive agents, cilazapril and captopril (Fig 6.47).

6.47 Teprotide and Its Synthetic Derivatives Cilazapril and Captoprial. Teprotide (B) is a toxin produced by the pit viper, Bothrops jararaca (A). Due to poor oral availability and expense teprotide was not a good drug compound, however, its biological activity lead to the development of the synthetic antihypertensive drugs, Cilazapril (C) and Captopril (D).
Photo of Bothrops jararaca by: Felipe Süssekind , Structure of Teprotide by: Yikrazuul, Structure of Cilazapril by: Vaccinationist, and Structure of Captorpril by: Vaccinationist.
In addition to the terrestrial animals described above, many marine animals have been examined for pharmacologically active natural products, with corals, sponges, tunicates, sea snails, and bryozoans yielding chemicals with interesting analgesic, antiviral, and anticancer activities. Two examples developed for clinical use include ω-conotoxin (from the marine snail Conus magus) and ecteinascidin 743 (from the tunicate Ecteinascidia turbinata) (Figure 6.48). The former, ω-conotoxin, is used to relieve severe and chronic pain, while the latter, ecteinascidin 743 is used to treat cancer.

6.48 Medicines from the Sea. In the upper panel the marine snail, Conus magnus and it’s active metabolite, ω-conotoxin, are shown. Note that ω-conotoxin is a protein. Thus, it’s structure is much to large to show all the organic bonds. Proteins are often depicted in ribbon diagrams to give you a sense of the 3-dimensional folding patterns. In the lower panel the tunicate Ecteinascidia turbinate and its metabolite, ecteinascidin 743 (ET-743) are shown. Photo of Conus magnus provided by: Richard Parker. Ribbon diagram of ω-conotoxin provided by: Fvasconcellos. Photo of the tunicate, Ecteinascidia turbinate provided by: Sean Nash.
(back to the top)
6.9 Chapter Summary
Interest in the biological activities of natural products from different organisms, especially for the discovery of useful medicines, has been a major driving force for the development of organic chemistry concepts and laboratory techniques.
Natural products can be divided into two major classes, primary metabolites, which are required for an organism to survive, and secondary metabolites, which are not required for an organism to survive, but usually lend the organism some form of growth or survival advantage within its environment.
Natural products are often classified based on major structural features. Four of the major classes of natural products are the alkaloids, which are organic molecules that contain nitogen, the phenylpropanoids which are derived from the amino acids phenylalanine or tyrosine, the polyketides derived from acetate and malonate, and the terpenoids, derived from the five-carbon building block, isoprene.
The process of searching for and finding new natural products throughout the world is called bioprospecting and the discipline that elucidates the structure of natural products and studies their biological activity is called pharmacognosy.
Biologically-active natural products can be found in all forms of life on the planet. The natural world is divided up into two major types of organisms: Prokaryotic organisms that are unicellular and lack membrane-bound organelles, and Eukaryotic organisms that can be unicellular or multicellular and have a nucleus and other membrane-bound organelles. Biologists classify Prokaryotic organisms into two major life domains, Bacteria and Archaea. The third domain, Eukaryota, houses all eukaryotic organisms. The domain Eukaryota is sub-divided into four major kingdoms, Animalia, Plantae, Fungi, and Protista. Some scientists breakdown the Kingdom Protista into smaller sub-categories. Natural products discovery from organisms within all of life’s major domains have made lasting contributions to Western Medicine.
Early investigations into organic chemistry and structure elucidation included work by Michel Chevreul on the study of soaps. The process of making soaps from fats and alkalis (basic substances) is called saponification. In the saponification reaction, an alkali base, such as sodium hydroxide, is used to breakdown an ester bond into an alcohol and the salt of a carboxylic acid (in this case, the fatty acid). These early studies, and studies by Wohler and others, paved the way for the field of Synthetic Organic Chemistry, the study of making organic molecules.
