CH103 – Chapter 8: The Major Macromolecules
11.1 Introduction: The Four Major Macromolecules
Within all lifeforms on Earth, from the tiniest bacterium to the giant sperm whale, there are four major classes of organic macromolecules that are always found and are essential to life. These are the carbohydrates, lipids (or fats), proteins, and nucleic acids. All of the major macromolecule classes are similar, in that, they are large polymers that are assembled from small repeating monomer subunits. In Chapter 6, you were introduced to the polymers of life and their building block structures, as shown below in Figure 11.1. Recall that the monomer units for building the nucleic acids, DNA and RNA, are the nucleotide bases, whereas the monomers for proteins are amino acids, for carbohydrates are sugar residues, and for lipids are fatty acids or acetyl groups.
This chapter will focus on an introduction to the structure and function of these macromolecules. You will find that the major macromolecules are held together by the same chemical linkages that you’ve been exploring in Chapters 9 and 10, and rely heavily on dehydration synthesis for their formation, and hydrolysis for their breakdown.
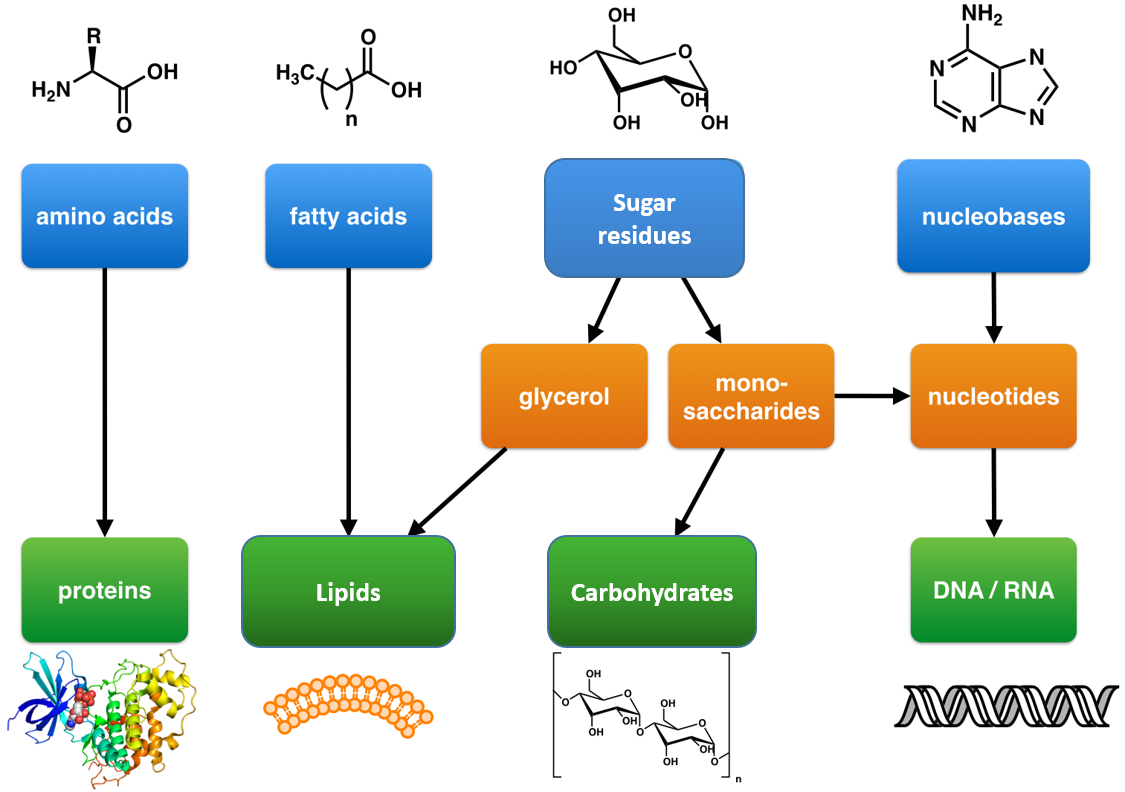
{kind=link}
Figure 11.1: The Molecular building blocks of life are made from organic compounds.
Modified from: Boghog
Fun Video Tutorial Introducing the Major Macromolecules
Biological Molecules – You Are What You Eat: Crash Course Biology #3.
11.2 Protein Structure and Function
Amino Acids and Primary Protein Structure
The major building block of proteins are called alpha amino acids. As their name implies they contain a carboxylic acid functional group and an amine functional group. The alpha designation is used to indicate that these two functional groups are separated from one another by one carbon group. In addition to the amine and the carboxylic acid, the alpha carbon is also attached to a hydrogen and one additional group that can vary in size and length. In the diagram below, this group is designated as an R-group. Within living organisms there are 20 amino acids used as protein building blocks. They differ from one another only at the R-group postion. The basic structure of an amino acid is shown below:
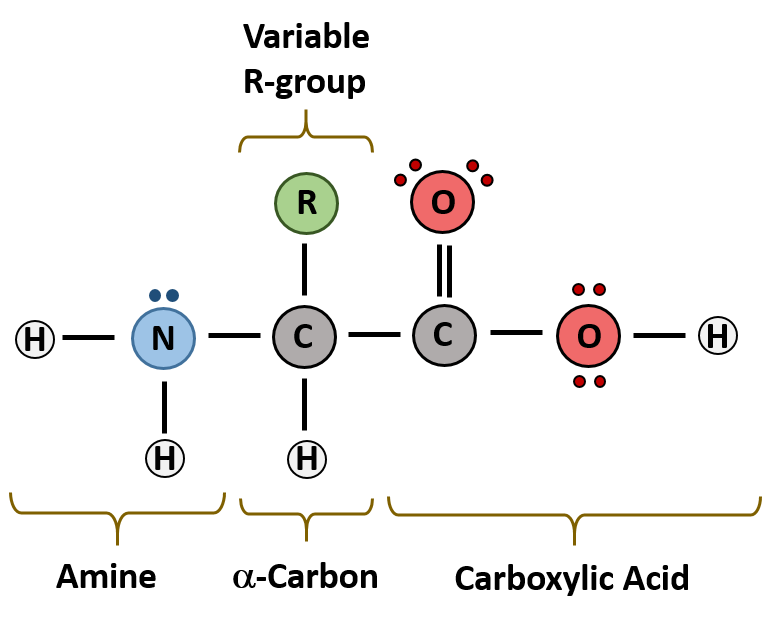
Figure 11.2 General Structure of an Alpha Amino Acid
Within cellular systems, proteins are linked together by a complex system of RNA and proteins called the ribosome. Thus, as the amino acids are linked together to form a specific protein, they are placed within a very specific order that is dictated by the genetic information contained within the RNA. This specific ordering of amino acids is known as the protein’s primary sequence. The primary sequence of a protein is linked together using dehydration synthesis that combine the carboxylic acid of the upstream amino acid with the amine functional group of the downstream amino acid to form an amide linkage. Within protein structures, this amide linkage is known as the peptide bond. Subsequent amino acids will be added onto the carboxylic acid terminal of the growing protein. Thus, proteins are always synthesized in a directional manner starting with the amine and ending with the carboxylic acid tail. New amino acids are always added onto the carboxylic acid tail, never onto the amine of the first amino acid in the chain. In addition, because the R-groups can be quite bulky, they usually alternate on either side of the growing protein chain in the trans conformation. The cis conformation is only preferred with one specific amino acid known as proline.
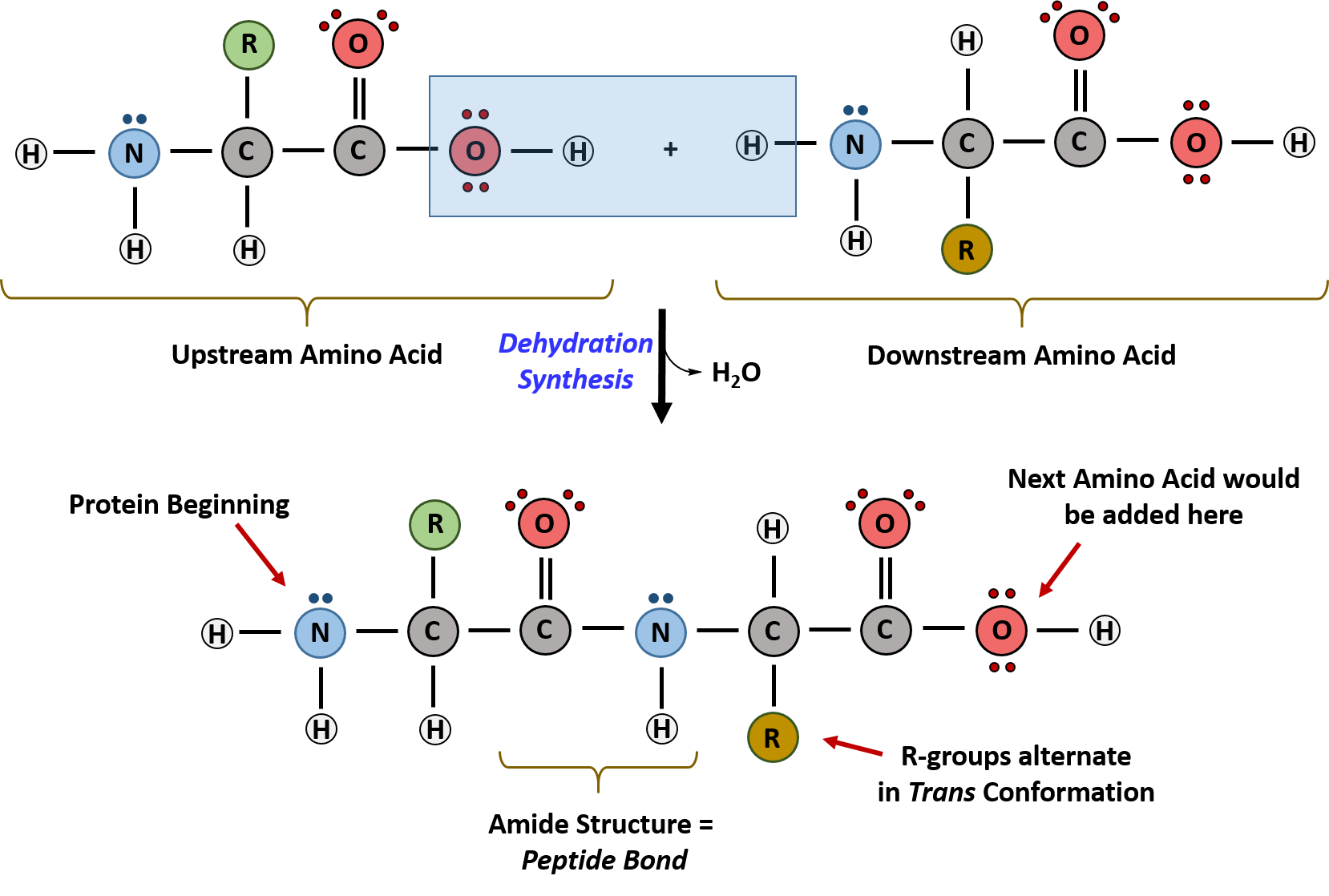
Figure 11.3 Formation of the Peptide Bond. The addition of two amino acids to form a peptide requires dehydration synthesis.
Proteins are very large molecules containing many amino acid residues linked together in very specific order. Proteins range in size from 50 amino acids in length to the largest known protein containing 33,423 amino acids. Macromolecules with fewer than 50 amino acids are known as peptides.

Figure 11.4 Peptides and Proteins are macromolecules built from long chains of amino acids joined together through amide linkages.
The identity and function of a peptide or a protein is determined by the primary sequence of amino acids within its structure. There are a total of 20 alpha amino acids that are commonly incorporated into protein structures (Figure 11.5).
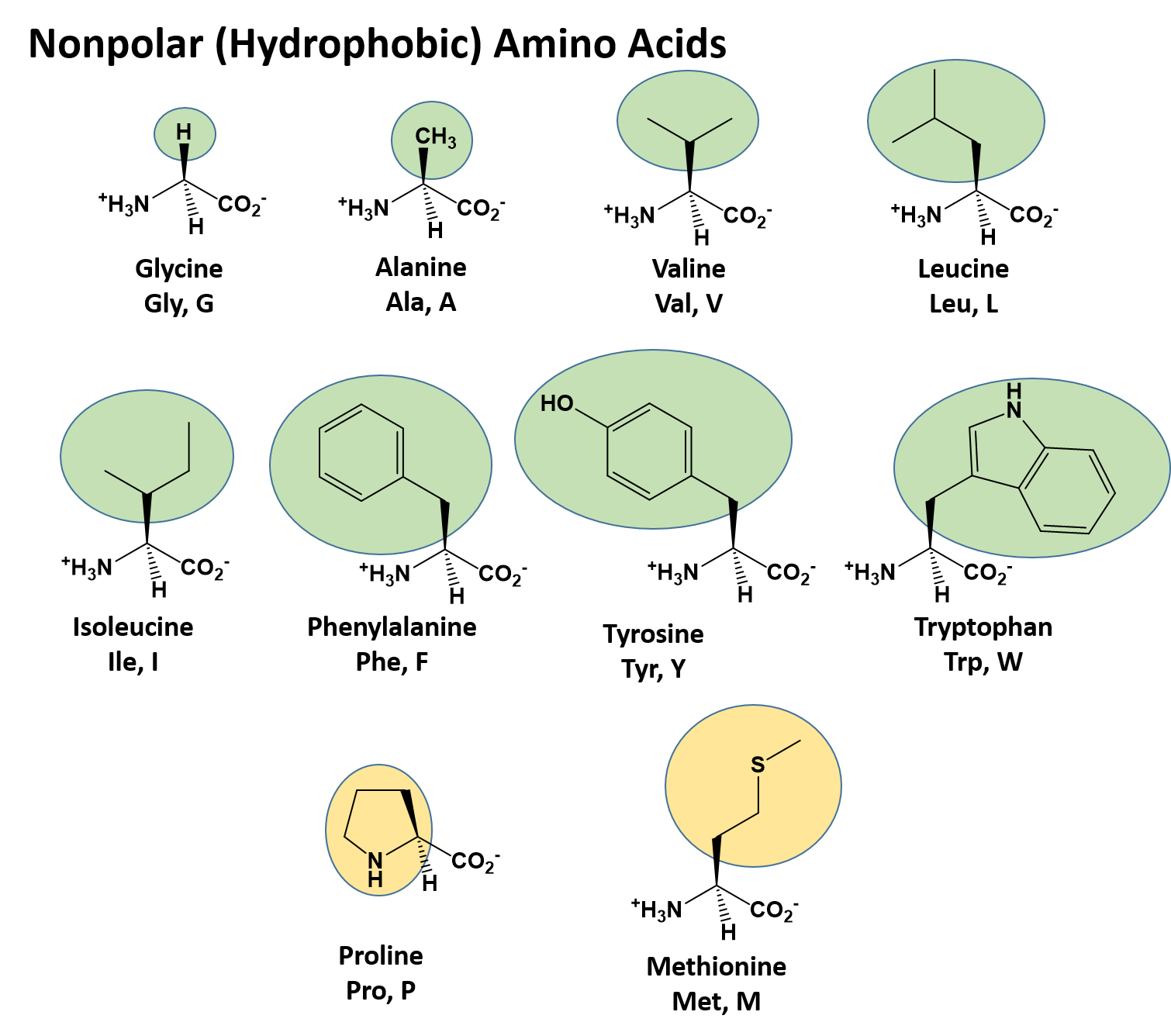
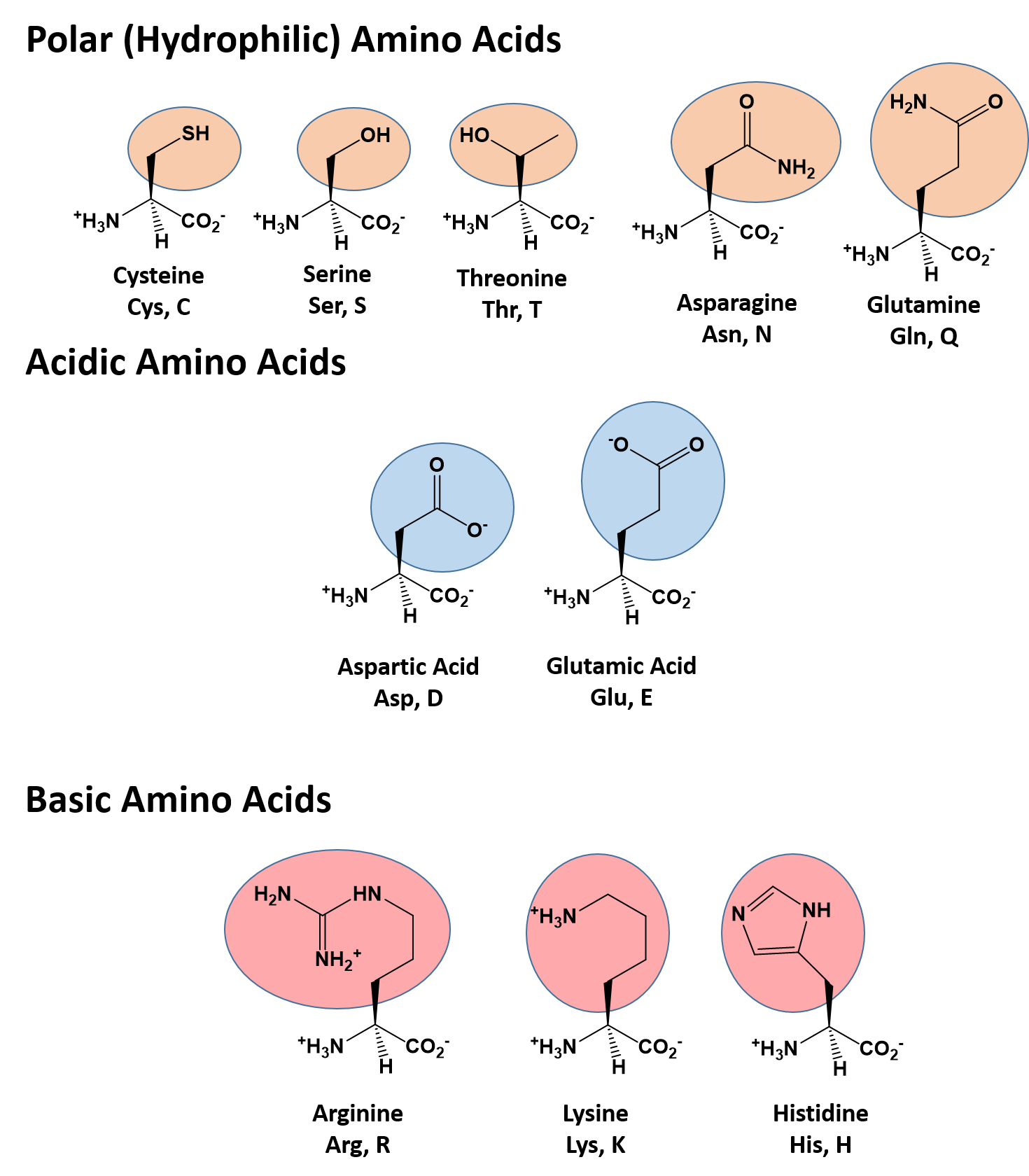
Figure 11.5 Structure of the 20 Alpha Amino Acids used in Protein Synthesis.
Due to the large pool of amino acids that can be incorporated at each position within the protein, there are billions of different possible protein combinations that can be used to create novel protein structures! For example, think about a tripeptide made from this amino acid pool. At each position there are 20 different options that can be incorporated. Thus, the total number of resulting tripeptides possible would be 20 X 20 X 20 or 203, which equals 8,000 different tripeptide options! Now think about how many options there would be for a small peptide containing 40 amino acids. There would be 2040 options, or a mind boggling 1.09 X 1052 potential sequence options! Each of these options would vary in the overall protein shape, as the nature of the amino acid side chains helps to determine the interaction of the protein with the other residues in the protein itself and with its surrounding environment. Thus, it is useful to learn a little bit about the general characteristics of the amino acid side chains.
The different amino acid side chains can be grouped into different classes based on their chemical properties (Figure 11.5). For example, some amino acid side chains only contain carbon and hydrogen and are thus, very nonpolar and hydrophobic. Others contain electronegative functional groups with oxygen or nitrogen and can form hydrogen bonds forming more polar interactions. Still others contain carboxylic acid functional groups and can act as acids or they contain amines and can act as bases, forming fully charged molecules. The character of the amino acids throughout the protein help the protein to fold and form its 3-dimentional structure. It is this 3-D shape that is required for the functional activity of the protein (ie. protein shape = protein function). For proteins found inside the watery environments of the cell, hydrophobic amino acids will often be found on the inside of the protein structure, whereas water-loving hydrophilic amino acids will be on the surface where they can hydrogen bond and interact with the water molecules. Proline is unique because it has the only R-group that forms a cyclic structure with the amine functional group in the main chain. This cyclization is what causes proline to adopt the cis conformation rather than the trans conformation within the backbone. This shift is structure will often mean that prolines are positions where bends or directional changes occur within the protein. Methionine is unique, in that it serves as the starting amino acid for almost all of the many thousands of proteins known in nature. Cysteines contain thiol functional groups and thus, can be oxidized with other cysteine residues to form disulfide bonds within the protein structure (Figure 11.6). Disulfide bridges add additional stability to the 3-D structure and are often required for correct protein folding and function (Figure 11.6).
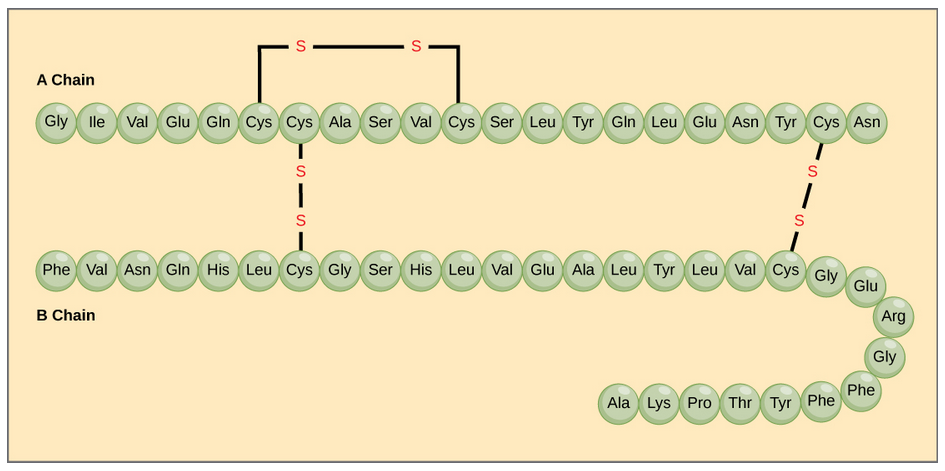
Figure 11.6 Disulfide Bonds. Disulfide bonds are formed between two cysteine residues within a peptide or protein sequence or between different peptide or protein chains. In the example above the two peptide chains that form the hormone insulin are depicted. Disulfide bridges between the two chains are required for the proper function of this hormone to regulate blood glucose levels.
Protein Shape and Function
The primary structure of each protein leads to the unique folding pattern that is characteristic for that specific protein. Recall that this is the linear order of the amino acids as they are linked together in the protein chain (Figure 11.7).
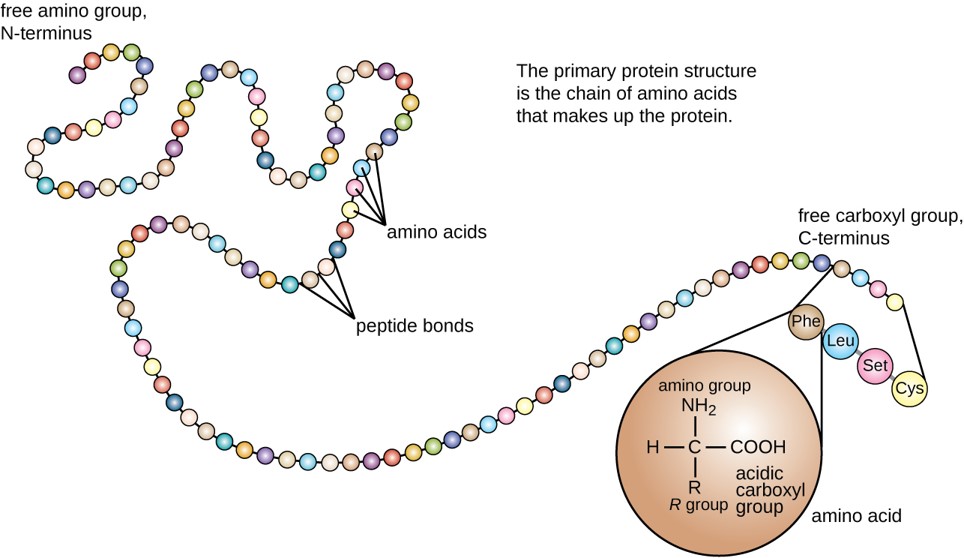
Figure 11.7 Primary protein structure is the linear sequence of amino acids.
(credit: modification of work by National Human Genome Research Institute)
Within each protein small regions may adopt specific folding patterns. These specific motifs or patterns are called secondary structure. Common secondary structural features include alpha helix and beta-pleated sheet (Figure 11.8). Within these structures, intramolecular interactions, especially hydrogen bonding between the backbone amine and carbonyl functional groups are critical to maintain 3-dimensional shape. Every helical turn in an alpha helix has 3.6 amino acid residues. The R groups (the variant groups) of the polypeptide protrude out from the α-helix chain. In the β-pleated sheet, the “pleats” are formed by hydrogen bonding between atoms on the backbone of the polypeptide chain. The R groups are attached to the carbons and extend above and below the folds of the pleat. The pleated segments align parallel or antiparallel to each other, and hydrogen bonds form between the partially positive nitrogen atom in the amino group and the partially negative oxygen atom in the carbonyl group of the peptide backbone. The α-helix and β-pleated sheet structures are found in most proteins and they play an important structural role.
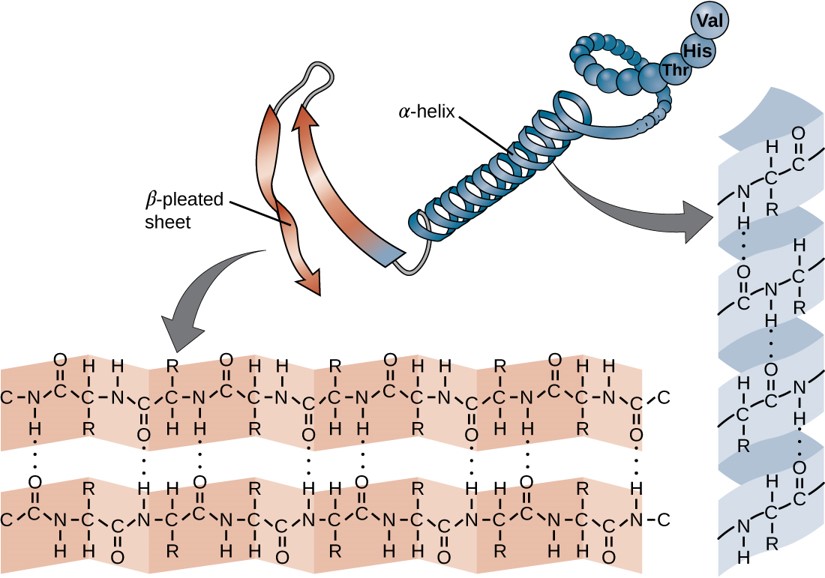
Figure 11.8 Secondary Structural Features in Protein Structure. The alpha helix and beta-pleated sheet are common structural motifs found in most proteins. They are held together by hydrogen bonding between the amine and the carbonyl oxygen within the amino acid backbone.
A Closer Look: Secondary Protein Structure in Silk
There were many trade routes throughout the ancient world. The most highly traveled and culturally significant of these was called the Silk Road. The Silk Road ran from the Chinese city of Chang’an all the way through India and into the Mediterranean and Egypt. The reason that the Silk road was so culturally significant was because of the great distance that it covered. Essentially the entire ancient world was connected by one trade route.

