Another important area of research in artificial intelligence is visual processing. Visual processing involves the collection and analysis of digitized image data by computers. In this lesson, we will look at two related examples of visual processing: optical character recognition (OCR) and handwriting recognition.
Optical Character Recognition
OCR is defined by Webopedia [2000] as "the branch of computer science that involves reading text from paper and translating the images into a form that the computer can manipulate...All OCR systems include an optical scanner for reading text, and sophisticated software for analyzing images. Most OCR systems use a combination of hardware (specialized circuit boards) and software to recognize characters, although some inexpensive systems do it entirely through software. Advanced OCR systems can read text in large variety of fonts, but they still have difficulty with handwritten text". Currently OCR software can accurately recognize up to 99% of the characters in a well-printed document. While this is a very high percentage, it still leaves something to be desired when scanning long texts. Consider a typical novel of 300 pages, 40 lines per page, and 75 characters per line. Even with 99% accuracy, an OCR software package would need help 9,000 times in order to output the entire document correctly!
OCR software uses two main approaches to identifying characters: matrix matching and pattern extraction. Matrix matching is the simpler of the two since it only involves comparing the scanned data to stored templates. This approach is effective when the characters being identified are uniform in style and size. Pattern extraction involves the identification of certain features which are unique to an individual character. For example, the lower case character 't' is typified by a horizontal line crossed by a shorter vertical line. These patterns generally remain the same regardless of the size and style of the font. However, pattern extraction can be very difficult for other characters. Consider the images below showing the character 'y' in a variety of fonts. What patterns would you use to accurately describe this character?
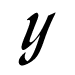
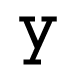
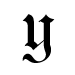

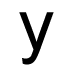
According to Decker and Hirshfield, "most OCR programs use a combination
of matrix matching and pattern extraction, using matrix matching for
monospaced typefaces such as Courier,
in which all of the characters have the same width, and pattern extraction
for proportional typefaces such as Palatino
and Helvetica"
[Decker and Hirshfield 1998]. In order to get
a feel for the effectiveness of OCR software, browse through the following
web page provided by the Electronic Text Center at the University of
Virginia [1998]. This page gives five
examples of various texts that were scanned and converted to HTML
format.
Handwriting Recognition
Some text documents cannot be converted to electronic format using OCR because they are handwritten rather than printed. In this case, handwriting recognition software can be used to convert the document. Since handwriting differs greatly among individuals, more sophisticated analysis is required to identify characters. Handwriting recognition also offers an alternative method for inputting text into a computer. Many of the current handheld computers incorporate this technology in order to avoid integrating a keyboard into the unit. While this technology is promising, it is still currently much slower than input via a keyboard. For this reason, handwriting recognition is mainly limited to computing devices for which keyboards are impractical because of their large size.
Just like the various fonts above present a challenge to OCR software, different writing styles challenge handwriting recognition software. In order to improve the accuracy of recognition, most handwriting recognition software incorporates some technique for learning an individual's style. With this method, the software compares samples of the user's writing rather than using a fixed pattern for comparison and recognition. As long as the user is fairly consistent in their writing style, this method can be very effective for recognizing individual writing styles.
To try an example of handwriting recognition software, click the button below to launch JRec, a handwriting recognition applet designed by Bob Mitchell [1998]. Then follow the instructions below to train the applet and perform some simple tests.
Instructions:
- Use the mouse to draw a character in the applet window.
- Store the character by pressing one of the label buttons (0-9). This also associates the character with the digit code on the button.
- Press "Clear" to erase your character.
- Repeat steps 1-3 for up to 10 different characters.
- Press the "Train" button to train the applet with the character set.
- Redraw one of the characters and press "Test" to recognize the character.
Since JRec is a fairly simple example of handwriting recognition, you will probably notice that it easily confuses characters with similar shapes. For example, try training the applet to recognize '5' and '6'. How often does it correctly distinguish these two digits?