(back to the top)
6.10 References:
Chapter 6 materials have been adapted and modified from the following creative commons resources unless otherwise noted:
1. Natural product. (2016, December 29). In Wikipedia, The Free Encyclopedia. Retrieved 06:30, January 27, 2017, from https://en.wikipedia.org/w/index.php?title=Natural_product&oldid=757173982
2. Ergotism. (2016, December 24). In Wikipedia, The Free Encyclopedia. Retrieved 07:36, February 3, 2017, from https://en.wikipedia.org/w/index.php?title=Ergotism&oldid=756409773
3. Prokaryote. (2016, December 30). In Wikipedia, The Free Encyclopedia. Retrieved 20:33, January 27, 2017, from https://en.wikipedia.org/w/index.php?title=Prokaryote&oldid=757396179
4. Wikibooks. (2015) Organic Chemistry. Available at: https://en.wikibooks.org/wiki/Organic_Chemistry.
5. Clark, J. (2014) How to Draw Organic Molecules. Available at: http://chem.libretexts.org/Core/Organic_Chemistry/Fundamentals/How_to_Draw_Organic_Molecules
6. Soderberg, T. (2016). Organic Chemistry With a Biological Emphasis . Published under Creative Commons by-nc-sa 3.0.
7. Anonymous. (2012) Introduction to Chemistry: General, Organic, and Biological (V1.0). Published under Creative Commons by-nc-sa 3.0. Available at: http://2012books.lardbucket.org/books/introduction-to-chemistry-general-organic-and-biological/index.html
8. Pyrococcus furiousus. Available at: https://en.wikipedia.org/wiki/Pyrococcus_furiosus
9. Li, B., Wang, Z., Li, S., Donelan, W., Wang, X., Cui, T., & Tang, D. (2013). Preparation of lactose-free pasteurized milk with a recombinant thermostable β-glucosidase from Pyrococcus furiosus. BMC Biotechnology, 13, 73. http://doi.org/10.1186/1472-6750-13-73
10. Animal. (2017, February 5). In Wikipedia, The Free Encyclopedia. Retrieved 03:53, February 6, 2017, from https://en.wikipedia.org/w/index.php?title=Animal&oldid=763775373
11. Organic chemistry. (2017, February 8). In Wikipedia, The Free Encyclopedia. Retrieved 06:18, February 9, 2017, from https://en.wikipedia.org/w/index.php?title=Organic_chemistry&oldid=764307722
12. OpenStax, Biology. OpenStax CNX. May 27, 2016 http://cnx.org/contents/s8Hh0oOc@9.10:QhGQhr4x@6/Biological-Molecules
13. Molnar, C. and Gair, J. (2012) 2.3 Biological Molecules Chapter in Concepts in Biology, OpenStax College Textbooks, British Comumbia. Retrieved on Dec 22nd, 2018 from: https://opentextbc.ca/biology/chapter/2-3-biological-molecules/
14. Ophardt, C. (2015) Carbohydrates. In Biological Chemistry. Libretexts. Available at: https://chem.libretexts.org/Core/Biological_Chemistry
15. Gunawardena, G. (2014) Haworth Projections. In Biological Chemistry. Libretexts. Available at: https://chem.libretexts.org/Core/Biological_Chemistry.
16. Snell, Foster D. “Soap and glycerol.” J. Chem. Educ. 1942, 19, 172.
17. OpenStax, Proteins. OpenStax CNX. Sep 30, 2016 http://cnx.org/contents/bf17f4df-605c-4388-88c2-25b0f000b0ed@2.
18. OpenStax, Microbiology. Libretexts. Dec 14, 2015 Available at: https://bio.libretexts.org/TextMaps/Map%3A_Microbiology_(OpenStax)
19. Ed Vitz (Kutztown University), John W. Moore (UW-Madison), Justin Shorb (Hope College), Xavier Prat-Resina (University of Minnesota Rochester), Tim Wendorff, and Adam Hahn. (2016) Exemplars and Case Studies. Libretexts. Available at: https://chem.libretexts.org/Exemplars_and_Case_Studies/Exemplars/Culture/Secondary_Protein_Structure_in_Silk