Figure 11.9 Silkworms
On the route many things were traded, including silk, spices, slaves, ideas, and gun powder. The silk road had an astounding effect on the creation of many societies. It was able to bring economic wealth into areas along the route, and new ideas traveled the distance and influence many things including art. An example of this is Buddhist art that was found in India. The painting has many western influences that can be identified in it, such as realistic musculature of the people being painted. Also, the trade of gun powder to the West helped influence warfare, and in turn shaped the modern world. The real reason the Silk Road was started though was for the product that it takes its name from: Silk.
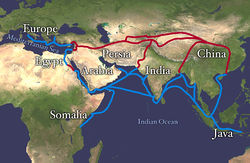
Figure 11.10 Land route in Red, Sea route in Blue
Silk was prized by the Kings and Queens of both European and Middle Eastern Society. The Silk showed that the rulers had power and wealth because the silk was not easy to come by, and therefore was definitely not cheap. Silk was first developed in China, and is made by harvesting the silk from the cocoons of the mulberry silkworm. The silk itself is called a natural protein fiber because it is composed of a pattern of amino acids in a secondary protein structure. The secondary structure of silk is the beta pleated sheet. The primary structure of silk contains the amino acids of glycine, alanine, serine, in specific repeating pattern. These three amino acids make up 90% of the protein in silk. The last 10% is comprised of the amino acids glutamic acid, valine, and aspartic acid. These amino acids are used as side chains and affect things such as elasticity and strength. they also vary between various species. The beta pleated sheet of silk is connected by hydrogen bonds. The hydrogen bonds in the silk form beta pleated sheets rather than alpha helixes because of where the bonds occur. The hydrogen bonds go from the amide hydrogens on one protein chain to the corresponding carbonyl oxygen across the way on the other protein chain. This is in contrast to the alpha helix because in that structure the bonds go from the amide to the carbonyl oxygen, but they are not adjacent. The carbonyl oxygen is on the amino acid that is four residues before.
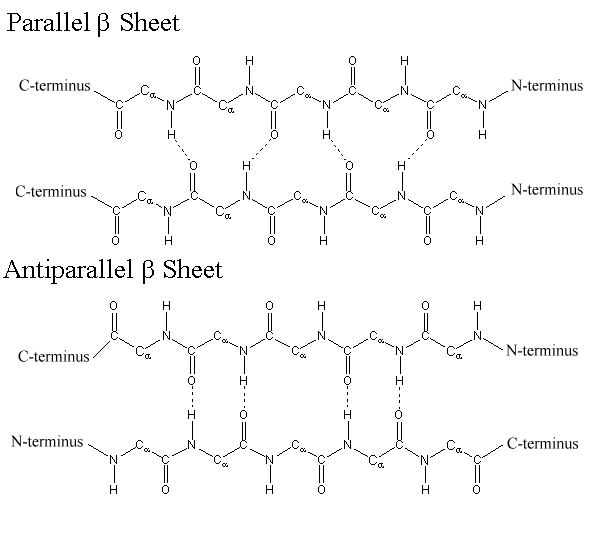
Figure 11.11 Parallel and Antiparallel Beta-Pleated Sheets
Silk is a great example of the beta pleated sheet structure. The formation of this secondary structure in the silk protein allows it to have very strong tensile strength. Silk also helped to form one of the greatest trading routes in history, allowing for the exchange of ideas, products and cultures while advancing the societies that were involved. Silk contains both anti-parallel and parallel arrangements of beta sheets. Unlike the α helix, though, the side chains are squeezed rather close together in a pleated-sheet arrangement. In consequence very bulky side chains make the structure unstable. This explains why silk is composed almost entirely of glycine, alanine, and serine, the three amino acids with the smallest side chains. Some species of silk worm produce varying amounts of bulky side chains, but these silks are not as prized as the mulberry silkworm (which has no bulky amino acid side chains) because the silk with bulky side chains is weaker and doesn’t have as much tensile strength.
The complete 3-dimensional shape of the entire protein (or sum of all the secondary structures) is known as the tertiary structure of the protein and is a unique and defining feature for that protein (Figure 11.12). Primarily, the interactions among R groups creates the complex three-dimensional tertiary structure of a protein. The nature of the R groups found in the amino acids involved can counteract the formation of the hydrogen bonds described for standard secondary structures. For example, R groups with like charges are repelled by each other and those with unlike charges are attracted to each other (ionic bonds). When protein folding takes place, the hydrophobic R groups of nonpolar amino acids lay in the interior of the protein, whereas the hydrophilic R groups lay on the outside. The former types of interactions are also known as hydrophobic interactions. Interaction between cysteine side chains forms disulfide linkages in the presence of oxygen, the only covalent bond forming during protein folding.

Figure 11.12 Tertiary Protein Structure. The tertiary structure of proteins is determined by a variety of chemical interactions. These include hydrophobic interactions, ionic bonding, hydrogen bonding and disulfide linkages.
All of these interactions, weak and strong, determine the final three-dimensional shape of the protein. When a protein loses its three-dimensional shape, it is usually no longer be functional.
In nature, some proteins are formed from several polypeptides, also known as subunits, and the interaction of these subunits forms the quaternary structure. Weak interactions between the subunits help to stabilize the overall structure. For example, insulin (a globular protein) has a combination of hydrogen bonds and disulfide bonds that cause it to be mostly clumped into a ball shape. Insulin starts out as a single polypeptide and loses some internal sequences during cellular processing that form two chains held together by disulfide linkages as shown in figure 11.6. Three of these structures are then grouped further forming an inactive hexamer (Figure 11.13). The hexamer form of insulin is a way for the body to store insulin in a stable and inactive conformation so that it is available for release and reactivation in the monomer form.
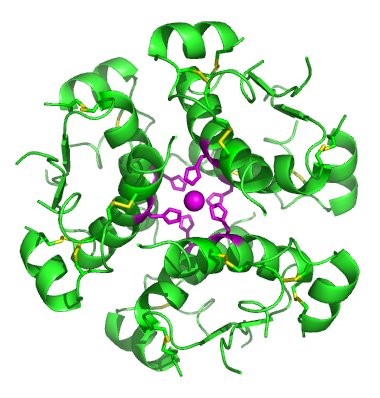
Figure 11.13 The Insulin Hormone is a Good Example of Quaternary Structure. Insulin is produced and stored in the body as a hexamer (a unit of six insulin molecules), while the active form is the monomer. The hexamer is an inactive form with long-term stability, which serves as a way to keep the highly reactive insulin protected, yet readily available.
Figure By: Isaac Yonemoto
{kind=link}
The four levels of protein structure (primary, secondary, tertiary, and quaternary) are summarized in Figure 11.14.

Figure 11.14 The four levels of protein structure can be observed in these illustrations. (credit: modification of work by National Human Genome Research Institute)
Hydrolysis is the breakdown of the primary protein sequence by the addition of water to reform the individual amino acids monomer units.
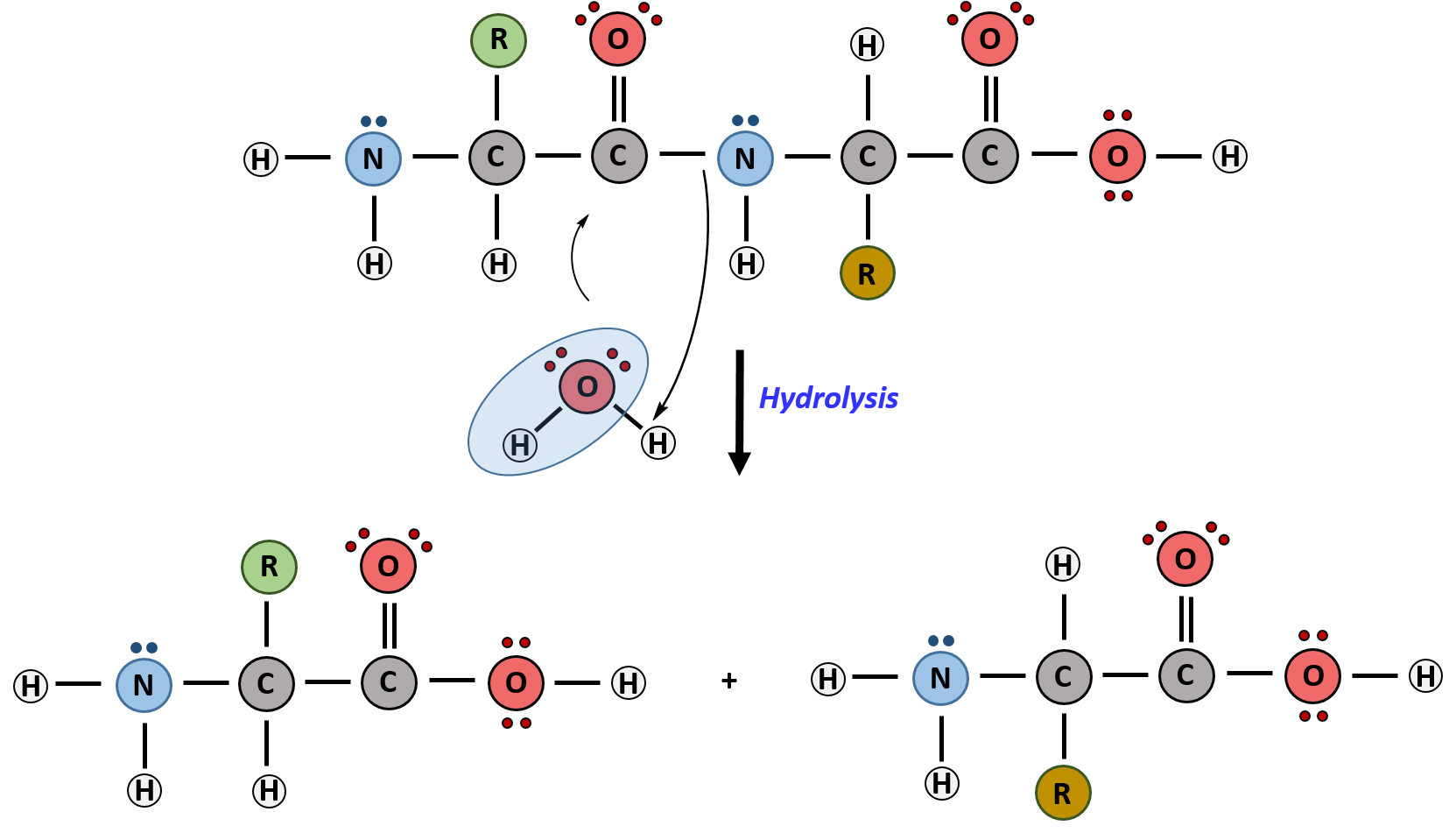
Figure 11.15 Hydrolysis of Proteins. In the hydrolysis reaction, water is added across the amide bond incorporating the -OH group with the carbonyl carbon and reforming the carboxylic acid. The hydrogen from the water reforms the amine.
If the protein is subject to changes in temperature, pH, or exposure to chemicals, the protein structure may unfold, losing its shape without breaking down the primary sequence in what is known as denaturation (Figure 11.16). Denaturation is different from hydrolysis, in that the primary strcture of the protein is not affected. Denaturation is often reversible because the primary structure of the polypeptide is conserved in the process if the denaturing agent is removed, allowing the protein to refold and resume its function. Sometimes, however, denaturation is irreversible, leading to a permanent loss of function. One example of irreversible protein denaturation is when an egg is fried. The albumin protein in the liquid egg white is denatured when placed in a hot pan. Note that not all proteins are denatured at high temperatures; for instance, bacteria that survive in hot springs have proteins that function at temperatures close to boiling. The stomach is also very acidic, has a low pH, and denatures proteins as part of the digestion process; however, the digestive enzymes of the stomach retain their activity under these conditions.
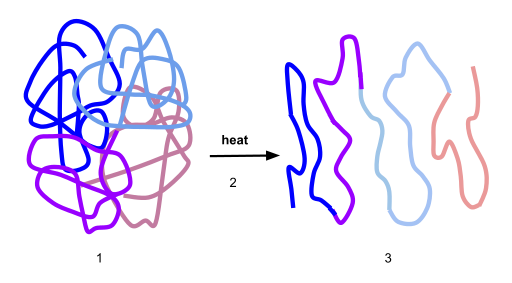
Figure 11.16 Protein Denaturation. Figure (1) depicts the correctly folded intact protein. Step (2) applies heat to the system that is above the threshold of maintaining the intramolecular protein interactions. Step (3) shows the unfolded or denatured protein. Colored regions in the denatured protein correspond to the colored regions of the natively folded protein shown in (1).
Diagram provided by: Scurran15
#/media/File:Process_of_Denaturation.svg){kind=link}
Protein folding is critical to its function. It was originally thought that the proteins themselves were responsible for the folding process. Only recently was it found that often they receive assistance in the folding process from protein helpers known as chaperones (or chaperonins) that associate with the target protein during the folding process. They act by preventing aggregation of polypeptides that make up the complete protein structure, and they disassociate from the protein once the target protein is folded.
Proteins are involved in many cellular functions. Proteins can act as enzymes which enhance the rate of chemical reactions. In fact, 99% of enzymatic reactions within a cell are mediated by proteins. Thus, they are integral in the processes of building up or breaking down of cellular components. Proteins can also act as structural scaffolding within the cell, helping to maintain cellular shape. Proteins can also be involved in cellular signaling and communication, as well as the transport of molecules from one location to another. Under extreme circumstances such as starvation, proteins can also be used as an energy source within the cell.
Review Questions:
1. What type of protein facilitates or accelerates chemical reactions?
- an enzyme
- a hormone
- a membrane transport protein
- a tRNA molecule
2. What are the monomers that make up proteins called?
- amino acids
- chaperones
- disaccharides
- nucleotides
- between the R group of one amino acid and the R group of the second
- between the carboxyl group of one amino acid and the amino group of the other
- between the 6 carbon of both amino acids
- between the nitrogen atoms of the amino groups in the amino acids
- the primary structure
- the secondary structure
- the tertiary structure
- the quaternary structure
- changes in pH
- high temperatures
- all of the above
- the addition of some chemicals
- Different amino acids produce different proteins based on the bonds formed between them.
- Differences in amino acids lead to the recycling of proteins, which produces other functional proteins.
- Different amino acids cause rearrangements of amino acids to produce a functional protein.
- Differences in the amino acids cause post-translational modification of the protein, which reassembles to produce a functional protein.
- The primary chain forms secondary α-helix and β-pleated sheets which fold onto each other forming the tertiary structure.
- The primary structure undergoes alternative splicing to form secondary structures, which fold on other protein chains to form tertiary structures.
- The primary structure forms secondary α-helix and β-pleated sheets. This further undergoes phosphorylation and acetylation to form the tertiary structure.
- The primary structure undergoes alternative splicing to form a secondary structure, and then disulfide bonds give way to tertiary structures.
11.3Lipids
Lipids, also commonly known as fats, are composed primarily of carbon and hydrogen. Due to this, lipids are predominantly hydrophobic molecules that do not dissolve with water. Lipid molecules may also contain limited amounts of oxygen, nitrogen, sulfur, and phosphorous. Lipids serve numerous and diverse purposes in the structure and functions of organisms. They can be a source of nutrients, a storage form for carbon, energy-storage molecules, structural components of membranes, and involved in chemical signaling and communication. Lipids comprise a broad class of many chemically distinct compounds, the most common of which are discussed in this section.
Fatty Acids and Triacylglycerides
The fatty acids are lipids that contain long-chain hydrocarbons terminated with a carboxylic acid functional group. Because the long hydrocarbon chain, fatty acids are hydrophobic (“water fearing”) or nonpolar. Fatty acids with hydrocarbon chains that contain only single bonds are called saturated fatty acids because they have the greatest number of hydrogen atoms possible and are, therefore, “saturated” with hydrogen. Fatty acids with hydrocarbon chains containing at least one double bond are called unsaturated fatty acids because they have fewer hydrogen atoms. Saturated fatty acids have a straight, flexible carbon backbone, whereas unsaturated fatty acids have “kinks” in their carbon skeleton because each double bond causes a rigid bend of the carbon skeleton. These differences in saturated versus unsaturated fatty acid structure result in different properties for the corresponding lipids in which the fatty acids are incorporated. For example, lipids containing saturated fatty acids are solids at room temperature, whereas lipids containing unsaturated fatty acids are liquids.
A triacylglycerol, or triglyceride, is formed when three fatty acids are chemically linked to a glycerol molecule (Figure). Triglycerides are the primary components of adipose tissue (body fat), and are major constituents of sebum (skin oils). They play an important metabolic role, serving as efficient energy-storage molecules that can provide more than double the caloric content of both carbohydrates and proteins.
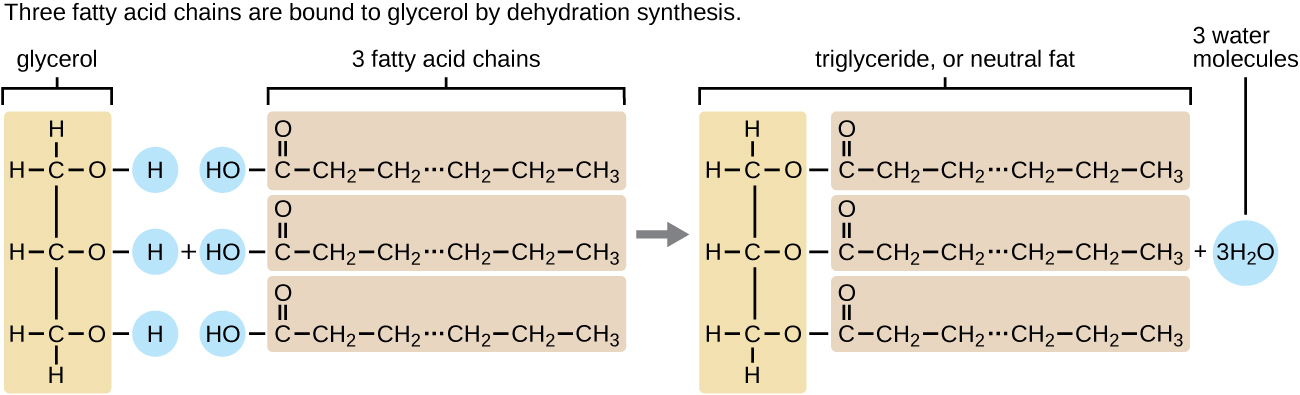
Triglycerides are composed of a glycerol molecule attached to three fatty acids by a dehydration synthesis reaction.
NOTE
- Explain why fatty acids with hydrocarbon chains that contain only single bonds are called saturated fatty acids.
Phospholipids and Biological Membranes
Triglycerides are classified as simple lipids because they are formed from just two types of compounds: glycerol and fatty acids. In contrast, complex lipids contain at least one additional component, for example, a phosphate group (phospholipids) or a carbohydrate moiety (glycolipids). Figure depicts a typical phospholipid composed of two fatty acids linked to glycerol (a diglyceride). The two fatty acid carbon chains may be both saturated, both unsaturated, or one of each. Instead of another fatty acid molecule (as for triglycerides), the third binding position on the glycerol molecule is occupied by a modified phosphate group.

This illustration shows a phospholipid with two different fatty acids, one saturated and one unsaturated, bonded to the glycerol molecule. The unsaturated fatty acid has a slight kink in its structure due to the double bond.
The molecular structure of lipids results in unique behavior in aqueous environments. Figure depicts the structure of a triglyceride. Because all three substituents on the glycerol backbone are long hydrocarbon chains, these compounds are nonpolar and not significantly attracted to polar water molecules—they are hydrophobic. Conversely, phospholipids such as the one shown in Figure have a negatively charged phosphate group. Because the phosphate is charged, it is capable of strong attraction to water molecules and thus is hydrophilic, or “water loving.” The hydrophilic portion of the phospholipid is often referred to as a polar “head,” and the long hydrocarbon chains as nonpolar “tails.” A molecule presenting a hydrophobic portion and a hydrophilic moiety is said to be amphipathic. Notice the “R” designation within the hydrophilic head depicted in Figure, indicating that a polar head group can be more complex than a simple phosphate moiety. Glycolipids are examples in which carbohydrates are bonded to the lipids’ head groups.
The amphipathic nature of phospholipids enables them to form uniquely functional structures in aqueous environments. As mentioned, the polar heads of these molecules are strongly attracted to water molecules, and the nonpolar tails are not. Because of their considerable lengths, these tails are, in fact, strongly attracted to one another. As a result, energetically stable, large-scale assemblies of phospholipid molecules are formed in which the hydrophobic tails congregate within enclosed regions, shielded from contact with water by the polar heads (Figure). The simplest of these structures are micelles, spherical assemblies containing a hydrophobic interior of phospholipid tails and an outer surface of polar head groups. Larger and more complex structures are created from lipid-bilayer sheets, or unit membranes, which are large, two-dimensional assemblies of phospholipids congregated tail to tail. The cell membranes of nearly all organisms are made from lipid-bilayer sheets, as are the membranes of many intracellular components. These sheets may also form lipid-bilayer spheres that are the structural basis of vesicles and liposomes, subcellular components that play a role in numerous physiological functions.
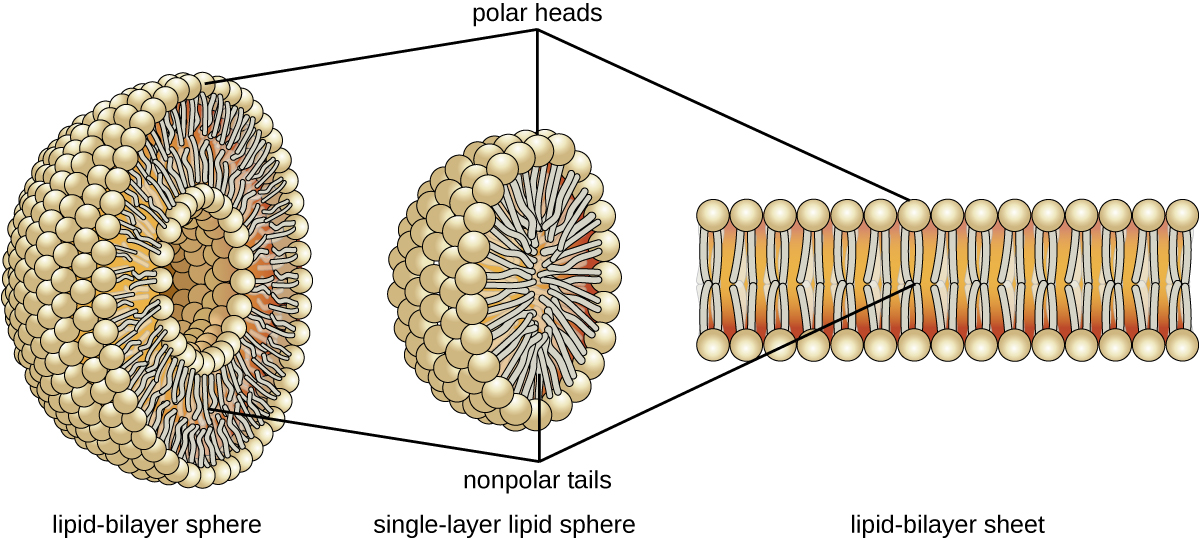
Phospholipids tend to arrange themselves in aqueous solution forming liposomes, micelles, or lipid bilayer sheets. (credit: modification of work by Mariana Ruiz Villarreal)
NOTE
- How is the amphipathic nature of phospholipids significant?
Isoprenoids and Sterols
The isoprenoids are branched lipids, also referred to as terpenoids, that are formed by chemical modifications of the isoprene molecule (Figure). These lipids play a wide variety of physiological roles in plants and animals, with many technological uses as pharmaceuticals (capsaicin), pigments (e.g., orange beta carotene, xanthophylls), and fragrances (e.g., menthol, camphor, limonene [lemon fragrance], and pinene [pine fragrance]). Long-chain isoprenoids are also found in hydrophobic oils and waxes. Waxes are typically water resistant and hard at room temperature, but they soften when heated and liquefy if warmed adequately. In humans, the main wax production occurs within the sebaceous glands of hair follicles in the skin, resulting in a secreted material called sebum, which consists mainly of triacylglycerol, wax esters, and the hydrocarbon squalene. There are many bacteria in the microbiota on the skin that feed on these lipids. One of the most prominent bacteria that feed on lipids is Propionibacterium acnes, which uses the skin’s lipids to generate short-chain fatty acids and is involved in the production of acne.
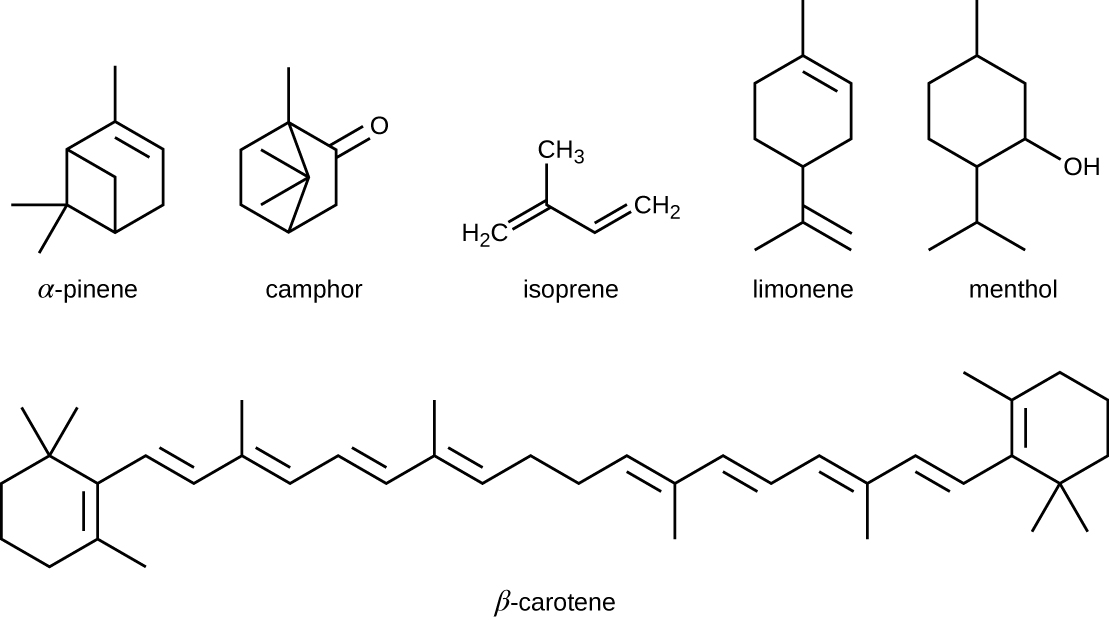
Five-carbon isoprene molecules are chemically modified in various ways to yield isoprenoids.
Another type of lipids are steroids, complex, ringed structures that are found in cell membranes; some function as hormones. The most common types of steroids are sterols, which are steroids containing an OH group. These are mainly hydrophobic molecules, but also have hydrophilic hydroxyl groups. The most common sterol found in animal tissues is cholesterol. Its structure consists of four rings with a double bond in one of the rings, and a hydroxyl group at the sterol-defining position. The function of cholesterol is to strengthen cell membranes in eukaryotes and in bacteria without cell walls, such as Mycoplasma. Prokaryotes generally do not produce cholesterol, although bacteria produce similar compounds called hopanoids, which are also multiringed structures that strengthen bacterial membranes (Figure). Fungi and some protozoa produce a similar compound called ergosterol, which strengthens the cell membranes of these organisms.
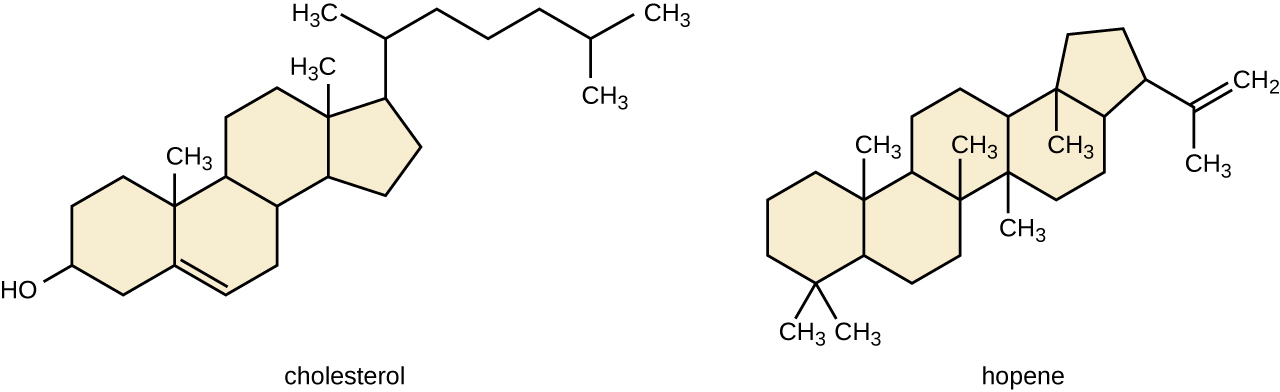
Cholesterol and hopene (a hopanoid compound) are molecules that reinforce the structure of the cell membranes in eukaryotes and prokaryotes, respectively.

This video provides additional information about phospholipids and liposomes.
NOTE
- How are isoprenoids used in technology?
The moisturizing cream prescribed by Penny’s doctor was a topical corticosteroid cream containing hydrocortisone. Hydrocortisone is a synthetic form of cortisol, a corticosteroid hormone produced in the adrenal glands, from cholesterol. When applied directly to the skin, it can reduce inflammation and temporarily relieve minor skin irritations, itching, and rashes by reducing the secretion of histamine, a compound produced by cells of the immune system in response to the presence of pathogens or other foreign substances. Because histamine triggers the body’s inflammatory response, the ability of hydrocortisone to reduce the local production of histamine in the skin effectively suppresses the immune system and helps limit inflammation and accompanying symptoms such as pruritus (itching) and rashes.
NOTE
- Does the corticosteroid cream treat the cause of Penny’s rash, or just the symptoms?
Jump to the next Clinical Focus box. Go back to the previous Clinical Focus box.
Key Concepts and Summary
- Lipids are composed mainly of carbon and hydrogen, but they can also contain oxygen, nitrogen, sulfur, and phosphorous. They provide nutrients for organisms, store carbon and energy, play structural roles in membranes, and function as hormones, pharmaceuticals, fragrances, and pigments.
- Fatty acids are long-chain hydrocarbons with a carboxylic acid functional group. Their relatively long nonpolar hydrocarbon chains make them hydrophobic. Fatty acids with no double bonds are saturated; those with double bonds are unsaturated.
- Fatty acids chemically bond to glycerol to form structurally essential lipids such as triglycerides and phospholipids. Triglycerides comprise three fatty acids bonded to glycerol, yielding a hydrophobic molecule. Phospholipids contain both hydrophobic hydrocarbon chains and polar head groups, making them amphipathicand capable of forming uniquely functional large scale structures.
- Biological membranes are large-scale structures based on phospholipid bilayers that provide hydrophilic exterior and interior surfaces suitable for aqueous environments, separated by an intervening hydrophobic layer. These bilayers are the structural basis for cell membranes in most organisms, as well as subcellular components such as vesicles.
- Isoprenoids are lipids derived from isoprene molecules that have many physiological roles and a variety of commercial applications.
- A wax is a long-chain isoprenoid that is typically water resistant; an example of a wax-containing substance is sebum, produced by sebaceous glands in the skin. Steroids are lipids with complex, ringed structures that function as structural components of cell membranes and as hormones. Sterols are a subclass of steroids containing a hydroxyl group at a specific location on one of the molecule’s rings; one example is cholesterol.
- Bacteria produce hopanoids, structurally similar to cholesterol, to strengthen bacterial membranes. Fungi and protozoa produce a strengthening agent called ergosterol.
Multiple Choice
Which of the following describes lipids?
A. a source of nutrients for organisms
B. energy-storage molecules
C. molecules having structural role in membranes
D. molecules that are part of hormones and pigments
E. all of the above
E
Molecules bearing both polar and nonpolar groups are said to be which of the following?
A. hydrophilic
B. amphipathic
C. hydrophobic
D. polyfunctional
B
True/False
Lipids are a naturally occurring group of substances that are not soluble in water but are freely soluble in organic solvents.
False
Fatty acids having no double bonds are called “unsaturated.”
True
A triglyceride is formed by joining three glycerol molecules to a fatty acid backbone in a dehydration reaction.
False
Fill in the Blank
Waxes contain esters formed from long-chain __________ and saturated __________, and they may also contain substituted hydrocarbons.
alcohols; fatty acids
Cholesterol is the most common member of the __________ group, found in animal tissues; it has a tetracyclic carbon ring system with a __________ bond in one of the rings and one free __________group.
steroid; double; hydroxyl
Critical Thinking
Microorganisms can thrive under many different conditions, including high-temperature environments such as hot springs. To function properly, cell membranes have to be in a fluid state. How do you expect the fatty acid content (saturated versus unsaturated) of bacteria living in high-temperature environments might compare with that of bacteria living in more moderate temperatures?
Short Answer
Describe the structure of a typical phospholipid. Are these molecules polar or nonpolar?
Carbohydrates Fundamentals
n CO2 + n H2O + energy  CnH2nOn + n O2 CnH2nOn + n O2 |
Introduction
The formulas of many carbohydrates can be written as carbon hydrates, Cn(H2O)n, hence their name. The carbohydrates are a major source of metabolic energy, both for plants and for animals that depend on plants for food. Aside from the sugars and starches that meet this vital nutritional role, carbohydrates also serve as a structural material (cellulose), a component of the energy transport compound ATP, recognition sites on cell surfaces, and one of three essential components of DNA and RNA.
Carbohydrates are called saccharides or, if they are relatively small, sugars. Several classifications of carbohydrates have proven useful, and are outlined in the following table.
|
||||||
|
||||||
|
||||||
|
Glucose
Carbohydrates have been given non-systematic names, although the suffix ose is generally used. The most common carbohydrate is glucose (C6H12O6). Applying the terms defined above, glucose is a monosaccharide, an aldohexose (note that the function and size classifications are combined in one word) and a reducing sugar. The general structure of glucose and many other aldohexoses was established by simple chemical reactions. The following diagram illustrates the kind of evidence considered, although some of the reagents shown here are different from those used by the original scientists.
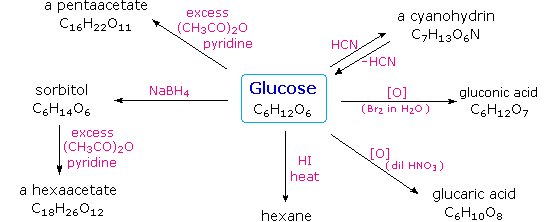
Hot hydriodic acid (HI) was often used to reductively remove oxygen functional groups from a molecule, and in the case of glucose this treatment gave hexane (in low yield). From this it was concluded that the six carbons are in an unbranched chain. The presence of an aldehyde carbonyl group was deduced from cyanohydrin formation, its reduction to the hexa-alcohol sorbitol, also called glucitol, and mild oxidation to the mono-carboxylic acid, glucuronic acid. Somewhat stronger oxidation by dilute nitric acid gave the diacid, glucaric acid, supporting the proposal of a six-carbon chain. The five oxygens remaining in glucose after the aldehyde was accounted for were thought to be in hydroxyl groups, since a penta-acetate derivative could be made. These hydroxyl groups were assigned, one each, to the last five carbon atoms, because geminal hydroxyl groups are normally unstable relative to the carbonyl compound formed by loss of water. By clicking on the above diagram, it will change to display the suggested products and the gross structure of glucose. The four middle carbon atoms in the glucose chain are centers of chirality and are colored red.
Glucose and other saccharides are extensively cleaved by periodic acid, thanks to the abundance of vicinal diol moieties in their structure. This oxidative cleavage, known as the Malaprade reaction is particularly useful for the analysis of selective O-substituted derivatives of saccharides, since ether functions do not react. The stoichiometry of aldohexose cleavage is shown in the following equation.
| HOCH2(CHOH)4CHO + 5 HIO4 | ——> | H2C=O + 5 HCO2H + 5 HIO3 |
The Configuration of Glucose
The four chiral centers in glucose indicate there may be as many as sixteen (24) stereoisomers having this constitution. These would exist as eight diastereomeric pairs of enantiomers, and the initial challenge was to determine which of the eight corresponded to glucose. This challenge was accepted and met in 1891 by the German chemist Emil Fischer. His successful negotiation of the stereochemical maze presented by the aldohexoses was a logical tour de force, and it is fitting that he received the 1902 Nobel Prize for chemistry for this accomplishment. One of the first tasks faced by Fischer was to devise a method of representing the configuration of each chiral center in an unambiguous manner. To this end, he invented a simple technique for drawing chains of chiral centers, that we now call the Fischer projection formula. Click on this link for a review.
At the time Fischer undertook the glucose project it was not possible to establish the absolute configuration of an enantiomer. Consequently, Fischer made an arbitrary choice for (+)-glucose and established a network of related aldose configurations that he called the D-family. The mirror images of these configurations were then designated the L-family of aldoses. To illustrate using present day knowledge, Fischer projection formulas and names for the D-aldose family (three to six-carbon atoms) are shown below, with the asymmetric carbon atoms (chiral centers) colored red. The last chiral center in an aldose chain (farthest from the aldehyde group) was chosen by Fischer as the D / L designator site. If the hydroxyl group in the projection formula pointed to the right, it was defined as a member of the D-family. A left directed hydroxyl group (the mirror image) then represented the L-family. Fischer’s initial assignment of the D-configuration had a 50:50 chance of being right, but all his subsequent conclusions concerning the relative configurations of various aldoses were soundly based. In 1951 x-ray fluorescence studies of (+)-tartaric acid, carried out in the Netherlands by Johannes Martin Bijvoet (pronounced “buy foot”), proved that Fischer’s choice was correct.
It is important to recognize that the sign of a compound’s specific rotation (an experimental number) does not correlate with its configuration (D or L). It is a simple matter to measure an optical rotation with a polarimeter. Determining an absolute configuration usually requires chemical interconversion with known compounds by stereospecific reaction paths.
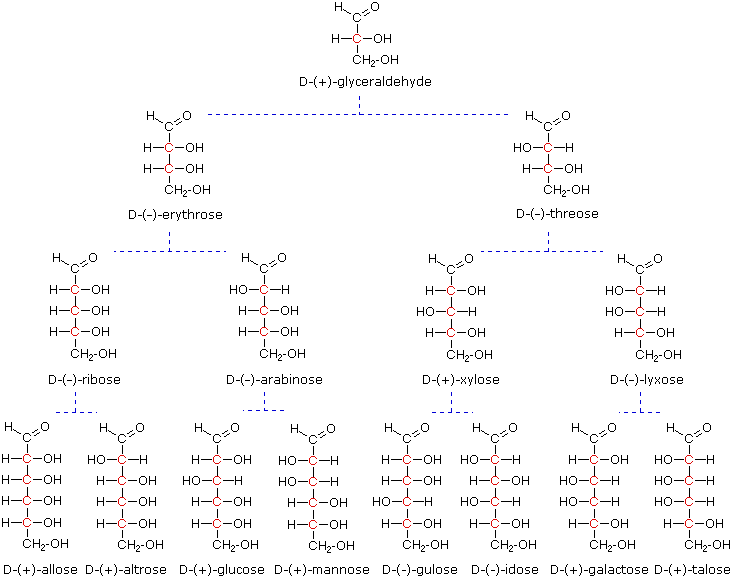
Models of representative aldoses may be examined by clicking on the Fischer formulas for glyceraldehyde, erythrose, threose, ribose, arabinose, allose, altrose, glucose or mannose in the above diagram.
Important Reactions
Emil Fischer made use of several key reactions in the course of his carbohydrate studies. These are described here, together with the information that each delivers.
Oxidation
As noted above, sugars may be classified as reducing or non-reducing based on their reactivity with Tollens’, Benedict’s or Fehling’s reagents. If a sugar is oxidized by these reagents it is calledreducing, since the oxidant (Ag(+) or Cu(+2)) is reduced in the reaction, as evidenced by formation of a silver mirror or precipitation of cuprous oxide. The Tollens’ test is commonly used to detect aldehyde functions; and because of the facile interconversion of ketoses and aldoses under the basic conditions of this test, ketoses such as fructose also react and are classified as reducing sugars.
When the aldehyde function of an aldose is oxidized to a carboxylic acid the product is called an aldonic acid. Because of the 2º hydroxyl functions that are also present in these compounds, a mild oxidizing agent such as hypobromite must be used for this conversion (equation 1). If both ends of an aldose chain are oxidized to carboxylic acids the product is called an aldaric acid. By converting an aldose to its corresponding aldaric acid derivative, the ends of the chain become identical (this could also be accomplished by reducing the aldehyde to CH2OH, as noted below). Such an operation will disclose any latent symmetry in the remaining molecule. Thus, ribose, xylose, allose and galactose yield achiral aldaric acids which are, of course, not optically active. The ribose oxidation is shown in equation 2 below.
| 1. | 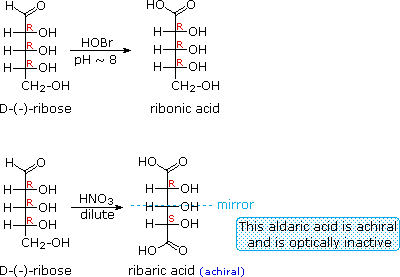 |
|---|---|
| 2. | |
| 3. | 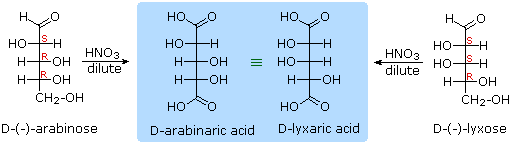 |
Other aldose sugars may give identical chiral aldaric acid products, implying a unique configurational relationship. The examples of arabinose and lyxose shown in equation 3 above illustrate this result. Remember, a Fischer projection formula may be rotated by 180º in the plane of projection without changing its configuration.
Reduction
Sodium borohydride reduction of an aldose makes the ends of the resulting alditol chain identical, HOCH2(CHOH)nCH2OH, thereby accomplishing the same configurational change produced by oxidation to an aldaric acid. Thus, allitol and galactitol from reduction of allose and galactose are achiral, and altrose and talose are reduced to the same chiral alditol. A summary of these redox reactions, and derivative nomenclature is given in the following table.
| Derivatives of HOCH2(CHOH)nCHO | ||
|---|---|---|
| HOBr Oxidation | ——> | HOCH2(CHOH)nCO2H an Aldonic Acid |
| HNO3 Oxidation | ——> | H2OC(CHOH)nCO2H an Aldaric Acid |
| NaBH4 Reduction | ——> | HOCH2(CHOH)nCH2OH an Alditol |
Carbohydrate Classification
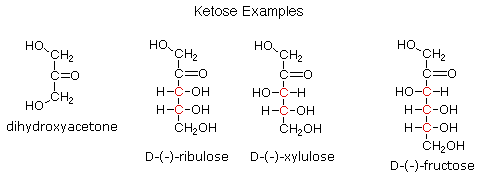
Ketoses
If a monosaccharide has a carbonyl function on one of the inner atoms of the carbon chain it is classified as a ketose. Dihydroxyacetone may not be a sugar, but it is included as the ketose analog of glyceraldehyde. The carbonyl group is commonly found at C-2, as illustrated by the following examples (chiral centers are colored red). As expected, the carbonyl function of a ketose may be reduced by sodium borohydride, usually to a mixture of epimeric products. D-Fructose, the sweetest of the common natural sugars, is for example reduced to a mixture of D-glucitol (sorbitol) and D-mannitol, named after the aldohexoses from which they may also be obtained by analogous reduction. Mannitol is itself a common natural carbohydrate.
Although the ketoses are distinct isomers of the aldose monosaccharides, the chemistry of both classes is linked due to their facile interconversion in the presence of acid or base catalysts. This interconversion, and the corresponding epimerization at sites alpha to the carbonyl functions, occurs by way of an enediol tautomeric intermediate. By clicking on the diagram, an equation illustrating these isomerizations will be displayed.
Because of base-catalyzed isomerizations of this kind, the Tollens’ reagent is not useful for distinguishing aldoses from ketoses or for specific oxidation of aldoses to the corresponding aldonic acids. Oxidation by HOBr is preferred for the latter conversion.
Anomeric Forms of Glucose
Fischer’s brilliant elucidation of the configuration of glucose did not remove all uncertainty concerning its structure. Two different crystalline forms of glucose were reported in 1895. Each of these gave all the characteristic reactions of glucose, and when dissolved in water equilibrated to the same mixture. This equilibration takes place over a period of many minutes, and the change in optical activity that occurs is called mutarotation. These facts are summarized in the diagram below.
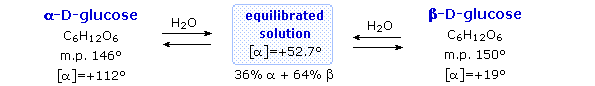
When glucose was converted to its pentamethyl ether (reaction with excess CH3I & AgOH), two different isomers were isolated, and neither exhibited the expected aldehyde reactions. Acid-catalyzed hydrolysis of the pentamethyl ether derivatives, however, gave a tetramethyl derivative that was oxidized by Tollen’s reagent and reduced by sodium borohydride, as expected for an aldehyde. These reactions will be displayed above by clicking on the diagram.
The search for scientific truth often proceeds in stages, and the structural elucidation of glucose serves as a good example. It should be clear from the new evidence presented above, that the open chain pentahydroxyhexanal structure drawn above must be modified. Somehow a new stereogenic center must be created, and the aldehyde must be deactivated in the pentamethyl derivative. A simple solution to this dilemma is achieved by converting the open aldehyde structure for glucose into a cyclic hemiacetal, called a glucopyranose, as shown in the following diagram. The linear aldehyde is tipped on its side, and rotation about the C4-C5 bond brings the C5-hydroxyl function close to the aldehyde carbon. For ease of viewing, the six-membered hemiacetal structure is drawn as a flat hexagon, but it actually assumes a chair conformation. The hemiacetal carbon atom (C-1) becomes a new stereogenic center, commonly referred to as the anomeric carbon, and the α and β-isomers are called anomers.
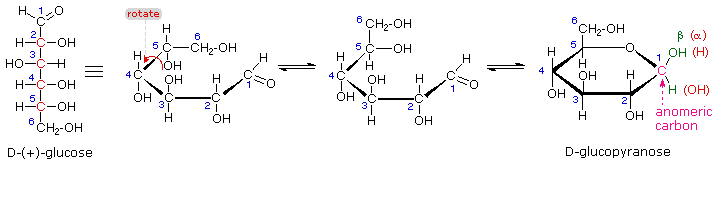
We can now consider how this modification of the glucose structure accounts for the puzzling facts noted above. First, we know that hemiacetals are in equilibrium with their carbonyl and alcohol components when in solution. Consequently, fresh solutions of either alpha or beta-glucose crystals in water should establish an equilibrium mixture of both anomers, plus the open chain chain form. This will be shown above by clicking on the diagram. Note that despite the very low concentration of the open chain aldehyde in this mixture, typical chemical reactions of aldehydes take place rapidly.
Second, a pentamethyl ether derivative of the pyranose structure converts the hemiacetal function to an acetal. Acetals are stable to base, so this product should not react with Tollen’s reagent or be reduced by sodium borohydride. Acid hydrolysis of acetals regenerates the carbonyl and alcohol components, and in the case of the glucose derivative this will be a tetramethyl ether of the pyranose hemiacetal. This compound will, of course, undergo typical aldehyde reactions. By clicking on the diagram a second time this relationship will be displayed above.
5. Cyclic Forms of Monosaccharides
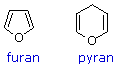
As noted above, the preferred structural form of many monosaccharides may be that of a cyclic hemiacetal. Five and six-membered rings are favored over other ring sizes because of their low angle and eclipsing strain. Cyclic structures of this kind are termed furanose (five-membered) or pyranose (six-membered), reflecting the ring size relationship to the common heterocyclic compounds furan and pyran shown on the right. Ribose, an important aldopentose, commonly adopts a furanose structure, as shown in the following illustration. By convention for the D-family, the five-membered furanose ring is drawn in an edgewise projection with the ring oxygen positioned away from the viewer. The anomeric carbon atom (colored red here) is placed on the right. The upper bond to this carbon is defined as beta, the lower bond then is alpha.
Click on the following diagram to see a model of β-D-ribofuranose.

The cyclic pyranose forms of various monosaccharides are often drawn in a flat projection known as a Haworth formula, after the British chemist, Norman Haworth. As with the furanose ring, the anomeric carbon is placed on the right with the ring oxygen to the back of the edgewise view. In the D-family, the alpha and beta bonds have the same orientation defined for the furanose ring (beta is up & alpha is down). These Haworth formulas are convenient for displaying stereochemical relationships, but do not represent the true shape of the molecules. We know that these molecules are actually puckered in a fashion we call a chair conformation. Examples of four typical pyranose structures are shown below, both as Haworth projections and as the more representative chair conformers. The anomeric carbons are colored red.
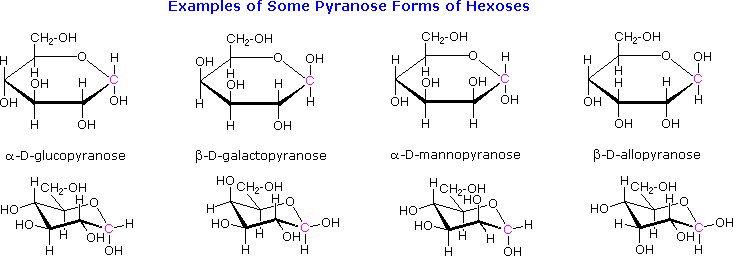
Models of these glucose, galactose, mannose and allose pyranose structures may be viewed by Clicking Here.
A practice page for examining the configurations of aldohexoses may be viewed by Clicking Here.
The size of the cyclic hemiacetal ring adopted by a given sugar is not constant, but may vary with substituents and other structural features. Aldolhexoses usually form pyranose rings and their pentose homologs tend to prefer the furanose form, but there are many counter examples. The formation of acetal derivatives illustrates how subtle changes may alter this selectivity. By clicking on the above diagram. the display will change to illustrate this. A pyranose structure for D-glucose is drawn in the rose-shaded box on the left. Acetal derivatives have been prepared by acid-catalyzed reactions with benzaldehyde and acetone. As a rule, benzaldehyde forms six-membered cyclic acetals, whereas acetone prefers to form five-membered acetals. The top equation shows the formation and some reactions of the 4,6-O-benzylidene acetal, a commonly employed protective group. A methyl glycoside derivative of this compound (see below) leaves the C-2 and C-3 hydroxyl groups exposed to reactions such as the periodic acid cleavage, shown as the last step. The formation of an isopropylidene acetal at C-1 and C-2, center structure, leaves the C-3 hydroxyl as the only unprotected function. Selective oxidation to a ketone is then possible. Finally, direct di-O-isopropylidene derivatization of glucose by reaction with excess acetone results in a change to a furanose structure in which the C-3 hydroxyl is again unprotected. However, the same reaction with D-galactose, shown in the blue-shaded box, produces a pyranose product in which the C-6 hydroxyl is unprotected. Both derivatives do not react with Tollens’ reagent. This difference in behavior is attributed to the cis-orientation of the C-3 and C-4 hydroxyl groups in galactose, which permits formation of a less strained five-membered cyclic acetal, compared with the trans-C-3 and C-4 hydroxyl groups in glucose. Derivatizations of this kind permit selective reactions to be conducted at different locations in these highly functionalized molecules.
The ring size of these cyclic monosaccharides was determined by oxidation and chain cleavage of their tetra methyl ether derivatives. To see how this was done for glucose Click Here.
6. Glycosides
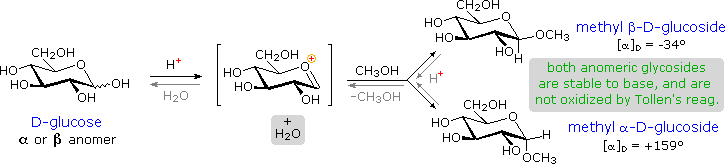
Acetal derivatives formed when a monosaccharide reacts with an alcohol in the presence of an acid catalyst are called glycosides. This reaction is illustrated for glucose and methanol in the diagram below. In naming of glycosides, the “ose” suffix of the sugar name is replaced by “oside”, and the alcohol group name is placed first. As is generally true for most acetals, glycoside formation involves the loss of an equivalent of water. The diether product is stable to base and alkaline oxidants such as Tollen’s reagent. Since acid-catalyzed aldolization is reversible, glycosides may be hydrolyzed back to their alcohol and sugar components by aqueous acid.
The anomeric methyl glucosides are formed in an equilibrium ratio of 66% alpha to 34% beta. From the structures in the previous diagram, we see that pyranose rings prefer chair conformations in which the largest number of substituents are equatorial. In the case of glucose, the substituents on the beta-anomer are all equatorial, whereas the C-1 substituent in the alpha-anomer changes to axial. Since substituents on cyclohexane rings prefer an equatorial location over axial (methoxycyclohexane is 75% equatorial), the preference for alpha-glycopyranoside formation is unexpected, and is referred to as the anomeric effect.
Glycosides abound in biological systems. By attaching a sugar moiety to a lipid or benzenoid structure, the solubility and other properties of the compound may be changed substantially. Because of the important modifying influence of such derivatization, numerous enzyme systems, known as glycosidases, have evolved for the attachment and removal of sugars from alcohols, phenols and amines. Chemists refer to the sugar component of natural glycosides as the glycon and the alcohol component as the aglycon. Two examples of naturally occurring glycosides and one example of an amino derivative will be displayed above by clicking on the diagram. Salicin, one of the oldest herbal remedies known, was the model for the synthetic analgesic aspirin. A large class of hydroxylated, aromatic oxonium cations called anthocyanins provide the red, purple and blue colors of many flowers, fruits and some vegetables. Peonin is one example of this class of natural pigments, which exhibit a pronounced pH color dependence. The oxonium moiety is only stable in acidic environments, and the color changes or disappears when base is added. The complex changes that occur when wine is fermented and stored are in part associated with glycosides of anthocyanins. Finally, amino derivatives of ribose, such as cytidine play important roles in biological phosphorylating agents, coenzymes and information transport and storage materials.
For a discussion of the anomeric effect Click Here. For examples of structurally and functionally modified sugars Click Here.
Disaccharides
When the alcohol component of a glycoside is provided by a hydroxyl function on another monosaccharide, the compound is called a disaccharide. Four examples of disaccharides composed of two glucose units are shown in the following diagram. The individual glucopyranose rings are labeled A and B, and the glycoside bonding is circled in light blue. Notice that the glycoside bond may be alpha, as in maltose and trehalose, or beta as in cellobiose and gentiobiose. Acid-catalyzed hydrolysis of these disaccharides yields glucose as the only product. Enzyme-catalyzed hydrolysis is selective for a specific glycoside bond, so an alpha-glycosidase cleaves maltose and trehalose to glucose, but does not cleave cellobiose or gentiobiose. A beta-glycosidase has the opposite activity.
In order to draw a representative structure for cellobiose, one of the glucopyranose rings must be rotated by 180º, but this feature is often omitted in favor of retaining the usual perspective for the individual rings. The bonding between the glucopyranose rings in cellobiose and maltose is from the anomeric carbon in ring A to the C-4 hydroxyl group on ring B. This leaves the anomeric carbon in ring B free, so cellobiose and maltose both may assume alpha and beta anomers at that site (the beta form is shown in the diagram). Gentiobiose has a beta-glycoside link, originating at C-1 in ring A and terminating at C-6 in ring B. Its alpha-anomer is drawn in the diagram. Because cellobiose, maltose and gentiobiose are hemiacetals they are all reducing sugars (oxidized by Tollen’s reagent). Trehalose, a disaccharide found in certain mushrooms, is a bis-acetal, and is therefore a non-reducing sugar. A systematic nomenclature for disaccharides exists, but as the following examples illustrate, these are often lengthy.
- Cellobiose : 4-O-β-D-Glucopyranosyl-D-glucose (the beta-anomer is drawn)
- Maltose : 4-O-α-D-Glucopyranosyl-D-glucose (the beta-anomer is drawn)
- Gentiobiose : 6-O-β-D-Glucopyranosyl-D-glucose (the alpha-anomer is drawn)
- Trehalose : α-D-Glucopyranosyl-α-D-glucopyranoside
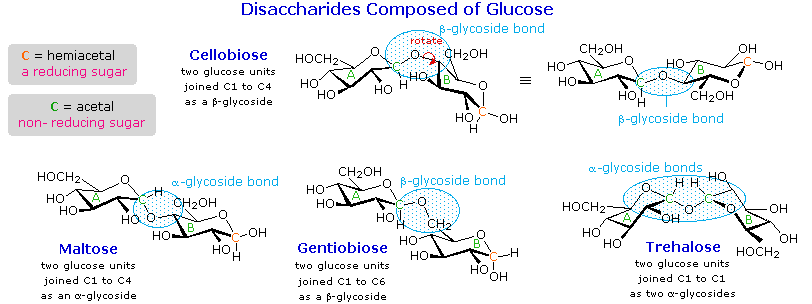
Although all the disaccharides shown here are made up of two glucopyranose rings, their properties differ in interesting ways. Maltose, sometimes called malt sugar, comes from the hydrolysis of starch. It is about one third as sweet as cane sugar (sucrose), is easily digested by humans, and is fermented by yeast. Cellobiose is obtained by the hydrolysis of cellulose. It has virtually no taste, is indigestible by humans, and is not fermented by yeast. Some bacteria have beta-glucosidase enzymes that hydrolyze the glycosidic bonds in cellobiose and cellulose. The presence of such bacteria in the digestive tracts of cows and termites permits these animals to use cellulose as a food. Finally, it may be noted that trehalose has a distinctly sweet taste, but gentiobiose is bitter.
Disaccharides made up of other sugars are known, but glucose is often one of the components. Two important examples of such mixed disaccharides will be displayed above by clicking on the diagram. Lactose, also known as milk sugar, is a galactose-glucose compound joined as a beta-glycoside. It is a reducing sugar because of the hemiacetal function remaining in the glucose moiety. Many adults, particularly those from regions where milk is not a dietary staple, have a metabolic intolerance for lactose. Infants have a digestive enzyme which cleaves the beta-glycoside bond in lactose, but production of this enzyme stops with weaning. Cheese is less subject to the lactose intolerance problem, since most of the lactose is removed with the whey. Sucrose, or cane sugar, is our most commonly used sweetening agent. It is a non-reducing disaccharide composed of glucose and fructose joined at the anomeric carbon of each by glycoside bonds (one alpha and one beta). In the formula shown here the fructose ring has been rotated 180º from its conventional perspective.
To examine a model of sucrose Click Here
Additional Topics
For a brief discussion of sweetening agents Click Here. For examples of some larger saccharide oligomers Click Here.
Polysaccharides
As the name implies, polysaccharides are large high-molecular weight molecules constructed by joining monosaccharide units together by glycosidic bonds. They are sometimes called glycans. The most important compounds in this class, cellulose, starch and glycogen are all polymers of glucose. This is easily demonstrated by acid-catalyzed hydrolysis to the monosaccharide. Since partial hydrolysis of cellulose gives varying amounts of cellobiose, we conclude the glucose units in this macromolecule are joined by beta-glycoside bonds between C-1 and C-4 sites of adjacent sugars. Partial hydrolysis of starch and glycogen produces the disaccharide maltose together with low molecular weight dextrans, polysaccharides in which glucose molecules are joined by alpha-glycoside links between C-1 and C-6, as well as the alpha C-1 to C-4 links found in maltose. Polysaccharides built from other monosaccharides (e.g. mannose, galactose, xylose and arabinose) are also known, but will not be discussed here.
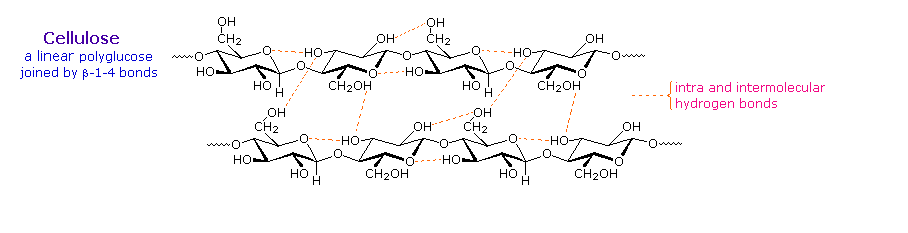
Over half of the total organic carbon in the earth’s biosphere is in cellulose. Cotton fibers are essentially pure cellulose, and the wood of bushes and trees is about 50% cellulose. As a polymer of glucose, cellulose has the formula (C6H10O5)n where n ranges from 500 to 5,000, depending on the source of the polymer. The glucose units in cellulose are linked in a linear fashion, as shown in the drawing below. The beta-glycoside bonds permit these chains to stretch out, and this conformation is stabilized by intramolecular hydrogen bonds. A parallel orientation of adjacent chains is also favored by intermolecular hydrogen bonds. Although an individual hydrogen bond is relatively weak, many such bonds acting together can impart great stability to certain conformations of large molecules. Most animals cannot digest cellulose as a food, and in the diets of humans this part of our vegetable intake functions as roughage and is eliminated largely unchanged. Some animals (the cow and termites, for example) harbor intestinal microorganisms that breakdown cellulose into monosaccharide nutrients by the use of beta-glycosidase enzymes.
Cellulose is commonly accompanied by a lower molecular weight, branched, amorphous polymer called hemicellulose. In contrast to cellulose, hemicellulose is structurally weak and is easily hydrolyzed by dilute acid or base. Also, many enzymes catalyze its hydrolysis. Hemicelluloses are composed of many D-pentose sugars, with xylose being the major component. Mannose and mannuronic acid are often present, as well as galactose and galacturonic acid.
Starch is a polymer of glucose, found in roots, rhizomes, seeds, stems, tubers and corms of plants, as microscopic granules having characteristic shapes and sizes. Most animals, including humans, depend on these plant starches for nourishment. The structure of starch is more complex than that of cellulose. The intact granules are insoluble in cold water, but grinding or swelling them in warm water causes them to burst.
The released starch consists of two fractions. About 20% is a water soluble material called amylose. Molecules of amylose are linear chains of several thousand glucose units joined by alpha C-1 to C-4 glycoside bonds. Amylose solutions are actually dispersions of hydrated helical micelles. The majority of the starch is a much higher molecular weight substance, consisting of nearly a million glucose units, and called amylopectin. Molecules of amylopectin are branched networks built from C-1 to C-4 and C-1 to C-6 glycoside links, and are essentially water insoluble. Representative structural formulas for amylose and amylopectin will be shown above by clicking on the diagram. To see an expanded structure for amylopectin click again on the diagram. The branching in this diagram is exaggerated, since on average, branches only occur every twenty five glucose units.
Hydrolysis of starch, usually by enzymatic reactions, produces a syrupy liquid consisting largely of glucose. When cornstarch is the feedstock, this product is known as corn syrup. It is widely used to soften texture, add volume, prohibit crystallization and enhance the flavor of foods.
Glycogen is the glucose storage polymer used by animals. It has a structure similar to amylopectin, but is even more highly branched (about every tenth glucose unit). The degree of branching in these polysaccharides may be measured by enzymatic or chemical analysis.
For examples of chemical analysis of branching Click Here.
Synthetic Modification of Cellulose
Cotton, probably the most useful natural fiber, is nearly pure cellulose. The manufacture of textiles from cotton involves physical manipulation of the raw material by carding, combing and spinning selected fibers. For fabrics the best cotton has long fibers, and short fibers or cotton dust are removed. Crude cellulose is also available from wood pulp by dissolving the lignan matrix surrounding it. These less desirable cellulose sources are widely used for making paper.
In order to expand the ways in which cellulose can be put to practical use, chemists have devised techniques for preparing solutions of cellulose derivatives that can be spun into fibers, spread into a film or cast in various solid forms. A key factor in these transformations are the three free hydroxyl groups on each glucose unit in the cellulose chain, –[C6H7O(OH)3]n–. Esterification of these functions leads to polymeric products having very different properties compared with cellulose itself.
Cellulose Nitrate, first prepared over 150 years ago by treating cellulose with nitric acid, is the earliest synthetic polymer to see general use. The fully nitrated compound, –[C6H7O(ONO2)3]n–, called guncotton, is explosively flammable and is a component of smokeless powder. Partially nitrated cellulose is called pyroxylin. Pyroxylin is soluble in ether and at one time was used for photographic film and lacquers. The high flammability of pyroxylin caused many tragic cinema fires during its period of use. Furthermore, slow hydrolysis of pyroxylin yields nitric acid, a process that contributes to the deterioration of early motion picture films in storage.
Cellulose Acetate, –[C6H7O(OAc)3]n–, is less flammable than pyroxylin, and has replaced it in most applications. It is prepared by reaction of cellulose with acetic anhydride and an acid catalyst. The properties of the product vary with the degree of acetylation. Some chain shortening occurs unavoidably in the preparations. An acetone solution of cellulose acetate may be forced through a spinneret to generate filaments, called acetate rayon, that can be woven into fabrics.
Viscose Rayon, is prepared by formation of an alkali soluble xanthate derivative that can be spun into a fiber that reforms the cellulose polymer by acid quenching. The following general equation illustrates these transformations. The product fiber is called viscose rayon.
| ROH | NaOH |
RO(-) Na(+) + S=C=S | |
RO-CS2(-) Na(+) | H3O(+) |
ROH |
| cellulose | viscose solution | rayon |
Carbohydrate Isomers
Introduction
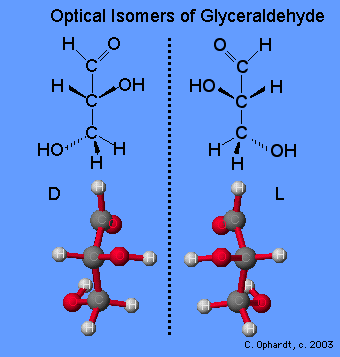
Glyceraldehyde can exist in two isomeric forms that are mirror images of each other which are shown below. The absolute configuration is defined by the molecule on the far left as the D-glyceraldehyde. With the aldehyde group in the “up” direction, the the -OH group must project to the right side of the molecule for the D isomer. Chemists have used this configuration of D-glyceraldehyde to determine the optical isomer families of the rest of the carbohydrates. All naturally occurring monosaccharides belong to the D optical family. It is remarkable that the chemistry and enzymes of all living things can tell the difference between the geometry of one optical isomer over the other.
Monosaccharides are assigned to the D-family according to the projection of the -OH group to the right on the chiral carbon that is the farthest from the carbonyl (aldehyde) group. This is on carbon # 5 if the carbonyl carbon is # 1.
Note: For whatever reason, the ball and stick model does not completely match the projections of the -OH groups on carbons # 2 and 4. It is in the way that the flat Fischer model has been defined.
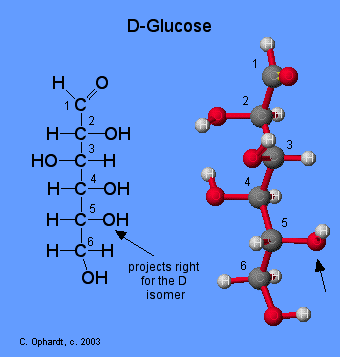
How many chiral carbons can you find? List them. If necessary Review Chiral Compounds to find the definitions.Then check the answer from the drop down menu.
Compare Glucose and Galactose
Examine the structures of glucose and galactose carefully. Which -OH group determines that they both are the D isomer? Then check the answer from the drop down menu.
Isomers have different arrangements of atoms. Which carbon bonding to -OH and -H is different in glucose vs. galactose? This single difference makes glucose and galactose isomers. Then check the answer from the drop down menu.

Carbohydrate Overview
Introduction
The chemistry of carbohydrates most closely resembles that of alcohol, aldehyde, and ketone functional groups. As a result, the modern definition of a CARBOHYDRATE is that the compounds are polyhydroxy aldehydes or ketones. The chemistry of carbohydrates is complicated by the fact that there is a functional group (alcohol) on almost every carbon. In addition, the carbohydrate may exist in either a straight chain or a ring structure. Ring structures incorporate two additional functional groups: the hemiacetal and acetal.
A major part of the carbon cycle occurs as carbon dioxide is converted to carbohydrates through photosynthesis. Carbohydrates are utilized by animals and humans in metabolism to produce energy and other compounds.
Photosynthesis is a complex series of reactions carried out by algae, phytoplankton, and the leaves in plants, which utilize the energy from the sun. The simplified version of this chemical reaction is to utilize carbon dioxide molecules from the air and water molecules and the energy from the sun to produce a simple sugar such as glucose and oxygen molecules as a by product. The simple sugars are then converted into other molecules such as starch, fats, proteins, enzymes, and DNA/RNA i.e. all of the other molecules in living plants. All of the “matter/stuff” of a plant ultimately is produced as a result of this photosynthesis reaction.
Di- and Poly-Carbohydrates
- Monosaccharides contain one sugar unit such as glucose, galactose, fructose, etc.
- Disaccharides contain two sugar units. In almost all cases one of the sugars is glucose, with the other sugar being galactose, fructose, or another glucose. Common disaccharides are maltose, lactose, and sucrose.
- Polysaccharides contain many sugar units in long polymer chains of many repeating units. The most common sugar unit is glucose. Common poly saccharides are starch, glycogen, and cellulose.
Table 1: Common Carbohydrates
| Name | Derivation of name and Source |
|---|---|
| Monosaccharides | |
| Glucose | From Greek word for sweet wine; grape sugar, blood sugar, dextrose. |
| Galactose | Greek word for milk–“galact”, found as a component of lactose in milk. |
| Fructose | Latin word for fruit–“fructus”, also known as levulose,found in fruits and honey; sweetest sugar. |
| Ribose | Ribose and Deoxyribose are found in the backbone structure of RNA and DNA, respectively. |
| Disaccharides – contain two monosaccharides | |
| Sucrose | French word for sugar–“sucre”, a disaccharide containing glucose and fructose; table sugar, cane sugar, beet sugar. |
| Lactose | Latin word for milk–“lact”; a disaccharide found in milk containing glucose and galactose. |
| Maltose | French word for “malt”; a disaccharide containing two units of glucose; found in germinating grains, used to make beer. |
| Common Polysaccharides | |
| Starch | Plants store glucose as the polysaccharide starch. The cereal grains (wheat, rice, corn, oats, barley) as well as tubers such as potatoes are rich in starch. |
| Cellulose | The major component in the rigid cell walls in plants is cellulose and is a linear polysaccharide polymer with many glucose monosaccharide units. |
| Glycogen | This is the storage form of glucose in animals and humans which is analogous to the starch in plants. Glycogen is synthesized and stored mainly in the liver and the muscles. |
Metabolism
Metabolism occurs in animals and humans after the ingestion of organic plant or animal foods. In the cells a series of complex reactions occurs with oxygen to convert for example glucose sugar into the products of carbon dioxide and water and ENERGY. This reaction is also carried out by bacteria in the decomposition/decay of waste materials on land and in the water.
Combustion occurs when any organic material is reacted (burned) in the presence of oxygen to give off the products of carbon dioxide and water and ENERGY. The organic material can be any fossil fuel such as natural gas (methane), oil, or coal. Other organic materials that combust are wood, paper, plastics, and cloth.
The whole purpose of both processes is to convert chemical energy into other forms of energy such as heat.
Haworth Formula
 This representation of rings is known as the Haworth formula. eg: cyclic forms of D-glucose
This representation of rings is known as the Haworth formula. eg: cyclic forms of D-glucose To generate the Haworth formulas of the cyclic forms of a monosaccharide, use the following procedure, explained using the pyranoses of D-glucose.Step 1: Draw the Fischer projection of the acyclic form of D-glucose. (See D,L convention)
To generate the Haworth formulas of the cyclic forms of a monosaccharide, use the following procedure, explained using the pyranoses of D-glucose.Step 1: Draw the Fischer projection of the acyclic form of D-glucose. (See D,L convention) Step 2: Number the carbon chain in 1 starting at the top.
Step 2: Number the carbon chain in 1 starting at the top. Step 3: To generate the pyranose ring, the oxygen atom on C-5 in 1 needs to be attached to C-1 by a single bond.
Step 3: To generate the pyranose ring, the oxygen atom on C-5 in 1 needs to be attached to C-1 by a single bond.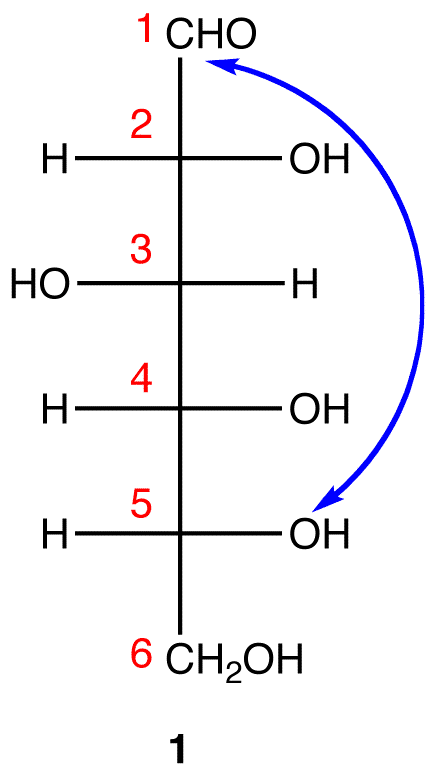 In 1, C-1 is behind the plane of the paper and the hydroxy group on C-5 is in front. For the pyranose ring to be planar, both C-1 and the hydroxy group on C-5 have to be either behind or in front of the plane of the paper. C-5 is a chiral center. In order to bring the hydroxy group on C-5 to the site occupied by the CH2OH
In 1, C-1 is behind the plane of the paper and the hydroxy group on C-5 is in front. For the pyranose ring to be planar, both C-1 and the hydroxy group on C-5 have to be either behind or in front of the plane of the paper. C-5 is a chiral center. In order to bring the hydroxy group on C-5 to the site occupied by the CH2OHgroup without changing the absolute configuration at C-5, rotate the three ligands H, OH, and CH2OH on C-5 in 1 clockwise without moving the fourth ligand. (See Fischer projection)
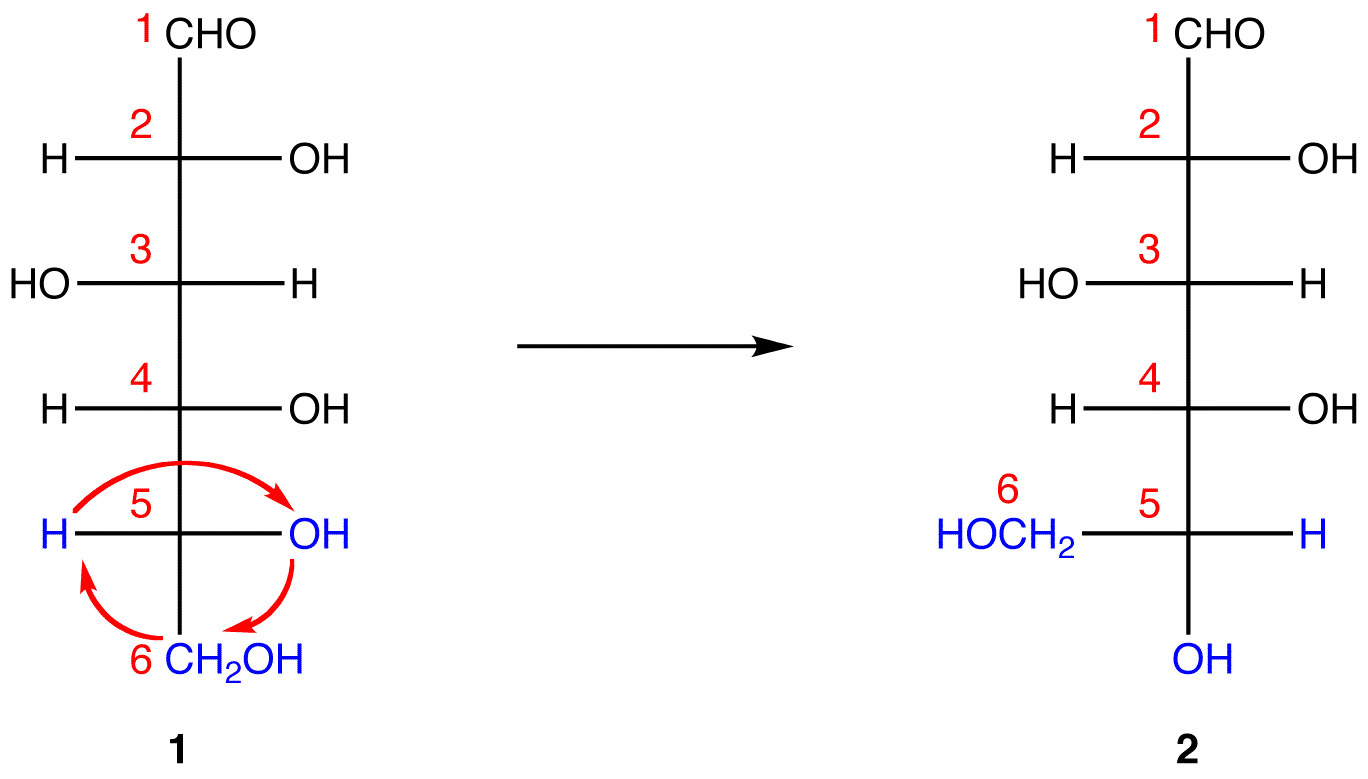
1 and 2 both represent D-glucose, but, in 2, unlike in 1, C-1 and the hydroxy group on C-5 are on the same side of the plane of the paper.
Step 4: Ignore that 2 is a Fischer projection and rotate it clockwise by 90º.
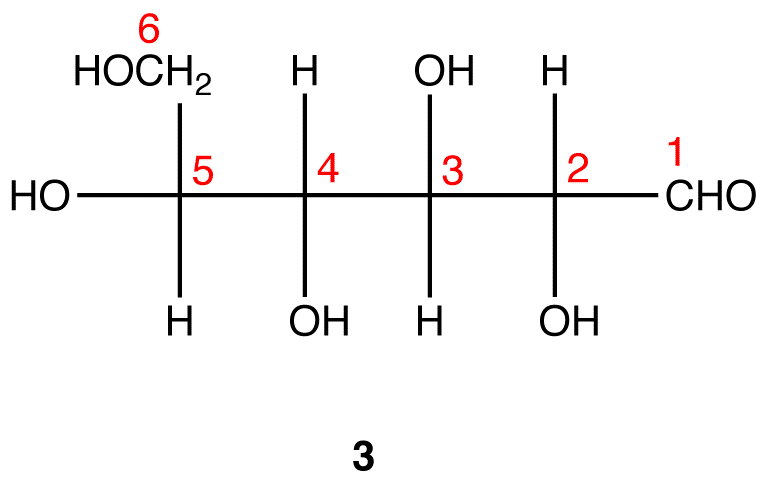
Step 5: Redraw the atom chain along the horizontal axis as follows.
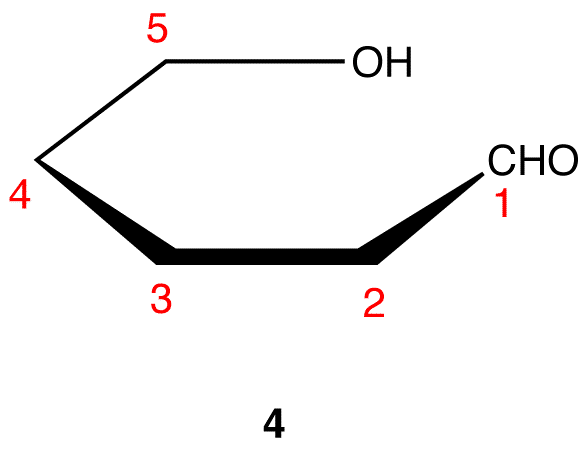
Step 6: Add the ligands on C-2 through C-5 in 4. The ligands pointing up in 3 are pointing up in 4; those pointing down in 3 are pointing down in 4.
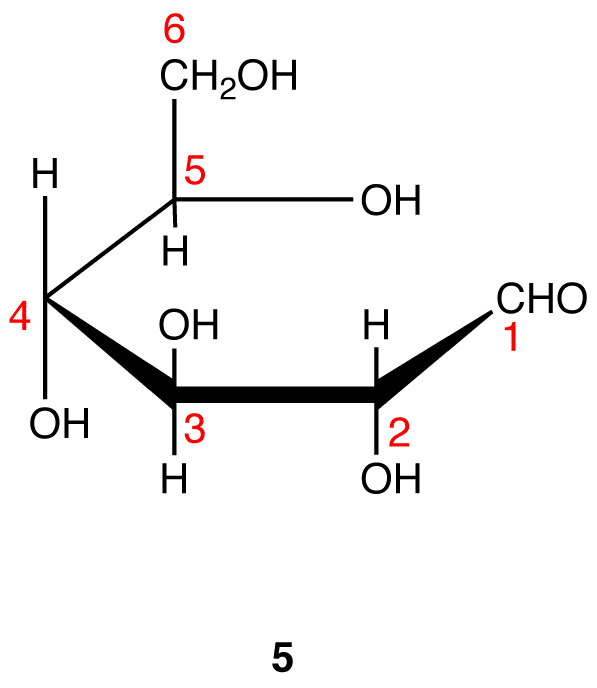
Step 7: Remove the hydrogen atom and the oxygen atom on C-1 and the hydrogen atom in the hydroxy group on C-5 in 5 and connect the two atoms by a single bond.
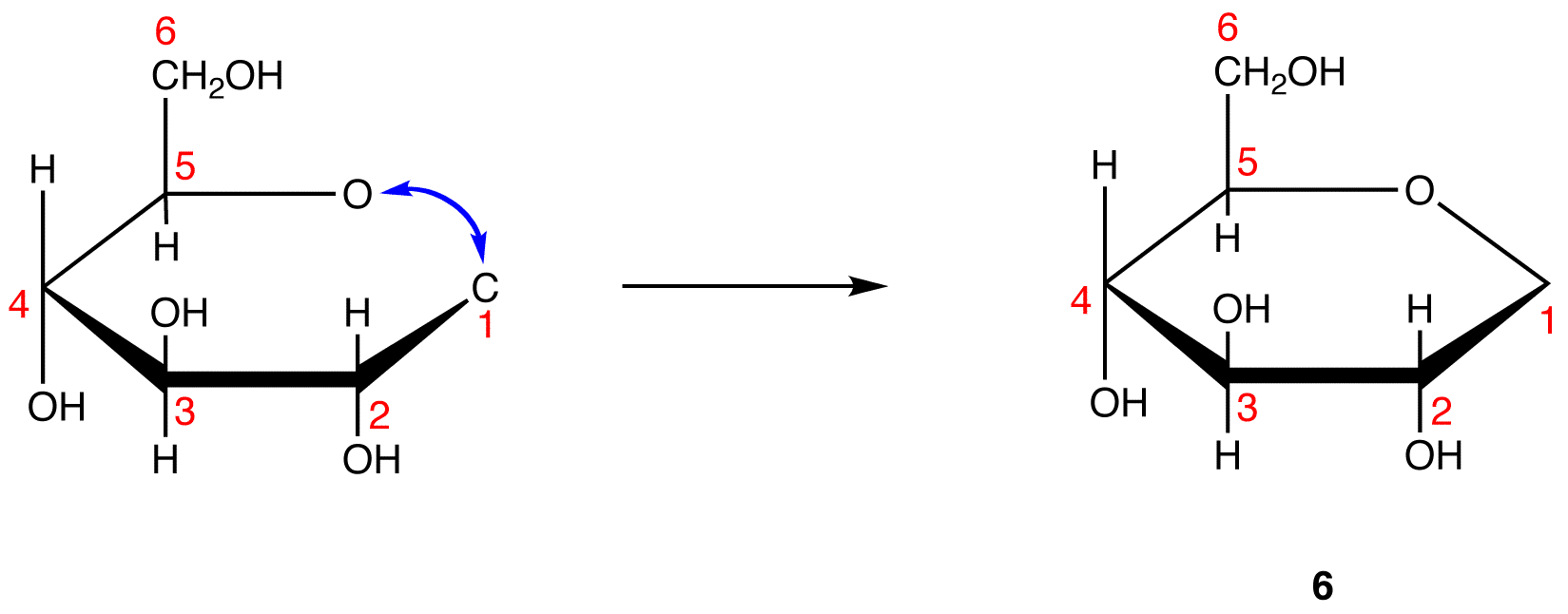
Step 8: Add the two remaining bonds to C-1 in 6.
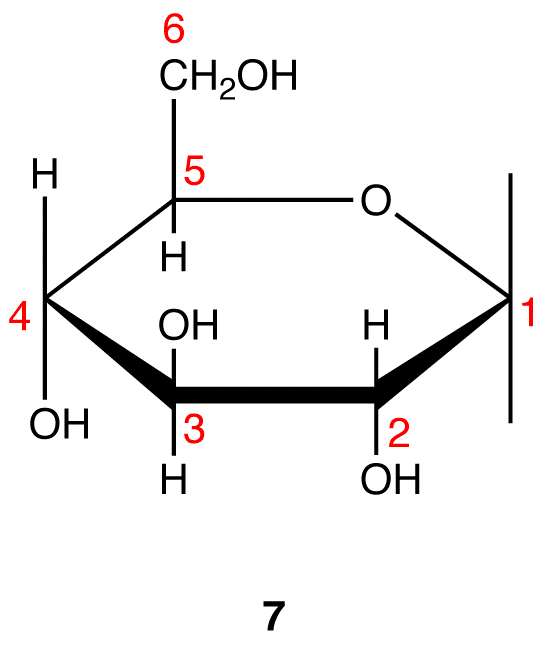
Step 9: Attach a hydrogen atom to the bond pointing up and a hydroxy group to the bond pointing down on C-1 in 7.
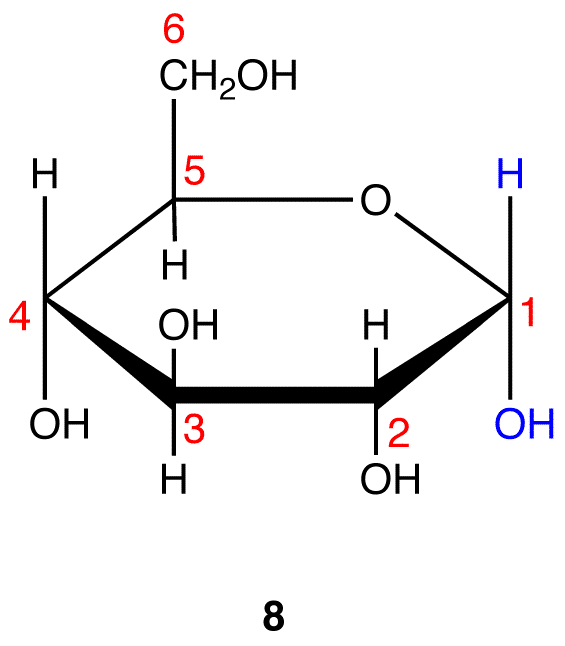
Step 10: Interchange the hydrogen atom and the hydroxy group on C-1 in 8.
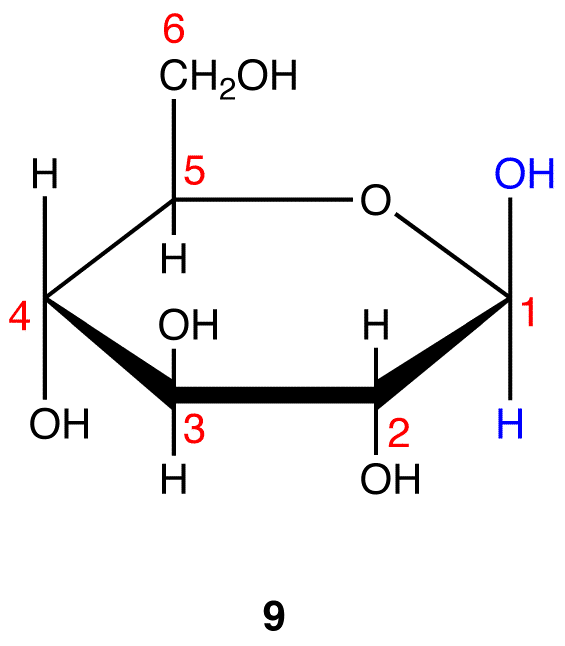
8 and 9 are the Haworth formulas of the pyranoses of D-glucose. If, in the acyclic form of a monosaccharide, the hydroxy group that reacts with the carbonyl carbon is not on a chiral carbon (eg: D-fructose→pyranoses), skip step 3.
LIPIDS
Fatty Acids
ntroduction to Fatty Acids
Introduction
The most common fatty acids are listed. Note that there are two groups of fatty acids–saturated and unsaturated. Recall that the term unsaturated refers to the presence of one or more double bonds between carbons as in alkenes. A saturated fatty acid has all bonding positions between carbons occupied by hydrogens. The melting points for the saturated fatty acids follow the boiling point principle observed previously. Melting point principle: as the molecular weight increases, the melting point increases. This observed in the series lauric (C12), palmitic (C16), stearic (C18). Room temperature is 25oC, Lauric acid which melts at 44o is still a solid, while arachidonic acid has long since melted at -50o, so it is a liquid at room temperature.
| Acid Name | Structure | Melting Point |
|---|---|---|
| SATURATED | ||
| Lauric | CH3(CH2)10COOH | +44 |
| Palmitic | CH3(CH2)14COOH | +63 |
| Stearic | CH3(CH2)16COOH | +70 |
| UNSATURATED | ||
| Oleic | CH3(CH2)7CH=CH(CH2)7COOH | +16 |
| Linoleic | CH3(CH2)4(CH=CHCH2)2(CH2)6COOH | -5 |
| Linolenic | CH3CH2(CH=CHCH2)3(CH2)6COOH | -11 |
| Arachidonic | CH3(CH2)4(CH=CHCH2)4(CH2)2COOH | -50 |
Melting Points of Saturated vs. Unsaturated Fatty Acids
Note that as a group, the unsaturated fatty acids have lower melting points than the saturated fatty acids. The reason for this phenomenon can be found by a careful consideration of molecular geometries. The tetrahedral bond angles on carbon results in a molecular geometry for saturated fatty acids that is relatively linear although with zigzags. See graphic on the left. This molecular structure allows many fatty acid molecules to be rather closely “stacked” together. As a result, close intermolecular interactions result in relatively high melting points.
On the other hand, the introduction of one or more double bonds in the hydrocarbon chain in unsaturated fatty acids results in one or more “bends” in the molecule. The geometry of the double bond is almost always a cis configuration in natural fatty acids. and these molecules do not “stack” very well. The intermolecular interactions are much weaker than saturated molecules. As a result, the melting points are much lower for unsaturated fatty acids.
| Fat or Oil | Saturated | Unsaturated | |||
|---|---|---|---|---|---|
| Palmitic | Stearic | Oleic | Linoleic | Other | |
| Animal Origin | |||||
| Butter | 29 | 9 | 27 | 4 | 31 |
| Lard | 30 | 18 | 41 | 6 | 5 |
| Beef | 32 | 25 | 38 | 3 | 2 |
| Vegetable Origin | |||||
| Corn oil | 10 | 4 | 34 | 48 | 4 |
| Soybean | 7 | 3 | 25 | 56 | 9 |
| Peanut | 7 | 5 | 60 | 21 | 7 |
| Olive | 6 | 4 | 83 | 7 | – |
Hydrogenation of Unsaturated Fats and Trans Fat
alkene plus hydrogen yields an alkane
Vegetable oils are commonly referred to as “polyunsaturated”. This simply means that there are several double bonds present. Vegetable oils may be converted from liquids to solids by the hydrogenation reaction. Margarines and shortenings are “hardened” in this way to make them solid or semi-solids.
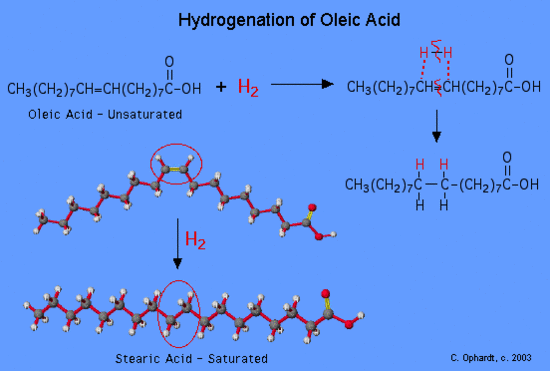
Figure 1: Hydrogenation of a oleic fatty acid
Vegetable oils which have been partially hydrogenated, are now partially saturated so the melting point increases to the point where a solid is present at room temperature. The degree of hydrogenation of unsaturated oils controls the final consistency of the product. What has happened to the healthfulness of the product which has been converted from unsaturated to saturated fats?
Trans Fat
A major health concern during the hydrogenation process is the production of trans fats. Trans fats are the result of a side reaction with the catalyst of the hydrogenation process. This is the result of an unsaturated fat which is normally found as a cis isomer converts to a trans isomer of the unsaturated fat. Isomers are molecules that have the same molecular formula but are bonded together differently. Focusing on the sp2 double bonded carbons, a cis isomer has the hydrogens on the same side. Due to the added energy from the hydrogenation process, the activation energy is reached to convert the cis isomers of the unsaturated fat to a trans isomer of the unsaturated fat. The effect is putting one of the hydrogens on the opposite side of one of the carbons. This results in a trans configuration of the double bonded carbons. The human body does not recognize trans fats.
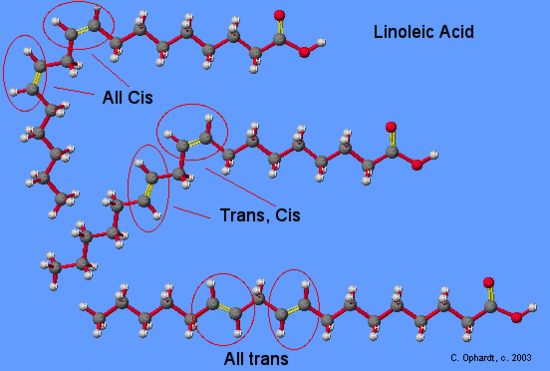
Although trans fatty acids are chemically “monounsaturated” or “polyunsaturated,” they are considered so different from the cis monounsaturated or polyunsaturated fatty acids that they can not be legally designated as unsaturated for purposes of labeling. Most of the trans fatty acids (although chemically still unsaturated) produced by the partial hydrogenation process are now classified in the same category as saturated fats.
The major negative is that trans fat tends to raise “bad” LDL- cholesterol and lower “good” HDL-cholesterol, although not as much as saturated fat. Trans fat are found in margarine, baked goods such as doughnuts and Danish pastry, deep-fried foods like fried chicken and French-fried potatoes, snack chips, imitation cheese, and confectionery fats.
Prostaglandins
Introduction
Prostaglandins are unsaturated carboxylic acids, consisting of of a 20 carbon skeleton that also contains a five member ring. They are biochemically synthesized from the fatty acid, arachidonic acid. See the graphic on the left. The unique shape of the arachidonic acid caused by a series of cis double bonds helps to put it into position to make the five member ring. See the prostaglandin in the next panel
Prostaglandin Structure
Prostaglandins are unsaturated carboxylic acids, consisting of of a 20 carbon skeleton that also contains a five member ring and are based upon the fatty acid, arachidonic acid. There are a variety of structures one, two, or three double bonds. On the five member ring there may also be double bonds, a ketone, or alcohol groups. A typical structure is on the left graphic.
Functions of Prostaglandins
There are a variety of physiological effects including:
- Activation of the inflammatory response, production of pain, and fever. When tissues are damaged, white blood cells flood to the site to try to minimize tissue destruction. Prostaglandins are produced as a result.
- Blood clots form when a blood vessel is damaged. A type of prostaglandin called thromboxane stimulates constriction and clotting of platelets. Conversely, PGI2, is produced to have the opposite effect on the walls of blood vessels where clots should not be forming.
- Certain prostaglandins are involved with the induction of labor and other reproductive processes. PGE2 causes uterine contractions and has been used to induce labor.
- Prostaglandins are involved in several other organs such as the gastrointestinal tract (inhibit acid synthesis and increase secretion of protective mucus), increase blood flow in kidneys, and leukotriens promote constriction of bronchi associated with asthma.
Effects of Aspirin and other Pain Killers
When you see that prostaglandins induce inflammation, pain, and fever, what comes to mind but aspirin. Aspirin blocks an enzyme called cyclooxygenase, COX-1 and COX-2, which is involved with the ring closure and addition of oxygen to arachidonic acid converting to prostaglandins. The acetyl group on aspirin is hydrolzed and then bonded to the alcohol group of serine as an ester. This has the effect of blocking the channel in the enzyme and arachidonic can not enter the active site of the enzyme. By inhibiting or blocking this enzyme, the synthesis of prostaglandins is blocked, which in turn relives some of the effects of pain and fever. Aspirin is also thought to inhibit the prostaglandin synthesis involved with unwanted blood clotting in coronary heart disease. At the same time an injury while taking aspirin may cause more extensive bleeding.
Glycerides
Triglycerides
Introduction
Since glycerol has three alcohol functional groups, three fatty acids must react to make three ester functional groups. The three fatty acids may or may not be identical. In fact, three different fatty acids may be present. The synthesis of a triglyceride is another application of the ester synthesis reaction. To write the structure of the triglyceride you must know the structure of glycerol and be given or look up the structure of the fatty acid in the table.
| Fat or Oil | Saturated | Unsaturated | |||
|---|---|---|---|---|---|
| Palmitic | Stearic | Oleic | Linoleic | Other | |
| Animal Origin | |||||
| Butter | 29 | 9 | 27 | 4 | 31 |
| Lard | 30 | 18 | 41 | 6 | 5 |
| Beef | 32 | 25 | 38 | 3 | 2 |
| Vegetable Origin | |||||
| Corn oil | 10 | 4 | 34 | 48 | 4 |
| Soybean | 7 | 3 | 25 | 56 | 9 |
| Peanut | 7 | 5 | 60 | 21 | 7 |
| Olive | 6 | 4 | 83 | 7 | – |

Synthesis of a Triglyceride
Since glycerol, (IUPAC name is 1,2,3-propantriol), has three alcohol functional groups, three fatty acids must react to make three ester functional groups. The three fatty acids may or may not be identical. In fact, three different fatty acids may be present. nThe synthesis of a triglyceride is another application of the ester synthesis reaction. To write the structure of the triglyceride you must know the structure of glycerol and be given or look up the structure of the fatty acid in the table – find lauric acid.
Glycerol
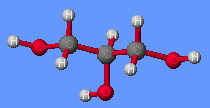 The simplified reaction reveals the process of breaking some bonds and forming the ester and the by product, water. Refer to the graphic on the left for the synthesis of trilauroylglycerol. First, the -OH (red) bond on the acid is broken and the -H (red) bond on the alcohol is also broken. Both join to make HOH, a water molecule. Secondly, the oxygen of the alcohol forms a bond (green) to the acid at the carbon with the double bond oxygen. This forms the ester functional group. This process is carried out three times to make three ester groups and three water molecules.
The simplified reaction reveals the process of breaking some bonds and forming the ester and the by product, water. Refer to the graphic on the left for the synthesis of trilauroylglycerol. First, the -OH (red) bond on the acid is broken and the -H (red) bond on the alcohol is also broken. Both join to make HOH, a water molecule. Secondly, the oxygen of the alcohol forms a bond (green) to the acid at the carbon with the double bond oxygen. This forms the ester functional group. This process is carried out three times to make three ester groups and three water molecules.
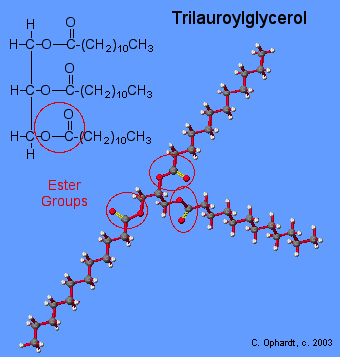
Structure of a Triglyceride
As you can see from the graphic on the left, the actual molecular model of the triglyceride does not look at all like the line drawing. The reason for this difference lies in the concepts of molecular geometry. Trilauroylglycerol. All of the above factors contribute to the apparent “T” shape of the molecule.
Problems
| Quiz: Which acid (short chain or fatty) would most likely be soluble in water? |
| … in hexane? |
1 Practice writing out a triglyceride of stearic acid. Again look up the formula of stearic acid and use the structure of glycerol.
2. Write down your answers. Then check the answers from the drop down menu.
| What is the molecular geometry of all three carbons in glycerol (look at model above)? |
| What is the molecular geometry of the carbon at the center of the ester group? | |
| What is the molecular geometry of the single bond oxygen? |
Phosphoglycerides or Phospholipids
Introduction
The third oxygen on glycerol is bonded to phosphoric acid through a phosphate ester bond (oxygen-phosphorus double bond oxygen). In addition, there is usually a complex amino alcohol also attached to the phosphate through a second phosphate ester bond. The complex amino alcohols include choline, ethanolamine, and the amino acid-serine. The properties of a phospholipid are characterized by the properties of the fatty acid chain and the phosphate/amino alcohol. The long hydrocarbon chains of the fatty acids are of course non-polar. The phosphate group has a negatively charged oxygen and a positively charged nitrogen to make this group ionic. In addition there are other oxygen of the ester groups, which make on whole end of the molecule strongly ionic and polar.
Phospholipids are major components in the lipid bilayers of cell membranes. There are two common phospholipids:
- Lecithin contains the amino alcohol, choline.
- Cephalins contain the amino alcohols serine or ethanolamine
Lecithin
Lecithin is probably the most common phospholipid. It is found in egg yolks, wheat germ, and soybeans. Lecithin is extracted from soy beans for use as an emulsifying agent in foods. Lecithin is an emulsifier because it has both polar and non-polar properties, which enable it to cause the mixing of other fats and oils with water components. See more discussion on this property in soaps. Lecithin is also a major component in the lipid bilayers of cell membranes.
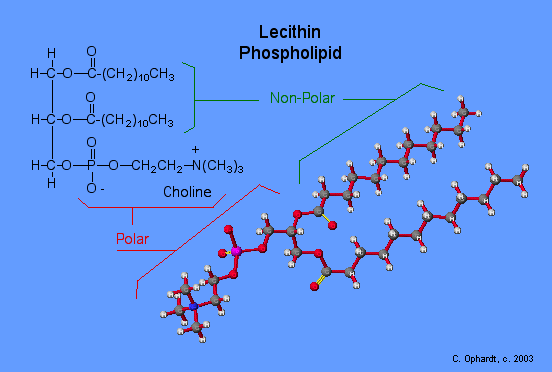
Lecithin contains the ammonium salt of choline joined to the phosphate by an ester linkage. The nitrogen has a positive charge, just as in the ammonium ion. In choline, the nitrogen has the positive charge and has four methyl groups attached.
Cephalins
Cephalins are phosphoglycerides that contain ehtanolamine or the amino acid serine attached to the phosphate group through phosphate ester bonds. A variety of fatty acids make up the rest of the molecule. Cephalins are found in most cell membranes, particularly in brain tissues. They also iimportant in the blood clotting process as they are found in blood platelets.
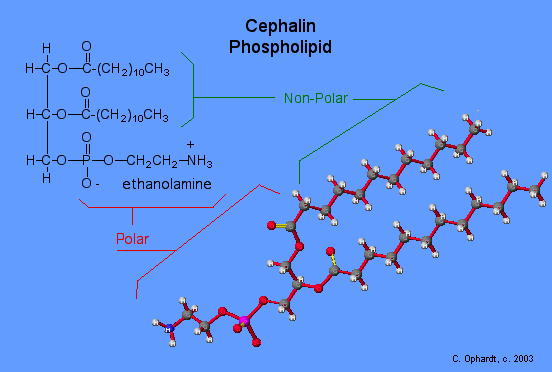
Note: The MEP coloration of the electrostatic potential does not show a strong red color for the phosphate-amino alcohol portion of the molecule as it should to show the strong polar property of that group.
Steroids
Introduction
Steroids include such well known compounds as cholesterol, sex hormones, birth control pills, cortisone, and anabolic steroids.
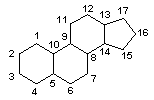
Cholesterol
The best known and most abundant steroid in the body is cholesterol. Cholesterol is formed in brain tissue, nerve tissue, and the blood stream. It is the major compound found in gallstones and bile salts. Cholesterol also contributes to the formation of deposits on the inner walls of blood vessels. These deposits harden and obstruct the flow of blood. This condition, known as atherosclerosis, results in various heart diseases, strokes, and high blood pressure.
Much research is currently underway to determine if a correlation exists between cholesterol levels in the blood and diet. Not only does cholesterol come from the diet, but cholesterol is synthesized in the body from carbohydrates and proteins as well as fat. Therefore, the elimination of cholesterol rich foods from the diet does not necessarily lower blood cholesterol levels. Some studies have found that if certain unsaturated fats and oils are substituted for saturated fats, the blood cholesterol level decreases. The research is incomplete on this problem.

Structures of Sex Hormones
Sex hormones are also steroids. The primary male hormone, testosterone, is responsible for the development of secondary sex characteristics. Two female sex hormones, progesterone and estrogen or estradiol control the ovulation cycle. Notice that the male and female hormones have only slight differences in structures, but yet have very different physiological effects.
Testosterone promotes the normal development of male genital organs ans is synthesized from cholesterol in the testes. It also promotes secondary male sexual characteristics such as deep voice, facial and body hair.
Estrogen, along with progesterone regulates changes occurring in the uterus and ovaries known as the menstrual cycle. For more details see Birth Control. Estrogen is synthesized from testosterone by making the first ring aromatic which results in mole double bonds, the loss of a methyl group and formation of an alcohol group.
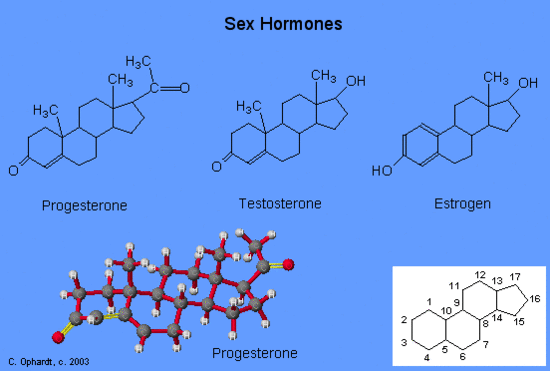
Adrenocorticoid Hormones
The adrenocorticoid hormones are products of the adrenal glands (“adrenal” means adjacent to the renal (kidney). The most important mineralocrticoid is aldosterone, which regulates the reabsorption of sodium and chloride ions in the kidney tubules and increases the loss of potassium ions. Aldosterone is secreted when blood sodium ion levels are too low to cause the kidney to retain sodium ions. If sodium levels are elevated, aldosterone is not secreted, so that some sodium will be lost in the urine. Aldosterone also controls swelling in the tissues.
Cortisol, the most important glucocortinoid, has the function of increasing glucose and glycogen concentrations in the body. These reactions are completed in the liver by taking fatty acids from lipid storage cells and amino acids from body proteins to make glucose and glycogen.
In addition, cortisol and its ketone derivative, cortisone, have the ability to inflammatory effects. Cortisone or similar synthetic derivatives such as prednisolone are used to treat inflammatory diseases, rheumatoid arthritis, and bronchial asthma. There are many side effects with the use of cortisone drugs, so there use must be monitored carefully.
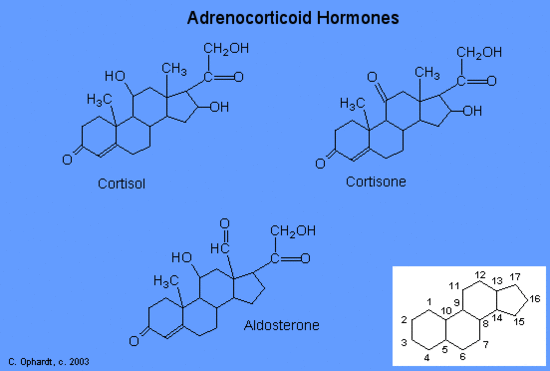
2.3 Biological Molecules
Learning Objectives
By the end of this section, you will be able to:
- Describe the ways in which carbon is critical to life
- Explain the impact of slight changes in amino acids on organisms
- Describe the four major types of biological molecules
- Understand the functions of the four major types of molecules
The large molecules necessary for life that are built from smaller organic molecules are called biological macromolecules. There are four major classes of biological macromolecules (carbohydrates, lipids, proteins, and nucleic acids), and each is an important component of the cell and performs a wide array of functions. Combined, these molecules make up the majority of a cell’s mass. Biological macromolecules are organic, meaning that they contain carbon. In addition, they may contain hydrogen, oxygen, nitrogen, phosphorus, sulfur, and additional minor elements.
Carbon
It is often said that life is “carbon-based.” This means that carbon atoms, bonded to other carbon atoms or other elements, form the fundamental components of many, if not most, of the molecules found uniquely in living things. Other elements play important roles in biological molecules, but carbon certainly qualifies as the “foundation” element for molecules in living things. It is the bonding properties of carbon atoms that are responsible for its important role.
Carbon Bonding
Carbon contains four electrons in its outer shell. Therefore, it can form four covalent bonds with other atoms or molecules. The simplest organic carbon molecule is methane (CH4), in which four hydrogen atoms bind to a carbon atom.
However, structures that are more complex are made using carbon. Any of the hydrogen atoms can be replaced with another carbon atom covalently bonded to the first carbon atom. In this way, long and branching chains of carbon compounds can be made (Figure 2.13 a). The carbon atoms may bond with atoms of other elements, such as nitrogen, oxygen, and phosphorus (Figure 2.13 b). The molecules may also form rings, which themselves can link with other rings (Figure 2.13 c). This diversity of molecular forms accounts for the diversity of functions of the biological macromolecules and is based to a large degree on the ability of carbon to form multiple bonds with itself and other atoms.
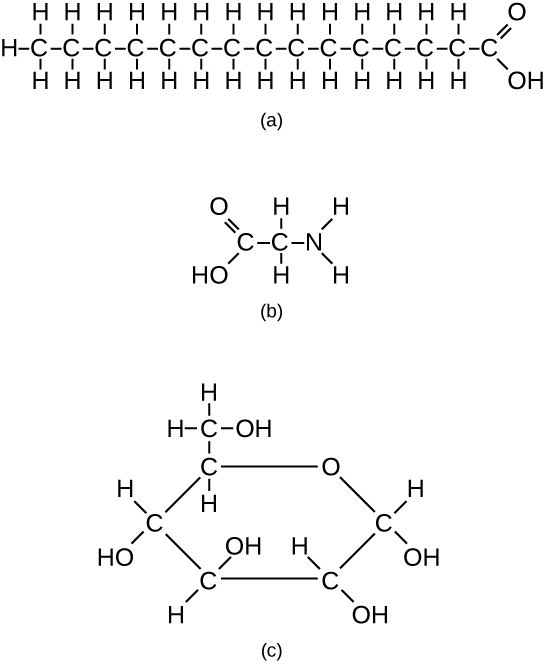
Carbohydrates
Carbohydrates are macromolecules with which most consumers are somewhat familiar. To lose weight, some individuals adhere to “low-carb” diets. Athletes, in contrast, often “carb-load” before important competitions to ensure that they have sufficient energy to compete at a high level. Carbohydrates are, in fact, an essential part of our diet; grains, fruits, and vegetables are all natural sources of carbohydrates. Carbohydrates provide energy to the body, particularly through glucose, a simple sugar. Carbohydrates also have other important functions in humans, animals, and plants.
Carbohydrates can be represented by the formula (CH2O)n, where n is the number of carbon atoms in the molecule. In other words, the ratio of carbon to hydrogen to oxygen is 1:2:1 in carbohydrate molecules. Carbohydrates are classified into three subtypes: monosaccharides, disaccharides, and polysaccharides.
Monosaccharides (mono- = “one”; sacchar- = “sweet”) are simple sugars, the most common of which is glucose. In monosaccharides, the number of carbon atoms usually ranges from three to six. Most monosaccharide names end with the suffix -ose. Depending on the number of carbon atoms in the sugar, they may be known as trioses (three carbon atoms), pentoses (five carbon atoms), and hexoses (six carbon atoms).
Monosaccharides may exist as a linear chain or as ring-shaped molecules; in aqueous solutions, they are usually found in the ring form.
The chemical formula for glucose is C6H12O6. In most living species, glucose is an important source of energy. During cellular respiration, energy is released from glucose, and that energy is used to help make adenosine triphosphate (ATP). Plants synthesize glucose using carbon dioxide and water by the process of photosynthesis, and the glucose, in turn, is used for the energy requirements of the plant. The excess synthesized glucose is often stored as starch that is broken down by other organisms that feed on plants.
Galactose (part of lactose, or milk sugar) and fructose (found in fruit) are other common monosaccharides. Although glucose, galactose, and fructose all have the same chemical formula (C6H12O6), they differ structurally and chemically (and are known as isomers) because of differing arrangements of atoms in the carbon chain.
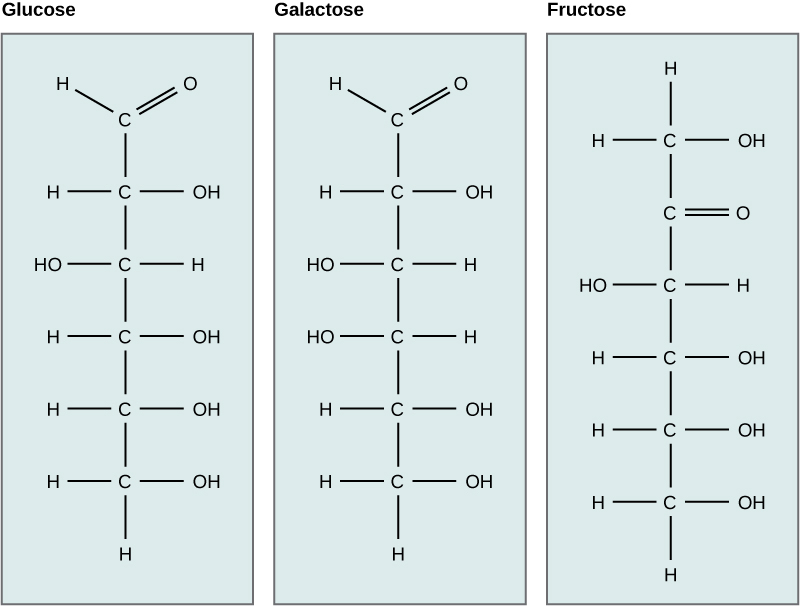
Disaccharides (di- = “two”) form when two monosaccharides undergo a dehydration reaction (a reaction in which the removal of a water molecule occurs). During this process, the hydroxyl group (–OH) of one monosaccharide combines with a hydrogen atom of another monosaccharide, releasing a molecule of water (H2O) and forming a covalent bond between atoms in the two sugar molecules.
Common disaccharides include lactose, maltose, and sucrose. Lactose is a disaccharide consisting of the monomers glucose and galactose. It is found naturally in milk. Maltose, or malt sugar, is a disaccharide formed from a dehydration reaction between two glucose molecules. The most common disaccharide is sucrose, or table sugar, which is composed of the monomers glucose and fructose.
A long chain of monosaccharides linked by covalent bonds is known as a polysaccharide (poly- = “many”). The chain may be branched or unbranched, and it may contain different types of monosaccharides. Polysaccharides may be very large molecules. Starch, glycogen, cellulose, and chitin are examples of polysaccharides.
Starch is the stored form of sugars in plants and is made up of amylose and amylopectin (both polymers of glucose). Plants are able to synthesize glucose, and the excess glucose is stored as starch in different plant parts, including roots and seeds. The starch that is consumed by animals is broken down into smaller molecules, such as glucose. The cells can then absorb the glucose.
Glycogen is the storage form of glucose in humans and other vertebrates, and is made up of monomers of glucose. Glycogen is the animal equivalent of starch and is a highly branched molecule usually stored in liver and muscle cells. Whenever glucose levels decrease, glycogen is broken down to release glucose.
Cellulose is one of the most abundant natural biopolymers. The cell walls of plants are mostly made of cellulose, which provides structural support to the cell. Wood and paper are mostly cellulosic in nature. Cellulose is made up of glucose monomers that are linked by bonds between particular carbon atoms in the glucose molecule.
Every other glucose monomer in cellulose is flipped over and packed tightly as extended long chains. This gives cellulose its rigidity and high tensile strength—which is so important to plant cells. Cellulose passing through our digestive system is called dietary fiber. While the glucose-glucose bonds in cellulose cannot be broken down by human digestive enzymes, herbivores such as cows, buffalos, and horses are able to digest grass that is rich in cellulose and use it as a food source. In these animals, certain species of bacteria reside in the rumen (part of the digestive system of herbivores) and secrete the enzyme cellulase. The appendix also contains bacteria that break down cellulose, giving it an important role in the digestive systems of ruminants. Cellulases can break down cellulose into glucose monomers that can be used as an energy source by the animal.
Carbohydrates serve other functions in different animals. Arthropods, such as insects, spiders, and crabs, have an outer skeleton, called the exoskeleton, which protects their internal body parts. This exoskeleton is made of the biological macromolecule chitin, which is a nitrogenous carbohydrate. It is made of repeating units of a modified sugar containing nitrogen.
Thus, through differences in molecular structure, carbohydrates are able to serve the very different functions of energy storage (starch and glycogen) and structural support and protection (cellulose and chitin).
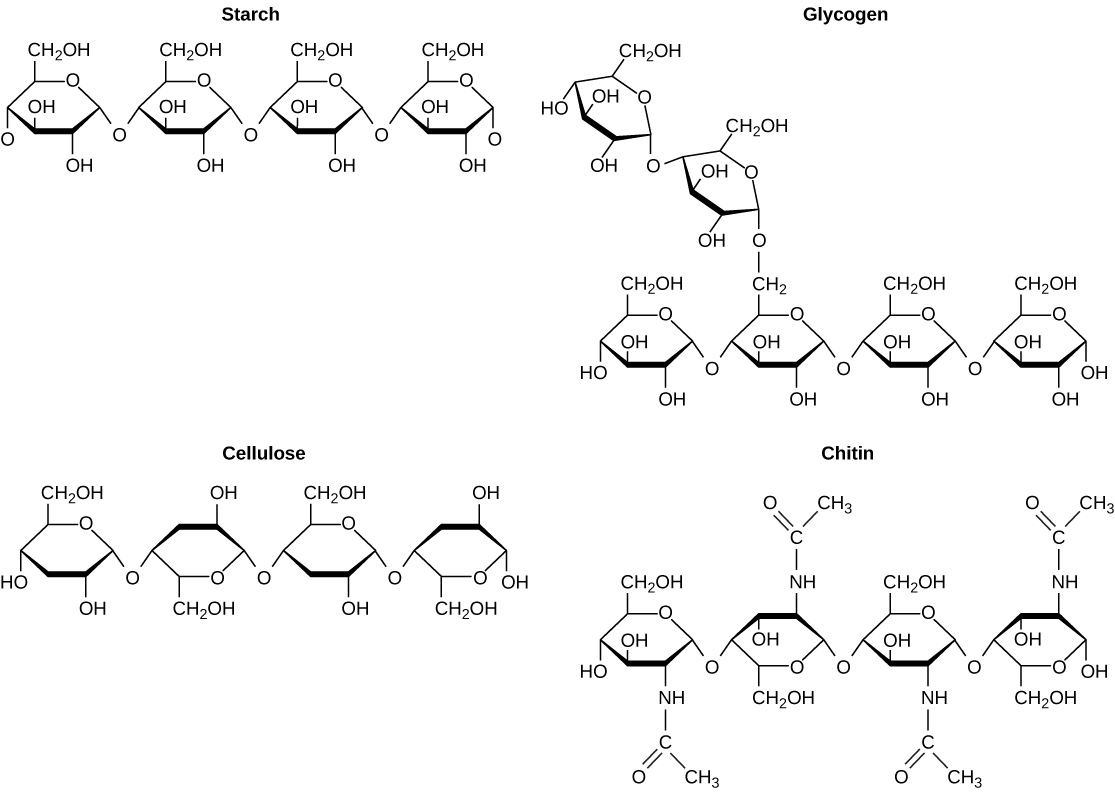
Registered Dietitian: Obesity is a worldwide health concern, and many diseases, such as diabetes and heart disease, are becoming more prevalent because of obesity. This is one of the reasons why registered dietitians are increasingly sought after for advice. Registered dietitians help plan food and nutrition programs for individuals in various settings. They often work with patients in health-care facilities, designing nutrition plans to prevent and treat diseases. For example, dietitians may teach a patient with diabetes how to manage blood-sugar levels by eating the correct types and amounts of carbohydrates. Dietitians may also work in nursing homes, schools, and private practices.
To become a registered dietitian, one needs to earn at least a bachelor’s degree in dietetics, nutrition, food technology, or a related field. In addition, registered dietitians must complete a supervised internship program and pass a national exam. Those who pursue careers in dietetics take courses in nutrition, chemistry, biochemistry, biology, microbiology, and human physiology. Dietitians must become experts in the chemistry and functions of food (proteins, carbohydrates, and fats).
Lipids
Lipids include a diverse group of compounds that are united by a common feature. Lipids are hydrophobic (“water-fearing”), or insoluble in water, because they are nonpolar molecules. This is because they are hydrocarbons that include only nonpolar carbon-carbon or carbon-hydrogen bonds. Lipids perform many different functions in a cell. Cells store energy for long-term use in the form of lipids called fats. Lipids also provide insulation from the environment for plants and animals. For example, they help keep aquatic birds and mammals dry because of their water-repelling nature. Lipids are also the building blocks of many hormones and are an important constituent of the plasma membrane. Lipids include fats, oils, waxes, phospholipids, and steroids.

A fat molecule, such as a triglyceride, consists of two main components—glycerol and fatty acids. Glycerol is an organic compound with three carbon atoms, five hydrogen atoms, and three hydroxyl (–OH) groups. Fatty acids have a long chain of hydrocarbons to which an acidic carboxyl group is attached, hence the name “fatty acid.” The number of carbons in the fatty acid may range from 4 to 36; most common are those containing 12–18 carbons. In a fat molecule, a fatty acid is attached to each of the three oxygen atoms in the –OH groups of the glycerol molecule with a covalent bond.
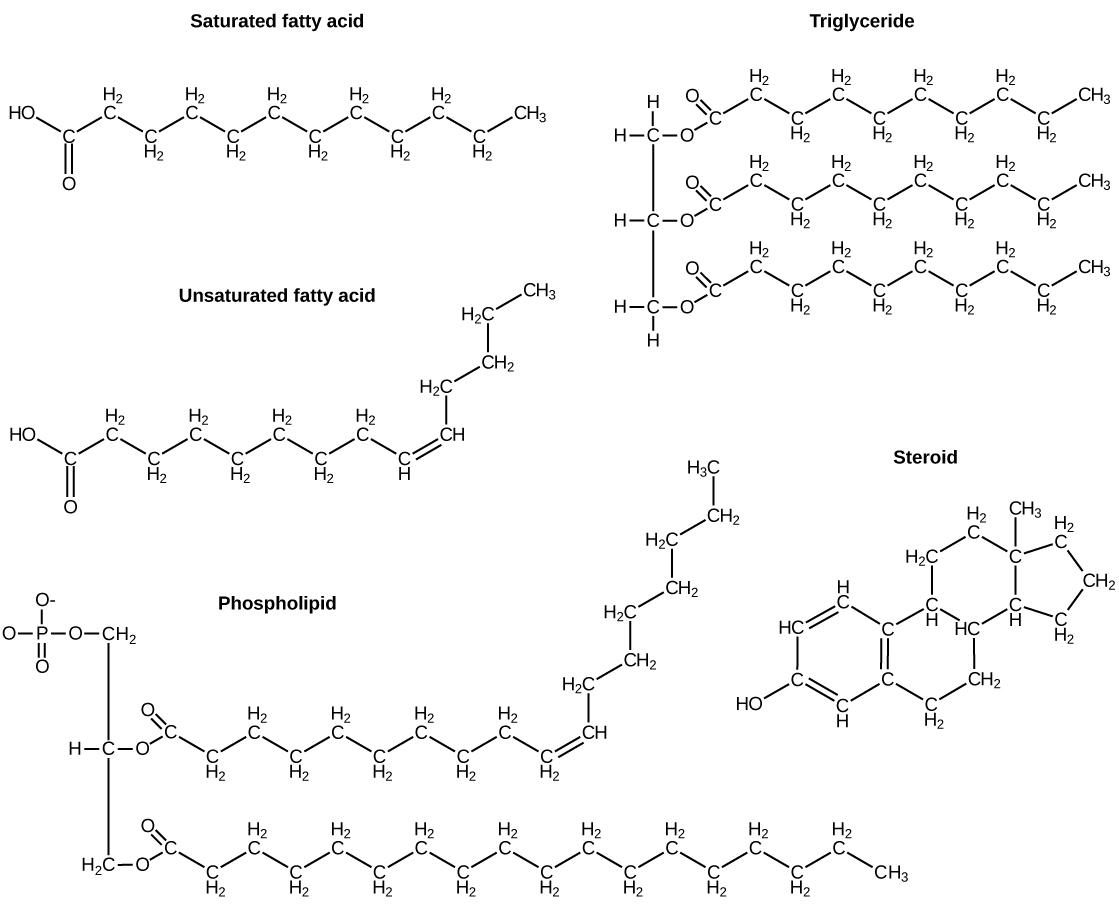
During this covalent bond formation, three water molecules are released. The three fatty acids in the fat may be similar or dissimilar. These fats are also called triglycerides because they have three fatty acids. Some fatty acids have common names that specify their origin. For example, palmitic acid, a saturated fatty acid, is derived from the palm tree. Arachidic acid is derived from Arachis hypogaea, the scientific name for peanuts.
Fatty acids may be saturated or unsaturated. In a fatty acid chain, if there are only single bonds between neighboring carbons in the hydrocarbon chain, the fatty acid is saturated. Saturated fatty acids are saturated with hydrogen; in other words, the number of hydrogen atoms attached to the carbon skeleton is maximized.
When the hydrocarbon chain contains a double bond, the fatty acid is an unsaturated fatty acid.
Most unsaturated fats are liquid at room temperature and are called oils. If there is one double bond in the molecule, then it is known as a monounsaturated fat (e.g., olive oil), and if there is more than one double bond, then it is known as a polyunsaturated fat (e.g., canola oil).
Saturated fats tend to get packed tightly and are solid at room temperature. Animal fats with stearic acid and palmitic acid contained in meat, and the fat with butyric acid contained in butter, are examples of saturated fats. Mammals store fats in specialized cells called adipocytes, where globules of fat occupy most of the cell. In plants, fat or oil is stored in seeds and is used as a source of energy during embryonic development.
Unsaturated fats or oils are usually of plant origin and contain unsaturated fatty acids. The double bond causes a bend or a “kink” that prevents the fatty acids from packing tightly, keeping them liquid at room temperature. Olive oil, corn oil, canola oil, and cod liver oil are examples of unsaturated fats. Unsaturated fats help to improve blood cholesterol levels, whereas saturated fats contribute to plaque formation in the arteries, which increases the risk of a heart attack.
In the food industry, oils are artificially hydrogenated to make them semi-solid, leading to less spoilage and increased shelf life. Simply speaking, hydrogen gas is bubbled through oils to solidify them. During this hydrogenation process, double bonds of the cis-conformation in the hydrocarbon chain may be converted to double bonds in the trans-conformation. This forms a trans-fat from a cis-fat. The orientation of the double bonds affects the chemical properties of the fat.
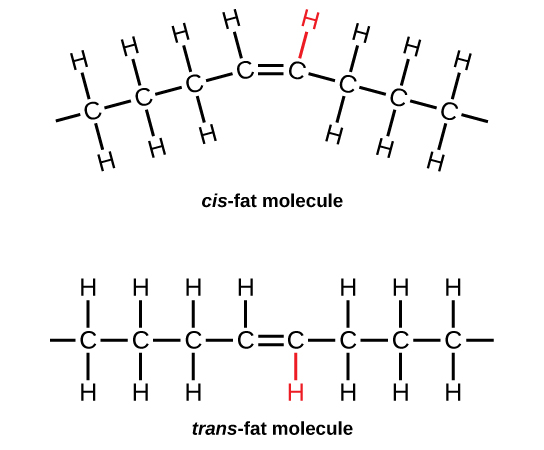
Margarine, some types of peanut butter, and shortening are examples of artificially hydrogenated trans-fats. Recent studies have shown that an increase in trans-fats in the human diet may lead to an increase in levels of low-density lipoprotein (LDL), or “bad” cholesterol, which, in turn, may lead to plaque deposition in the arteries, resulting in heart disease. Many fast food restaurants have recently eliminated the use of trans-fats, and U.S. food labels are now required to list their trans-fat content.
Essential fatty acids are fatty acids that are required but not synthesized by the human body. Consequently, they must be supplemented through the diet. Omega-3 fatty acids fall into this category and are one of only two known essential fatty acids for humans (the other being omega-6 fatty acids). They are a type of polyunsaturated fat and are called omega-3 fatty acids because the third carbon from the end of the fatty acid participates in a double bond.
Salmon, trout, and tuna are good sources of omega-3 fatty acids. Omega-3 fatty acids are important in brain function and normal growth and development. They may also prevent heart disease and reduce the risk of cancer.
Like carbohydrates, fats have received a lot of bad publicity. It is true that eating an excess of fried foods and other “fatty” foods leads to weight gain. However, fats do have important functions. Fats serve as long-term energy storage. They also provide insulation for the body. Therefore, “healthy” unsaturated fats in moderate amounts should be consumed on a regular basis.
Phospholipids are the major constituent of the plasma membrane. Like fats, they are composed of fatty acid chains attached to a glycerol or similar backbone. Instead of three fatty acids attached, however, there are two fatty acids and the third carbon of the glycerol backbone is bound to a phosphate group. The phosphate group is modified by the addition of an alcohol.
A phospholipid has both hydrophobic and hydrophilic regions. The fatty acid chains are hydrophobic and exclude themselves from water, whereas the phosphate is hydrophilic and interacts with water.
Cells are surrounded by a membrane, which has a bilayer of phospholipids. The fatty acids of phospholipids face inside, away from water, whereas the phosphate group can face either the outside environment or the inside of the cell, which are both aqueous.
Steroids and Waxes
Unlike the phospholipids and fats discussed earlier, steroids have a ring structure. Although they do not resemble other lipids, they are grouped with them because they are also hydrophobic. All steroids have four, linked carbon rings and several of them, like cholesterol, have a short tail.
Cholesterol is a steroid. Cholesterol is mainly synthesized in the liver and is the precursor of many steroid hormones, such as testosterone and estradiol. It is also the precursor of vitamins E and K. Cholesterol is the precursor of bile salts, which help in the breakdown of fats and their subsequent absorption by cells. Although cholesterol is often spoken of in negative terms, it is necessary for the proper functioning of the body. It is a key component of the plasma membranes of animal cells.
Waxes are made up of a hydrocarbon chain with an alcohol (–OH) group and a fatty acid. Examples of animal waxes include beeswax and lanolin. Plants also have waxes, such as the coating on their leaves, that helps prevent them from drying out.
Concept in Action

For an additional perspective on lipids, explore “Biomolecules: The Lipids” through this interactive animation.
Proteins
Proteins are one of the most abundant organic molecules in living systems and have the most diverse range of functions of all macromolecules. Proteins may be structural, regulatory, contractile, or protective; they may serve in transport, storage, or membranes; or they may be toxins or enzymes. Each cell in a living system may contain thousands of different proteins, each with a unique function. Their structures, like their functions, vary greatly. They are all, however, polymers of amino acids, arranged in a linear sequence.
The functions of proteins are very diverse because there are 20 different chemically distinct amino acids that form long chains, and the amino acids can be in any order. For example, proteins can function as enzymes or hormones. Enzymes, which are produced by living cells, are catalysts in biochemical reactions (like digestion) and are usually proteins. Each enzyme is specific for the substrate (a reactant that binds to an enzyme) upon which it acts. Enzymes can function to break molecular bonds, to rearrange bonds, or to form new bonds. An example of an enzyme is salivary amylase, which breaks down amylose, a component of starch.
Hormones are chemical signaling molecules, usually proteins or steroids, secreted by an endocrine gland or group of endocrine cells that act to control or regulate specific physiological processes, including growth, development, metabolism, and reproduction. For example, insulin is a protein hormone that maintains blood glucose levels.
Proteins have different shapes and molecular weights; some proteins are globular in shape whereas others are fibrous in nature. For example, hemoglobin is a globular protein, but collagen, found in our skin, is a fibrous protein. Protein shape is critical to its function. Changes in temperature, pH, and exposure to chemicals may lead to permanent changes in the shape of the protein, leading to a loss of function or denaturation (to be discussed in more detail later). All proteins are made up of different arrangements of the same 20 kinds of amino acids.
Amino acids are the monomers that make up proteins. Each amino acid has the same fundamental structure, which consists of a central carbon atom bonded to an amino group (–NH2), a carboxyl group (–COOH), and a hydrogen atom. Every amino acid also has another variable atom or group of atoms bonded to the central carbon atom known as the R group. The R group is the only difference in structure between the 20 amino acids; otherwise, the amino acids are identical.
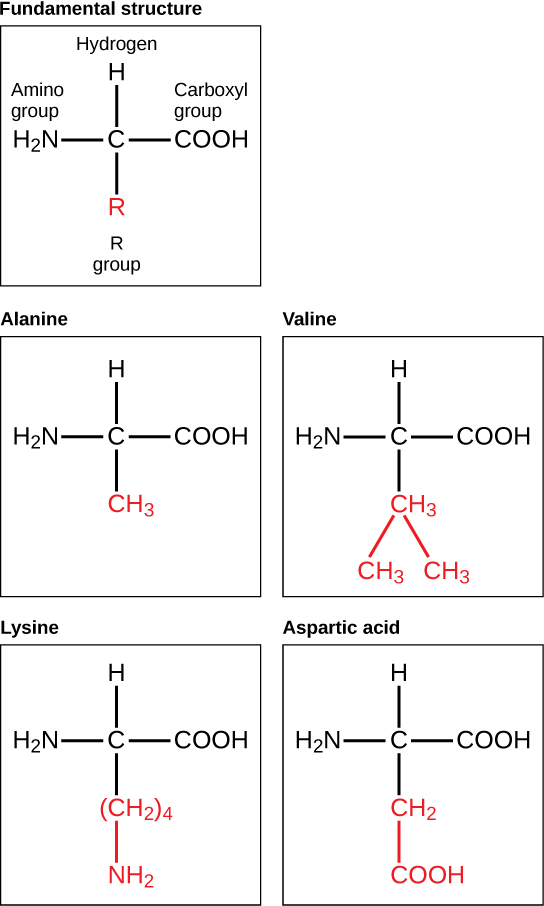
The chemical nature of the R group determines the chemical nature of the amino acid within its protein (that is, whether it is acidic, basic, polar, or nonpolar).
The sequence and number of amino acids ultimately determine a protein’s shape, size, and function. Each amino acid is attached to another amino acid by a covalent bond, known as a peptide bond, which is formed by a dehydration reaction. The carboxyl group of one amino acid and the amino group of a second amino acid combine, releasing a water molecule. The resulting bond is the peptide bond.
The products formed by such a linkage are called polypeptides. While the terms polypeptide and protein are sometimes used interchangeably, a polypeptide is technically a polymer of amino acids, whereas the term protein is used for a polypeptide or polypeptides that have combined together, have a distinct shape, and have a unique function.
Evolution in Action
The Evolutionary Significance of Cytochrome cCytochrome c is an important component of the molecular machinery that harvests energy from glucose. Because this protein’s role in producing cellular energy is crucial, it has changed very little over millions of years. Protein sequencing has shown that there is a considerable amount of sequence similarity among cytochrome c molecules of different species; evolutionary relationships can be assessed by measuring the similarities or differences among various species’ protein sequences.
For example, scientists have determined that human cytochrome c contains 104 amino acids. For each cytochrome c molecule that has been sequenced to date from different organisms, 37 of these amino acids appear in the same position in each cytochrome c. This indicates that all of these organisms are descended from a common ancestor. On comparing the human and chimpanzee protein sequences, no sequence difference was found. When human and rhesus monkey sequences were compared, a single difference was found in one amino acid. In contrast, human-to-yeast comparisons show a difference in 44 amino acids, suggesting that humans and chimpanzees have a more recent common ancestor than humans and the rhesus monkey, or humans and yeast.
Protein Structure
As discussed earlier, the shape of a protein is critical to its function. To understand how the protein gets its final shape or conformation, we need to understand the four levels of protein structure: primary, secondary, tertiary, and quaternary.
The unique sequence and number of amino acids in a polypeptide chain is its primary structure. The unique sequence for every protein is ultimately determined by the gene that encodes the protein. Any change in the gene sequence may lead to a different amino acid being added to the polypeptide chain, causing a change in protein structure and function. In sickle cell anemia, the hemoglobin β chain has a single amino acid substitution, causing a change in both the structure and function of the protein. What is most remarkable to consider is that a hemoglobin molecule is made up of two alpha chains and two beta chains that each consist of about 150 amino acids. The molecule, therefore, has about 600 amino acids. The structural difference between a normal hemoglobin molecule and a sickle cell molecule—that dramatically decreases life expectancy in the affected individuals—is a single amino acid of the 600.
Because of this change of one amino acid in the chain, the normally biconcave, or disc-shaped, red blood cells assume a crescent or “sickle” shape, which clogs arteries. This can lead to a myriad of serious health problems, such as breathlessness, dizziness, headaches, and abdominal pain for those who have this disease.
Folding patterns resulting from interactions between the non-R group portions of amino acids give rise to the secondary structure of the protein. The most common are the alpha (α)-helix and beta (β)-pleated sheet structures. Both structures are held in shape by hydrogen bonds. In the alpha helix, the bonds form between every fourth amino acid and cause a twist in the amino acid chain.
In the β-pleated sheet, the “pleats” are formed by hydrogen bonding between atoms on the backbone of the polypeptide chain. The R groups are attached to the carbons, and extend above and below the folds of the pleat. The pleated segments align parallel to each other, and hydrogen bonds form between the same pairs of atoms on each of the aligned amino acids. The α-helix and β-pleated sheet structures are found in many globular and fibrous proteins.
The unique three-dimensional structure of a polypeptide is known as its tertiary structure. This structure is caused by chemical interactions between various amino acids and regions of the polypeptide. Primarily, the interactions among R groups create the complex three-dimensional tertiary structure of a protein. There may be ionic bonds formed between R groups on different amino acids, or hydrogen bonding beyond that involved in the secondary structure. When protein folding takes place, the hydrophobic R groups of nonpolar amino acids lay in the interior of the protein, whereas the hydrophilic R groups lay on the outside. The former types of interactions are also known as hydrophobic interactions.
In nature, some proteins are formed from several polypeptides, also known as subunits, and the interaction of these subunits forms the quaternary structure. Weak interactions between the subunits help to stabilize the overall structure. For example, hemoglobin is a combination of four polypeptide subunits.

Each protein has its own unique sequence and shape held together by chemical interactions. If the protein is subject to changes in temperature, pH, or exposure to chemicals, the protein structure may change, losing its shape in what is known as denaturation as discussed earlier. Denaturation is often reversible because the primary structure is preserved if the denaturing agent is removed, allowing the protein to resume its function. Sometimes denaturation is irreversible, leading to a loss of function. One example of protein denaturation can be seen when an egg is fried or boiled. The albumin protein in the liquid egg white is denatured when placed in a hot pan, changing from a clear substance to an opaque white substance. Not all proteins are denatured at high temperatures; for instance, bacteria that survive in hot springs have proteins that are adapted to function at those temperatures.
Concept in Action

For an additional perspective on proteins, explore “Biomolecules: The Proteins” through this interactive animation.
Nucleic Acids
Nucleic acids are key macromolecules in the continuity of life. They carry the genetic blueprint of a cell and carry instructions for the functioning of the cell.
The two main types of nucleic acids are deoxyribonucleic acid (DNA) and ribonucleic acid (RNA). DNA is the genetic material found in all living organisms, ranging from single-celled bacteria to multicellular mammals.
The other type of nucleic acid, RNA, is mostly involved in protein synthesis. The DNA molecules never leave the nucleus, but instead use an RNA intermediary to communicate with the rest of the cell. Other types of RNA are also involved in protein synthesis and its regulation.
DNA and RNA are made up of monomers known as nucleotides. The nucleotides combine with each other to form a polynucleotide, DNA or RNA. Each nucleotide is made up of three components: a nitrogenous base, a pentose (five-carbon) sugar, and a phosphate group . Each nitrogenous base in a nucleotide is attached to a sugar molecule, which is attached to a phosphate group.
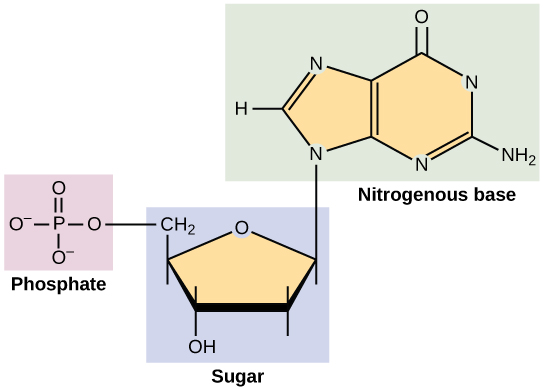
DNA Double-Helical Structure
DNA has a double-helical structure. It is composed of two strands, or polymers, of nucleotides. The strands are formed with bonds between phosphate and sugar groups of adjacent nucleotides. The strands are bonded to each other at their bases with hydrogen bonds, and the strands coil about each other along their length, hence the “double helix” description, which means a double spiral.

{kind=link}
The alternating sugar and phosphate groups lie on the outside of each strand, forming the backbone of the DNA. The nitrogenous bases are stacked in the interior, like the steps of a staircase, and these bases pair; the pairs are bound to each other by hydrogen bonds. The bases pair in such a way that the distance between the backbones of the two strands is the same all along the molecule. The rule is that nucleotide A pairs with nucleotide T, and G with C, see section 9.1 for more details.
Section Summary
Living things are carbon-based because carbon plays such a prominent role in the chemistry of living things. The four covalent bonding positions of the carbon atom can give rise to a wide diversity of compounds with many functions, accounting for the importance of carbon in living things. Carbohydrates are a group of macromolecules that are a vital energy source for the cell, provide structural support to many organisms, and can be found on the surface of the cell as receptors or for cell recognition. Carbohydrates are classified as monosaccharides, disaccharides, and polysaccharides, depending on the number of monomers in the molecule.
Lipids are a class of macromolecules that are nonpolar and hydrophobic in nature. Major types include fats and oils, waxes, phospholipids, and steroids. Fats and oils are a stored form of energy and can include triglycerides. Fats and oils are usually made up of fatty acids and glycerol.
Proteins are a class of macromolecules that can perform a diverse range of functions for the cell. They help in metabolism by providing structural support and by acting as enzymes, carriers or as hormones. The building blocks of proteins are amino acids. Proteins are organized at four levels: primary, secondary, tertiary, and quaternary. Protein shape and function are intricately linked; any change in shape caused by changes in temperature, pH, or chemical exposure may lead to protein denaturation and a loss of function.
Nucleic acids are molecules made up of repeating units of nucleotides that direct cellular activities such as cell division and protein synthesis. Each nucleotide is made up of a pentose sugar, a nitrogenous base, and a phosphate group. There are two types of nucleic acids: DNA and RNA.
Exercises
- An example of a monosaccharide is ________.
- fructose
- glucose
- galactose
- all of the above
- Cellulose and starch are examples of ________.
- monosaccharides
- disaccharides
- lipids
- polysaccharides
- Phospholipids are important components of __________.
- the plasma membrane of cells
- the ring structure of steroids
- the waxy covering on leaves
- the double bond in hydrocarbon chains
- The monomers that make up proteins are called _________.
- nucleotides
- disaccharides
- amino acids&nbs
- chaperones
- Explain at least three functions that lipids serve in plants and/or animals.
-
Explain what happens if even one amino acid is substituted for another in a polypeptide chain. Provide a specific example.
Answers
- D
- D
- A
- C
- Fat serves as a valuable way for animals to store energy. It can also provide insulation. Phospholipids and steroids are important components of cell membranes.
- A change in gene sequence can lead to a different amino acid being added to a polypeptide chain instead of the normal one. This causes a change in protein structure and function. For example, in sickle cell anemia, the hemoglobin β chain has a single amino acid substitution. Because of this change, the disc-shaped red blood cells assume a crescent shape, which can result in serious health problems.
Glossary
amino acid: a monomer of a protein
carbohydrate: a biological macromolecule in which the ratio of carbon to hydrogen to oxygen is 1:2:1; carbohydrates serve as energy sources and structural support in cells
cellulose: a polysaccharide that makes up the cell walls of plants and provides structural support to the cell
chitin: a type of carbohydrate that forms the outer skeleton of arthropods, such as insects and crustaceans, and the cell walls of fungi
denaturation: the loss of shape in a protein as a result of changes in temperature, pH, or exposure to chemicals
deoxyribonucleic acid (DNA): a double-stranded polymer of nucleotides that carries the hereditary information of the cell
disaccharide: two sugar monomers that are linked together by a peptide bond
enzyme: a catalyst in a biochemical reaction that is usually a complex or conjugated protein
fat: a lipid molecule composed of three fatty acids and a glycerol (triglyceride) that typically exists in a solid form at room temperature
glycogen: a storage carbohydrate in animals
hormone: a chemical signaling molecule, usually a protein or steroid, secreted by an endocrine gland or group of endocrine cells; acts to control or regulate specific physiological processes
lipids: a class of macromolecules that are nonpolar and insoluble in water
macromolecule: a large molecule, often formed by polymerization of smaller monomers
monosaccharide: a single unit or monomer of carbohydrates
nucleic acid: a biological macromolecule that carries the genetic information of a cell and carries instructions for the functioning of the cell
nucleotide: a monomer of nucleic acids; contains a pentose sugar, a phosphate group, and a nitrogenous base
oil: an unsaturated fat that is a liquid at room temperature
phospholipid: a major constituent of the membranes of cells; composed of two fatty acids and a phosphate group attached to the glycerol backbone
polypeptide: a long chain of amino acids linked by peptide bonds
polysaccharide: a long chain of monosaccharides; may be branched or unbranched
protein: a biological macromolecule composed of one or more chains of amino acids
ribonucleic acid (RNA): a single-stranded polymer of nucleotides that is involved in protein synthesis
saturated fatty acid: a long-chain hydrocarbon with single covalent bonds in the carbon chain; the number of hydrogen atoms attached to the carbon skeleton is maximized
starch: a storage carbohydrate in plants
steroid: a type of lipid composed of four fused hydrocarbon rings
trans-fat: a form of unsaturated fat with the hydrogen atoms neighboring the double bond across from each other rather than on the same side of the double bond
triglyceride: a fat molecule; consists of three fatty acids linked to a glycerol molecule
unsaturated fatty acid: a long-chain hydrocarbon that has one or more than one double bonds in the hydrocarbon chain
References:
- Molnar, C. and Gair, J. (2012) 2.3 Biological Molecules Chapter in Concepts in Biology, OpenStax College Textbooks, British Comumbia. Retrieved on Dec 22nd, 2018 from: https://opentextbc.ca/biology/chapter/2-3-biological-molecules/
Reference
Ophardt, C. (2015) Carbohydrates. In Biological Chemistry. Libretexts. Available at: https://chem.libretexts.org/Core/Biological_Chemistry
Gunawardena, G. (2014) Haworth Projections. In Biological Chemistry. Libretexts. Available at: https://chem.libretexts.org/Core/Biological_Chemistry
Snell, Foster D. “Soap and glycerol.” J. Chem. Educ. 1942, 19, 172.